CPL7用户指南(中文版)_第二章 CPL7 用户指南
2.1 综述(General Overview )
通用地球系统模型(Community Earth System Model
)的发行版本V1.0 较之前的CCSM4 版本有许多明显改变。尤其是CESM1 不会运行,由于多个可执行文件(multiple executables )在一个并行的只有处理器布局里面 。通过标准的初始化(init )、运行(run )和终结(finalize )方法,目前有一个顶层驱动和多个组件被调用。组件能够有序地、并行地或有序-并行交叉地运行在处理器上。耦合器组件——运行于总处理器子集上的——作为驱动的一部分仍然存在于系统里面。驱动器运行于所有处理器上,耦合器函数(映射(mapping )、合并(merging )、通量计算(flux calculation )和诊断(diagnostic ))则运行于用户定制的总处理器的子集上。处理器布局通过名字列表项(namelist input )在运行时(at runtime )被指定。
虽然处理器布局具有一定的弹性,并且组件能够有序或并行运行,但在驱动器里的science 序列却被固定并且独立于处理器布局。因此改变处理器布局仅会改变模拟系统的表现层(performance )。
像CESM 中的所有组件一样,建立驱动器脚本系统是为了使组件模板文件(位于/models/drv/bld/cpl.template 文件夹下)可被CESM 配置脚本文件运行,并且驱动器脚本系统可生成部分性的被解析的 cpl.buildnml.csh 和 cpl.buildexe.csh 脚本。CESM 配置脚本文件也会生成 case 、.build 、.run 和.clean_build 脚本。用户查阅《CESMV1.0.3 用户指南》可以得到关于这个处理过程的更为详尽信息。恩,简言之,这个处理过程如下:
-运行 ./create_newcase 命令来生成一个实例目录。
-编辑 env_conf.xml 和 env_mach_pes.xml 文件,然后运行 ./configure -case 命令。This runs the coupler cpl.template file among other things. 配置脚本文件会生成 .build 、.run 和.clean_build 脚本,并且在Buildconf 目录中能够生成部分性被解析的buildnml 和buildexe 脚本。
-编辑 env_build.xml 文件,运行 .build 脚本。
-编辑 env_run.xml 文件,运行 .run 脚本。
2.2 设计讨论( Design Discussion )
2.2.1 概述(Overview )
CESM1/CPL7 目前被设计为一个单独的可执行文件,它仅含有一个单独的顶层驱动器。这个驱动器运行于所有处理器上,并且能够处理耦合器序列,模型并发性,以及组件之间的数据通讯。这个驱动器通过简单、标准的借口来调用所有的模型组件。驱动器也会直接调用耦合器方法来执行诸如映射/ 插值(mapping/interpolation )、重排序(rearranging )、合并(merging )、大气/ 海洋通量计算(flux calculation )和诊断(diagnostics )等操作。在CESM1 中,模型组件和耦合器方法都能在总处理器的子集上运行。CPL7 包含了一个驱动器,这个驱动器能够控制顶层级别序列,处理器分解任务和组件间通讯(通过subroutine calls 来进行)。当耦合器操作(比如映射(mapping )、合并(merging )等)在驱动器(位于处理器的子集上)下运行的时候,貌似有一个单独的耦合器模型组件。
CESM1 包含数据模型和活跃组件模型。总的来说,每个活跃组件需要数据源,并提供数据给耦合器,尽管数据模型通常从I/O 读入数据,然后刚好提供数据给耦合器。在CESM1 中,如同在CCSM3 中,大气、陆地、海冰模型总是耦合紧密以更好地处理日循环(diurnal cycle )。这种耦合属于典型的半小时(half -hourly )型,虽然分辨率较高,但耦合较为频繁。海洋模型耦合属于典型的每天一次或多次(once or a few times )型。日循环的海洋表面反射率(albedo )在耦合器中通过大气模型被计算。松散的海洋耦合频数意味着海洋forcing hand response 在系统中是滞后的。在CESM1 中有一个选项可用来无任何滞后性地运行紧密耦合后的海洋模块,但是这通常在仅当用数据来运行海洋组件时使用。
考虑到分辨率、硬件、运行时长和物理因素,CESM1 运行完成时间从几个小时到几个月不等。Runs are typically decades or centuries long, and the model typically runs between 1 and 50 model years per wall clock day.CESM1 has exact restart capability and the model is typically run in individual one year or multi-year chunks. CESM1 具有自动的任务重提交和数据存档能力。
2.2.2 序列和并发(Sequencing and Concurrency )
在CESM1 中,组件处理器布局和MPI 通讯来源于名字列表项(namelist input )。目前在CESM 中有7 个基本的处理器组群。这些是与之相关的大气(atmosphere )、陆地(land )、海洋(ocean )、海冰(sea ice )、陆冰(land ice )、耦合器(coupler )和全局组(global groups ),although others could be easily added later . 这7 个处理器组群中的每一个都是显示的(distinct ),但那并非是系统的要求。用户可以相对任意地交叠处理器组群。如果在至少一个处理器里,所有处理过程设置为overlap ,模型将按序列运行。如果所有处理过程设置为distinct ,模型将并发运行。对于每个组件组的处理过程设置目前可用三个基本的标量参数来描述:mpi 任务数量、在每个mpi 任务中的openmp 线程数量、针对那个组的根mpi 任务的global mpi 任务列。例如有这样一个布局:mpi 任务数为8 ,每个mpi 任务的线程数为4 ,根mpi 任务数为16 。这个布局将会产生一个包含32 个硬件处理器的处理过程组群。它始于16 个global mpi 任务,将包含8 个mpi 任务。全局组群将包含至少24 个任务和至少48 个硬件处理器。驱动器在初始化时运行所有的MPI 通讯,并将传递MPI 给组件模型。
如上所述,对于组件模型是否并发运行存在两个争论。其一为工作块(chunk of work )是否在处理器设置为distinct 时运行,其二为驱动器里的工作序列。CESM1 驱动器序列尽量被实现为:在不同组件间最大化那些工作并发性的潜力数量。理想状态下,in a single coupling step, 模型的forcing 将被首先计算,然后模型开始并发运行,接着驱动器将会继续前进。 然而,棘手的科学问题,比如在CESM1 中求表面反射率坐标、大气辐射计算以及普通的稳定性计算等,阻止了这个理想实现。Fig.1 显示了对于fully active system 来说,可被当前CESM1 驱动器实现支持的并发性最大数量。实际上,科学限制意味着活跃性的大气模型不会和陆地模型、海冰模型并发运行。
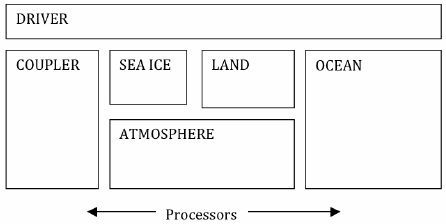
Fig.1 Maximum potential processor concurrency designed into CESM1 to support scientific requirements and stability.
2.2.3 组件接口(Component Interfaces )
标准的 CESM1 组件模型接口基于 ESMF 设计,每个组件会提供 init 、 run 和 finalize 方法。 CESM1 组件接口参数( argument )目前包含 Fortran 和 MCT 数据类型,但是可选择的 ESMF 版本还是比较多的。在 init 、 fun 和 finalize 阶段,物理耦合场( physical coupling fields )通过接口被传递。作为初始化一部分, MPI 通讯从驱动器被传递到组件,而栅格和分解信息则从组件被传递回到驱动器。驱动器 / 耦合器要求在运行时或来自名字列表( namelist )或来自组件间通讯的关于分辨率、配置项和处理器布局的所有信息。
CESM1 的系统初始化相对来说直截了当。首先,这 7 个 MPI 通讯器在驱动器中耦合。然后,大气、陆地、海洋、海冰和陆冰模型的初始化方法会在匹配的处理器集合上被调用, mpi 通信被发送, 栅格和分解信息被传递回驱动器。一旦,驱动器收到了所有的来自组件的栅格和分解信息,各式各样的重组和映射( rearranger and mapper )将被初始化。初始化过程会在在处理器、分解器和栅格之间移出数据。在耦合器实现里面对于序列和并发执行来说并没有明显的差别。总之,即便对于实例——两个组件有相同的栅格和处理器布局,通常来说在表现层方面它们的分解器各异。即使组件间的栅格、分解器和处理器布局相同,映射和重组操作将会退化为一个本地数据拷贝( local data copy )。
针对组件 run 方法的接口包含了 two distinct bundles of fields 。 One is the data sent to force the model. 另一个是接收自为耦合其他组件的模型的数据。对于模型来说 , run 接口也包含一个时钟,用于指定当前时间和运行时长( run length )。这些接口遵循 ESMF 设计准则。
2.2.4 模型耦合工具包(MCT ,The Model Coupling Toolkit )
MCT 在 CCSM3 CPL6 耦合器中是一个标准的软件部件。在升级后的 CESM CPL7 耦合器中,
MCT 的 attribute_vector, global_segmap, and general_grid 数据类型在顶层驱动器上被采用, 并且它们直接用于组件的 init 、 run 和 finalize 接口。此外, MCT 也用于所有数据的重组和映射 / 插值( rearranging and mapping (interpolation) )。在驱动器层被 CESM 使用的时钟基于 ESMF 规范。 通过使用 SCRIP 包作为一个预处理过程,离线( off - line )状态下,映射权重仍可被生成。 它们(映射权重)通过使用子路径( subroutine )被读入 CESM1 , 子路径可用于在合理的小块内读和分发映射权重到最小化内存足迹( memory footprint )。 CESM1 CPL7 耦合器的开发不仅依赖于 MCT ,而且依赖于 MCT 开发者们,因为他们对 CPL7 驱动器的设计和实现作出了重大贡献。无论是 CPL6 还是 CPL7 耦合器的开发都源自 NCAR 和 DEA 国家实验室的强有力、紧密合作。
2.2.5 内存、并行IO 和表现(Memory, Parallel IO, and Performance )
相比之前任何的 CCSM 耦合的模型 , CESM1 目的在于具备更高的分辨率。在这个尺度上,为了便于科学的气候模型探索和开发,技术首先需要被落实,以此来测试实例。为了在所有组件内降低内存足迹( memory footprint ),和改善内存缩放比例( memory scaling ),付出了诸多努力。其目的是能够在全球数万个处理器上运行全部耦合后的系统 (采用 0.1 度的分辨率),每个处理器至少有 512M 内存。这个目标限制了全局数组( globe array )的数量, 这些全局数组可被分配到任一处理器上 。 The memory limitations have imposed new constraints on component model initialization, and significant refactoring has been required in some models’ initialitialization to reduce the amount of global memory used. In addition, all components have implemented I/O that supports reading and writing of only one(1) global horizontal array at a time through a master processor.
PIO—— 一个基于 netcdf 、 pnetcdf 和 MPI IO 的并行 I/O 库——的开发,在 CESM 社区中稳步发展,以改善模型中的 I/O 表现和内存使用。大部分模型组件目前都在使用 PIO 软件来处理 I/O ,且使用 PIO 允许 CESM1 的测试处于一种高分辨率模式,这在之前由于内存而受限。
Scaling to tens-of-thousands of processors requires reasonable performance scaling of the models, and all components have worked at improving scaling via changes to algorithms, infrastructure, or decompositions. 尤其是,使用共享内存块的分解器、填充曲线的空间以及所有的三维空间被实现为,在所有组件里,来增加并行能力和 improve scalability 。
在实际中, CESM1 表现层( performance )、装载平衡( load balance )和可测量性( scalability )被作为系统的大小、复杂度和多种模型特征而被限制。在这个系统中,每个组件都拥有 scaling 特征。尤其是,每个组件具有 processor count "sweet-spots" ,单独组件模型表现特别好。由于内部装载、分解能力、通信模式或缓存应用,这种状况可能会在组件内部发生。 Second, component performance can vary over the length of the model run. 考虑到模型中物理成本的季节变化;在调整阶段中的表现层改变;在调用某些模型操作(如 radiation 、 dynamics, or I/O )时的临时变化,这种状况可能会发生。第三点,硬件或batch 队列系统可能在可用的处理器的总数量上具有某些限制。比如,在 16 或 32 way 共享内存节点上,用户通常基于节点用途被管理( be charged ),而非处理器用途。出于所有的这些问题的考虑, CESM1 装载平衡通常来说不太可能实现。 但是从一个大尺度来说,如果能够接受限制,带有接受闲置时间的装载平衡配置器和合理的吞吐量是有可能进行配置的。 CESM1 已明显增强了可用处理器布局的弹性,且通常来说已导致了更好的装载平衡配置器。
CESM1 装载平衡要求进行一系列的考虑,比如哪个组件在运行,它们的绝对分辨率如何,它们的相对分辨率如何;成本, scaling and processor count sweet-spots for each component; 组件中内部装载不平衡。 It is often best to load balance the system with all significant run-time I/O turned off because this occurs very infrequently (typically one time stepper month in CESM1), is best treated as a separate cost, and can bias interpretation of the overall model load balance. 在某些个或所有的系统中应用 OpenMP 线程依赖于硬件 / 操作系统的支持以及对于不同组件来说,是否系统支持运行所有的 MPI 和混合的 MPI/OpenMP 在叠置处理器上。最后,组件应当有序、并发、或两者的结合方式来运行。 Typically, a series of short test runs is done with the desired production configuration to establish a reasonable load balance setup for the production job. CESM1 提供了某些关于表现层、系统装载平衡的 post - run 分析,以用来帮助用户改善处理器布局。