数据挖掘算法之离散化和二元化
离散化和二元化
有些数据挖掘算法,特别是某些分类算法,要求数据是分类属性形式。发现关联模式的算法要求数据是二元属性形式。这样,常常需要将连续属性变换成分类属性(离散化,discretization),并且连续和离散属性可能都需要变换成一个或多个二元属性(二元化,binarization)。此外,如果一个分类属性具有大量不同值(类别),或者某些值出现不频繁,则对于某些数据挖掘任务,通过合并某些值减少类别的数目可能是有益的。
与特征选择一样,最佳的离散化和二元化方法是"对于用来分析数据的数据挖掘算法,产生最好结果"的方法。直接使用这种判别标准通常是不实际的。因此,离散化和二元化一般要满足这样一种判别标准,它与所考虑的数据挖掘任务的性能好坏直接相关。
1. 二元化
一种分类属性二元化的简单技术如下:如果有m个分类值,则将每个原始值唯一地赋予区间[0, m 1]中的一个整数。如果属性是有序的,则赋值必须保持序关系。(注意,即使属性原来就用整数表示,但如果这些整数不在区间[0, m 1]中,则该过程也是必需的。)然后,将这m个整数的每一个都变换成一个二进制数。由于需要n = log2m 个二进位表示这些整数,因此要使用n个二元属性表示这些二进制数。例如,一个具有5个值{awful, poor, OK, good, great}的分类变量需要三个二元变量x1、x2、x3。转换见表2-5。
表2-5 一个分类属性到三个二元属性的变换
| 分类值 |
整数值 |
x1 |
x2 |
x3 |
| awful poor OK good great |
0 1 2 3 4 |
0 0 0 0 1 |
0 0 1 1 0 |
0 1 0 1 0 |
这样的变换可能导致复杂化,如无意之中建立了转换后的属性之间的联系。例如,在表2-5中,属性x2和x3是相关的,因为good值使用这两个属性表示。此外,关联分析需要非对称的二元属性,其中只有属性的出现(值为1)才是重要的。因此,对于关联问题,需要为每一个分类值引入一个二元属性,如表2-6所示。如果结果属性的个数太多,则可以在二元化之前使用下面介绍的技术减少分类值的个数。
表2-6 一个分类属性到五个非对称二元属性的转换
| 分类值 |
整数值 |
x1 |
x2 |
x3 |
x4 |
x5 |
| awful poor OK good great |
0 1 2 3 4 |
1 0 0 0 0 |
0 1 0 0 0 |
0 0 1 0 0 |
0 0 0 1 0 |
0 0 0 0 1 |
同样,对于关联问题,可能需要用两个非对称的二元属性替换单个二元属性。考虑记录人的性别(男、女)的二元属性,对于传统的关联规则算法,该信息需要转换成两个非对称的二元属性,其中一个仅当是男性时为1,而另一个仅当是女性时为1。(对于非对称的二元属性,由于其提供一个二进制位信息需要占用存储器的两个二进制位,因而在信息的表示上不太有效。)
2. 连续属性离散化
通常,离散化应用于在分类或关联分析中使用到的属性上。一般来说,离散化的效果取决于所使用的算法,以及用到的其他属性。然而,属性离散化通常单独考虑。
连续属性变换成分类属性涉及两个子任务:决定需要多少个分类值,以及确定如何将连续属性值映射到这些分类值。在第一步中,将连续属性值排序后,通过指定n 1个分割点(split point)把它们分成n个区间。在颇为平凡的第二步中,将一个区间中的所有值映射到相同的分类值。因此,离散化问题就是决定选择多少个分割点和确定分割点位置的问题。结果可以用区间集合{(x0, x1], (x1, x2],..., (xn-1, xn)}表示,其中x0和xn可以分别为- 或+ ,或者用一系列不等式x0 < x≤x1,..., xn-1 < x < xn表示。
非监督离散化 用于分类的离散化方法之间的根本区别在于使用类信息(监督,supervised)还是不使用类信息(非监督,unsupervised)。如果不使用类信息,则常使用一些相对简单的方法。例如,等宽(equal width)方法将属性的值域划分成具有相同宽度的区间,而区间的个数由用户指定。这种方法可能受离群点的影响而性能不佳,因此等频率(equal frequncy)或等深(equal depth)方法通常更为可取。等频率方法试图将相同数量的对象放进每个区间。作为非监督离散化的另一个例子,可以使用诸如K均值(见第8章)等聚类方法。最后,目测检查数据有时也可能是一种有效的方法。
例2.12 离散化技术 本例解释如何对实际数据集使用这些技术。图2-13a显示了属于四个不同组的数据点,以及两个离群点--位于两边的大点。可以使用上述技术将这些数据点的x值离散化成四个分类值。(数据集中的点具有随机的y分量,可以更容易地看出每组有多少个点。)尽管目测检查该数据的方法效果很好,但不是自动的,因此我们主要讨论其他三种方法。使用等宽、等频率和K均值技术产生的分割点分别如图2-13b、图2-13c和图2-13d所示,图中分割点用虚线表示。如果我们用不同组的不同对象被指派到相同分类值的程度来度量离散化技术的性能,则K均值性能最好,其次是等频率,最后是等宽。
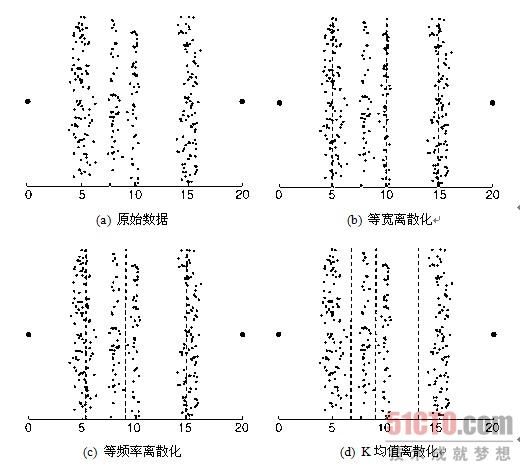 |
| (点击查看大图)图2-13 不同的离散化技术 |
监督离散化 上面介绍的离散化方法通常比不离散化好,但是记住最终目的并使用附加的信息(类标号)常常能够产生更好的结果。这并不奇怪,因为未使用类标号知识所构造的区间常常包含混合的类标号。一种概念上的简单方法是以极大化区间纯度的方式确定分割点。然而,实践中这种方法可能需要人为确定区间的纯度和最小的区间大小。为了解决这一问题,一些基于统计学的方法用每个属性值来分隔区间,并通过合并类似于根据统计检验得出的相邻区间来创建较大的区间。基于熵的方法是最有前途的离散化方法之一,我们将给出一种简单的基于熵的方法。
首先,需要定义熵(entropy)。设k是不同的类标号数,mi是某划分的第i个区间中值的个数,而mij是区间i中类j的值的个数。第i个区间的熵ei由如下等式给出
 |
其中,![]() 是第i个区间中类j的概率(值的比例)。该划分的总熵e是每个区间的熵的加权平均,即
是第i个区间中类j的概率(值的比例)。该划分的总熵e是每个区间的熵的加权平均,即
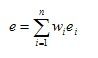 |
其中,m是值的个数,wi = mi/m是第i个区间的值的比例,而n 是区间个数。直观上,区间的熵是区间纯度的度量。如果一个区间只包含一个类的值(该区间非常纯),则其熵为0并且不影响总熵。如果一个区间中的值类出现的频率相等(该区间尽可能不纯),则其熵最大。
一种划分连续属性的简单方法是:开始,将初始值切分成两部分,让两个结果区间产生最小熵。该技术只需要把每个值看作可能的分割点即可,因为假定区间包含有序值的集合。然后,取一个区间,通常选取具有最大熵的区间,重复此分割过程,直到区间的个数达到用户指定的个数,或者满足终止条件。
例2.13 两个属性离散化 该方法用来独立地离散化图2-14所示的二维数据的属性x和y。在图2-14a所示的第一个离散化中,属性x和y被划分成三个区间。(虚线指示分割点。)在图2-14b所示的第二个离散化中,属性x和y被划分成五个区间。
 |
| (点击查看大图)图2-14 离散化四个点组(类)的属性x和y |
这个简单的例子解释了离散化的两个特点。首先,在二维中,点类是很好分开的,但在一维中,情况并非如此。一般而言,分别离散化每个属性通常只保证次最优的结果。其次,五个区间比三个好,但是,至少从熵的角度看,六个区间对离散化的改善不大。(没有给出六个区间的熵值和结果。)因而需要有一个终止标准,自动地发现划分的正确个数。
3. 具有过多值的分类属性
分类属性有时可能具有过多的值。如果分类属性是序数属性,则可以使用类似于处理连续属性的技术,以减少分类值的个数。然而,如果分类属性是标称的,就需要使用其他方法。考虑一所大学,它有许多系,因而系名属性可能具有数十个不同的值。在这种情况下,我们可以使用系之间联系的知识,将系合并成较大的组,如工程学、社会科学或生物科学。如果领域知识不能提供有用的指导,或者这样的方法会导致很差的分类性能,则需要使用更为经验性的方法,如仅当分组结果能提高分类准确率或达到某种其他数据挖掘目标时,才将值聚集到一起。