使用Orange进行数据挖掘之分类(1)------朴素贝叶斯分类
基本概念
贝叶斯分类法是基于统计学的分类法。比较分类算法,该方法可以和决策树、神经网络分类相媲美。
朴素贝叶斯分类法基于数据属性之间是独立的假定。
贝叶斯定理
首先是用到的基本表达式,P(H|X)表示条件X下,H的后验概率。P(H)是表示H发生的先验概率。贝叶斯定理是:
P(H|X)=P(X|H)P(H)/P(X)
朴素贝叶斯分类
设D是用于训练的数据集,包含类标号。
假设共有n个类C1,C2,C3,......Cn。现有元素X,分类法找到X属于具有最高概率的类。就是说X属于类Ci,并且P(Ci|X)>P(Cj|X)。
Orange中的朴素贝叶斯
以iris数据集为例,在Orange简单实用朴素贝叶斯的方法如下:
import Orange
#加载数据
iris= Orange.data.Table("iris")
learner = Orange.classification.bayes.NaiveLearner()
#训练数据
classifier = learner(iris)
#验证结果
for inst in iris[:10]:
print inst.getclass(), classifier(inst)
运行结果如下:
Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa
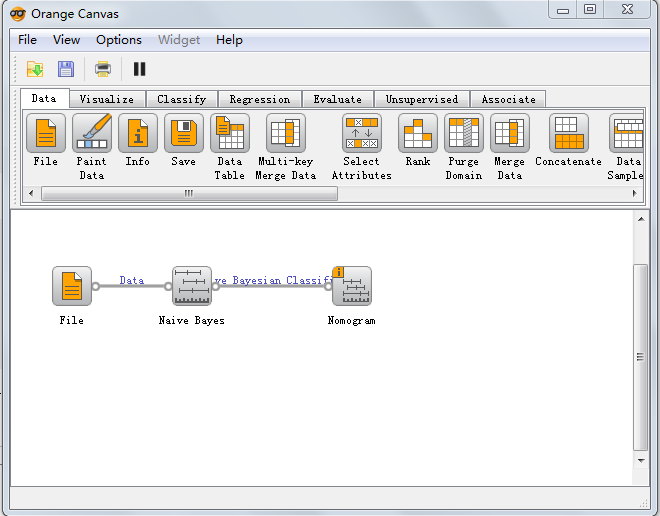
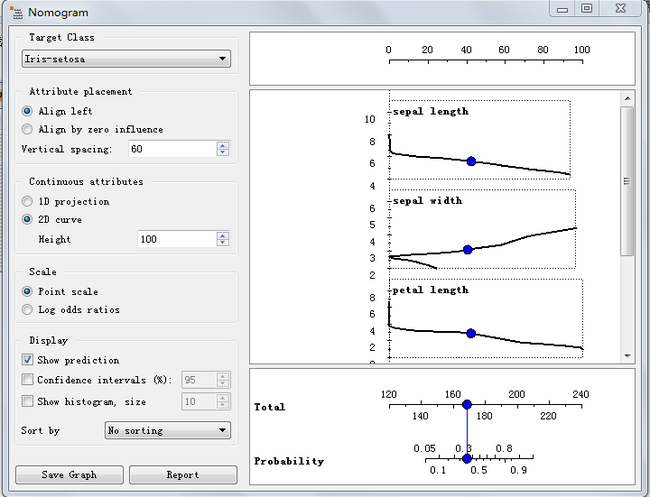
同时可以借助Orange的widget,进行可视化方法的朴素贝叶斯分类。仍然以iris数据为例:
参考资料
数据挖掘导论 http://book.douban.com/subject/5377669/