关于Java中尾递归的优化
最近总有人问我,Java SE8里有没有针对尾调用做优化(这是一种特殊的函数调用)。这个优化和递归调用密切相关,而递归调用对函数式语言来说尤其重要,因为它们通常都基于递归来进行设计编码。本文会介绍到什么是尾调用,怎样可以对它进行有效的优化,以及Java 8在这方面是如何做的。
在深入这个话题之前,我们先来了解下什么是尾调用。
什么是尾调用?
尾调用指的是一个方法或者函数的调用在另一个方法或者函数的最后一条指令中进行(为了简单,后面我就都称作函数调用了)。Andrew Koenig在他的 博客中有关于这个话题的介绍。下面定义了一个foo()函数作为例子:
int foo(int a) {
a = a + 1;
return func(a);
}
func()函数的调用是foo()函数的最后一条语句,因此这是一个尾调用。如果在调用了func()之后,foo()函数还执行了别的指令才返回的话,那么func()就不再是一次尾调用了。
你可能在想这些语义有什么意义。如果尾调用不是一个递归的函数调用的话,这些概念确实不重要。比如:
int fact(int i, int acc) {
if ( i == 0 )
return acc;
else
return fact( i – 1, acc * i);
}
int factorial(int n) {
if ( n == 0 )
return 1;
else
return fact( n – 1, 1 );
}
下图中有fact()对应的汇编代码,就在C代码的右边。红色的箭头指向的是fact()函数的最后两条指令,一条是调用fact()自己,一个是return语句对应的MOV指令。这符合尾调用的定义。
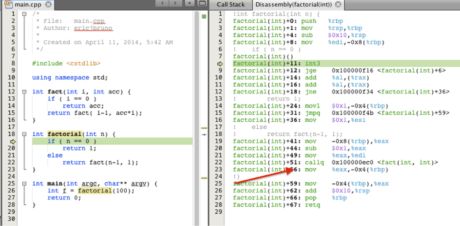
尽管我用的是C代码来介绍这个,但其实在Java里也是一样的。事实上,你可以把这段代码拷贝到Java类里,它也能通过编译并正常工作。那么到底有什么可以优化的呢?
尾调用的优化
任何的尾调用,不只是尾递归,函数调用本身都可以被优化掉,变得跟goto操作一样。这就意味着,在函数调用前先把栈给设置好,调用完成后再恢复栈的这个操作(分别是prolog和epilog)可以被优化掉。比如说下面的这段代码:
int func_a(int data) {
data = do_this(data);
return do_that(data);
}
函数do_that()是一个尾调用。没有优化过的汇编代码看起来大概是这样的:
... ! executing inside func_a() push EIP ! push current instruction pointer on stack push data ! push variable 'data' on the stack jmp do_this ! call do_this() by jumping to its address ... ! executing inside do_this() push EIP ! push current instruction pointer on stack push data ! push variable 'data' on the stack jmp do_that ! call do_that() by jumping to its address ... ! executing inside do_that() pop data ! prepare to return value of 'data' pop EIP ! return to do_this() pop data ! prepare to return value of 'data' pop EIP ! return to func_a() pop data ! prepare to return value of 'data' pop EIP ! return to func_a() caller ...
注意到对于数据以及EIP寄存器(用来返回数据并且恢复指令指针),POP指令被连续执行了多次。可以通过一个简单的JMP指令将一组关联的epilog和prolog操作(将数据和EIP进行压栈)优化掉。这是因为do_that()函数会替func_a函数执行这段epilog代码。
这个优化是安全的,因为func_a函数在do_that()返回后就不再执行别的指令了。(注意:如果要对do_that()返回的值进行处理的话,就不能执行这个优化,因为do_that()就不再是一个尾调用了)。
下面是尾调用优化后的结果:
... ! executing inside func_a() push EIP ! push current instruction pointer on stack push data ! push variable 'data' on the stack jmp do_this ! call do_this() by jumping to its address ... ! executing inside do_this() push EIP ! push current instruction pointer on stack push data ! push variable 'data' on the stack jmp do_that ! call do_that() by jumping to its address ... ! executing inside do_that() pop data ! prepare to return value of 'data' pop EIP ! return to do_this() pop data ! prepare to return value of 'data' pop EIP ! return to func_a() caller pop data ! prepare to return value of 'data' pop EIP ! return to func_a() caller...
看起来稍微有点不同,这是优化前的代码:
| int func_a(int data) { | |
| data = do_this(data); | push EIP ! prolog<br>push data ! prolog<br>jmp do_this ! call<br>...<br>pop data ! epilog<br>pop EIP ! epilog |
| return do_that(data); | push EIP ! prolog<br>push data ! prolog<br>jmp do_that! call<br>...<br>pop data ! epilog<br>pop EIP ! epilog |
| } | pop data ! epilog<br>pop EIP ! epilog |
这是优化后的:
| int func_a(int data) { | |
| data = do_this(data); | push EIP ! prolog<br>push data ! prolog<br>jmp do_this ! call<br>...<br>pop data ! epilog<br>pop EIP ! epilog |
| return do_that(data); | jmp do_that ! goto... |
| } | pop data ! epilogpop EIP ! epilog |
比较一下第三行,你就可以看到节省了多少行机器代码。当然光这个而言并不能代表这个优化的真正价值。如果和递归结合到一起的话,这个优化的价值就显现出来了。
如果你再看下上面的那个递归的阶乘函数,你会发现如果使用了这个优化的话,所有原来不断重复的prolog和epilog汇编代码现在都消失了。最终把下面的递归伪代码:
call factorial(3)
call fact(3,1)
call fact(2,3)
call fact(1 6)
call fact(0,6)
return 6
return 6
return 6
return 6
return 6
变成这个迭代式的伪代码:
call factorial(3) call fact(3,1) update variables with (2,3) update variables with (1,6) update variables with (0,6) return 6 return 6
也就是说,它用一个循环替换掉了递归,大多数C/C++,Java程序员也正是这么干的。这个优化不止是减少了大量的递归函数调用带来的prolog和epilog,它还极大的减轻了栈的压力。不作这个优化的话,计算一个很大的数的阶乘很可能会让栈溢出——也就是,用光了所有分配给栈的内存。把代码优化成循环后就消除了这个问题。由于函数式语言的开发人员经常使用递归,所以大多数函数式语言的解释器都会进行尾调用的优化。
Java是怎么做的?
正如我前面提到的,Java程序员一般都使用循环,而尽量不用递归。比如,下面是一个迭代式的阶乘的实现:
int factorial(int n) {
int result = 1;
for (int t=n; t > 1; t--)
result *= t;
return result;
}
因此对大多数Java开发人员来说,Java不进行尾调用优化并不是什么大问题。不过我猜或许很多Java程序员都没有听说过尾调用优化这回事。不过当你在JVM上运行函数式语言的话,这就成为一个问题了。递归的代码在自己语言的解释器里运行得好好的,可能一到JVM上就突然把栈给用完了。
值得注意的是,这并不是JVM的BUG。这个优化对经常使用递归的函数式语言的开发人员来说非常有用。我最近经常和Oracle的Brian Goetz提到这个优化,他总是说这个在JVM的开发计划表上,不过这不是一个优先级特别高的事。就目前来说,你最好自己去做优化,当你使用函数式语言在JVM上进行开发的时候,尽管避免使用过深的递归调用。
原创文章转载请注明出处: http://it.deepinmind.com
英文原文链接