互联网相似图像识别检索引擎 —— 基于图像签名的方式
一、引言
多媒体识别是信息检索中难度较高且需求日益旺盛的一个问题。以图像为例,按照图像检索中使用的信息区分,图像可以分为两类:基于文本的图像检索和基于内容识别的图像检索(CBIR:Content Based Image Retrieval)。基于文本的图像检索完全不分析和利用图像本身的内容,其检索质量完全依赖于与图像关联的文字信息与图像内容的相关性,因此有必要引入基于内容的图像检索。本为主要讨论后者。
在计算机视觉中,图像内容通常用图像特征进行描述。事实上,基于计算机视觉的图像检索也可以分为类似文本搜索引擎的三个步骤:提取特征、建索引build以及查询。本文也按照这三步来分别阐述。
二、图像特征的提取
目前互联网上的图像识别可以归结为两类问题,其一是“近重复检索”,主要是针对同一源图经过不同形变(包括光照、水印、缩放、局部缺失替换等)的检索,或是针对大体类似的物件进行识别,主要应用在版权保护、违禁识别、图片去重以及基本的相似检索等等;其二是“局部检索”,指的是两张图片中只要有部分物件重复,即可匹配到,比如我们可以想象,不同offer的模特不一样,但只要她们都跨了同一款LV包,就可以认为是相似图像,即实现真正意义上的图像检索。
与此相对应的,图像特征也可以分成两类:全局特征与局部特征。大部分图像签名算法都是利用图像的全局特征来描述一幅图像的内容,例如,颜色直方图、色彩分布、形状或者边缘信息等等,用一个字符串或是数组来作为一幅图像的hash值。
总的来说,全局特征是对图像内容高度抽象的概括,只回答了“图像是什么”,而大多数场合以用户的视角来看,更希望回答“图像有什么”。例如,用户在检索图像时,经常更加关心的是图像中的场景、物体或者特定的任务,单单一个全局特征无法区分些信息,因此引入了局部特征。其中最为著名的就是“基于尺度不变特征变换的图像检索”,Scale Invariant Feature Transform,也就是大名鼎鼎的SIFT。其基本思想是将图像打散为许多高维特征点,因此将互联网上的图片已视觉词库的形式加以保存。由于SIFT特征在描述向量时不受尺度变换和旋转的影响,对图像噪音、仿射变形、光照变化以及三维视角皆不敏感,因此具有极强的区分度,被广泛应用于物体识别、视频追踪、场景识别、图像检索等问题。
为简单起见,本文主要讨论基于全局特征的图像相似检索技术,而局部特征可以在此基础上自行加以扩展。
MPEG(即Moving Picture Experts Group运动图像专家小组)是个国际标准,即所谓ISO11172。准确说来, MPEG-7 并不是一种压缩编码方法,而是一个多媒体内容描述接口。继 MPEG-4 之后,要解决的矛盾就是对日渐庞大的图像、声音信息的管理和迅速搜索。MPEG7就是针对这个矛盾的解决方案。MPEG-7 力求能够快速且有效地搜索出用户所需的不同类型的多媒体影像资料,比如在影像资料中搜索有长江三峡镜头的片段。预计这个方案于2001年初最终完成并公布。虽然没有实现代码,MPEG-7公布了一些图像描述接口,制定了一些诸如颜色分布、纹理、边缘、主体颜色的标准。这里主要介绍一下后边使用到的边缘直方图描述算法的原理。计算边缘直方图的主要步骤如下:

三、图像特征索引的build与基于图像的query
在海量(百万以上)的图像特征中,寻找亚线性时间复杂度的匹配算法是十分有挑战的,特别的,由于是近似检索,我们需要的是数字上的非精确匹配,让我们看一下能想到的方法:
LSH主要是用来解决多维向量的K近邻(K Nearst Neighgor)问题,即查找某一多维向量间的K个最相似的向量。这是一种概率算法,其原理类似于bloom filter,存在一定的false positive,但换来的是检索效率的飞跃提升。
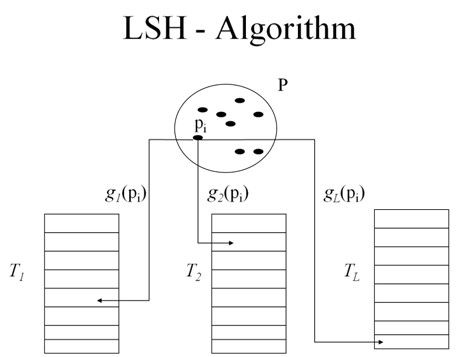
LSH的主要原理是:建立L个散列表来存放索引,每一个散列表Ti包含M个存放数据的桶,另外提供两套函数族Gi与Hi与之相关联。局部敏感哈希算法在概率意义上将相近的向量映射到相同的桶当中去,利用该特质可以对图像特征进行非精确匹配。为了最大限度的避免概率上的失误,采用多个hash函数映射到不同的hash表中去,分散误差,如图二所示。
 利用LSH为图像特征建立索引的具体流程如下:
利用LSH为图像特征建立索引的具体流程如下:
局部敏感哈希将多维近似检索的时间复杂度进一步降低到亚线性级别,同时,合理选择哈希函数的个数与种类又可以使检索的准确率和召回率达到平衡。
四、实验结果
为验证MPEG-7边缘直方图配合局部敏感哈希算法的结果,本文使用了隐网项目中的违禁数据库进行测试。测试环境为公司的Dell PC,测试条件如下所示:
样本库数量:14085
样本类别:国家安全类、文化传媒类、限售、药物器械
持久化index文件容量:3.07MB
从图片build时间:406ms
从索引文件build时间:15min
query时间:0ms
测试效果范例:
输入的待检索图片:

Query得到相似图片结果:

五、后续工作
1、sift特征的引入,局部图像检索的实现
2、lsh算法,参数的自动优化
3、百万级数据测试
4、不同场景、类别下策略的分析
多媒体识别是信息检索中难度较高且需求日益旺盛的一个问题。以图像为例,按照图像检索中使用的信息区分,图像可以分为两类:基于文本的图像检索和基于内容识别的图像检索(CBIR:Content Based Image Retrieval)。基于文本的图像检索完全不分析和利用图像本身的内容,其检索质量完全依赖于与图像关联的文字信息与图像内容的相关性,因此有必要引入基于内容的图像检索。本为主要讨论后者。
在计算机视觉中,图像内容通常用图像特征进行描述。事实上,基于计算机视觉的图像检索也可以分为类似文本搜索引擎的三个步骤:提取特征、建索引build以及查询。本文也按照这三步来分别阐述。
二、图像特征的提取
目前互联网上的图像识别可以归结为两类问题,其一是“近重复检索”,主要是针对同一源图经过不同形变(包括光照、水印、缩放、局部缺失替换等)的检索,或是针对大体类似的物件进行识别,主要应用在版权保护、违禁识别、图片去重以及基本的相似检索等等;其二是“局部检索”,指的是两张图片中只要有部分物件重复,即可匹配到,比如我们可以想象,不同offer的模特不一样,但只要她们都跨了同一款LV包,就可以认为是相似图像,即实现真正意义上的图像检索。
与此相对应的,图像特征也可以分成两类:全局特征与局部特征。大部分图像签名算法都是利用图像的全局特征来描述一幅图像的内容,例如,颜色直方图、色彩分布、形状或者边缘信息等等,用一个字符串或是数组来作为一幅图像的hash值。
总的来说,全局特征是对图像内容高度抽象的概括,只回答了“图像是什么”,而大多数场合以用户的视角来看,更希望回答“图像有什么”。例如,用户在检索图像时,经常更加关心的是图像中的场景、物体或者特定的任务,单单一个全局特征无法区分些信息,因此引入了局部特征。其中最为著名的就是“基于尺度不变特征变换的图像检索”,Scale Invariant Feature Transform,也就是大名鼎鼎的SIFT。其基本思想是将图像打散为许多高维特征点,因此将互联网上的图片已视觉词库的形式加以保存。由于SIFT特征在描述向量时不受尺度变换和旋转的影响,对图像噪音、仿射变形、光照变化以及三维视角皆不敏感,因此具有极强的区分度,被广泛应用于物体识别、视频追踪、场景识别、图像检索等问题。
为简单起见,本文主要讨论基于全局特征的图像相似检索技术,而局部特征可以在此基础上自行加以扩展。
MPEG(即Moving Picture Experts Group运动图像专家小组)是个国际标准,即所谓ISO11172。准确说来, MPEG-7 并不是一种压缩编码方法,而是一个多媒体内容描述接口。继 MPEG-4 之后,要解决的矛盾就是对日渐庞大的图像、声音信息的管理和迅速搜索。MPEG7就是针对这个矛盾的解决方案。MPEG-7 力求能够快速且有效地搜索出用户所需的不同类型的多媒体影像资料,比如在影像资料中搜索有长江三峡镜头的片段。预计这个方案于2001年初最终完成并公布。虽然没有实现代码,MPEG-7公布了一些图像描述接口,制定了一些诸如颜色分布、纹理、边缘、主体颜色的标准。这里主要介绍一下后边使用到的边缘直方图描述算法的原理。计算边缘直方图的主要步骤如下:
- 首先将一个原始图像平均分割为4×4 共16 个子图像,之后的处理都是对每一个子图像局部边缘的直方图进行计算。每个局部的边缘直方图使用五个5边缘算子进行处理。最终得到80维向量,用于唯一标识这张图片。
- 把每个子图像分割成为一系列图像块, 这些图像块的,面积随着图像面积的变化而变化。其中每个子图像的图像数目是固定的,可参考图一。
- 计算并统计每个图像块的五种边缘类型( 水平、垂直、45°、135°和无方向) ,此为MPEG-7推荐的五种边缘检测算子,最终得到五个边缘方向的最大值。
- 对得到的边缘直方图的值进行归一化和量化。考虑到人眼视觉的非均匀性,将归一化以后的80 个直方条的值进行非线性量化, 每个直方条使用固定长度的3位进行编码(即量化范围为0~8),总共用240个bit来表示边缘直方图。
- 考虑两个边缘直方图描述符, 通过计算直方图间的欧几里德距离得到两个纹理图像的相似度,十分直观的,距离为0说明两幅图片的边缘纹理完全相同,距离越大说明相似度越小。
三、图像特征索引的build与基于图像的query
在海量(百万以上)的图像特征中,寻找亚线性时间复杂度的匹配算法是十分有挑战的,特别的,由于是近似检索,我们需要的是数字上的非精确匹配,让我们看一下能想到的方法:
- 线性扫描:即对整个样本向量集合进行穷举式的顺序扫描,分别计算其与query图像的欧式距离,然后排序输出。准确度100%但过高的时间复杂度导致其实用性极差
- 基于树结构的索引:比如sift作者推荐的KD-tree,SR-tree等。但由于“维度灾难(curse of dimensionality)”的存在,当向量维度大于10到20之后,基于树结构的索引需要扫描整个向量集合的绝大部分,加上算法本身的开销,其效果甚至要差于上述的蛮力查找。
- 聚类:摒弃了树型结构建立索引之后,许多研究人员继而使用基于Kmeans聚类(层级聚类)的向量量化方法,其本质是将向量映射为标量,取得了一定的成功。但是,该方法的时间复杂度与图像的数量息息相关,当规模扩大时,biuld与query的时间开销仍然无法达到线上使用的地步。
- 基于散列表的索引:与上类似,其本质也是将向量转化为标量进行匹配。散列表的主要好处有两点,一是query时间与数据结构的大小无关,基本上是O(1)的时间复杂度;二是增量build较其它方法更为方便。当然,直接将图像特征存放在散列表中,或者放在数据库的某一个字段中,只能进行精确匹配,只能返回一模一样的图片,对于图像检索来说,其价值点几乎为零;因此单纯的散列表技术还是无法满足我们的需求。
- 常用的hash函数(crc、md5等),本质上都是基于密码学的脆弱哈希函数,其特点是输入只要有略微不同,产生的结果应该尽可能大的变化。本文采用的局部敏感哈希(Locality Sensitive Hashing, LSH)方法,在向量匹配方面与索引方面都要比传统的树结构和聚类算法快上好几个数量级,支持非精确查找,在我看来,是目前所知最适用于多媒体检索的算法。
LSH主要是用来解决多维向量的K近邻(K Nearst Neighgor)问题,即查找某一多维向量间的K个最相似的向量。这是一种概率算法,其原理类似于bloom filter,存在一定的false positive,但换来的是检索效率的飞跃提升。
LSH的主要原理是:建立L个散列表来存放索引,每一个散列表Ti包含M个存放数据的桶,另外提供两套函数族Gi与Hi与之相关联。局部敏感哈希算法在概率意义上将相近的向量映射到相同的桶当中去,利用该特质可以对图像特征进行非精确匹配。为了最大限度的避免概率上的失误,采用多个hash函数映射到不同的hash表中去,分散误差,如图二所示。
- 将向量p标识转化为Hamming空间中的二进制向量(每一维仅为1或0),设某一维的向量值为x,最大值为c,则表示为连续的x个1紧跟c-x个0的c维二进制向量。因此该向量在原始空间的距离与其Hamming距离一致。
- 将散列函数G作用在前面所产生的结果上,G的定义为,选取目标向量的K维二进制向量进行拼接。可以看出,目标向量之间相似度越大,其产生的hash值相等的概率越大。这是达到非精确检索的关键一环。
- 基于2产生的结果,再用常规的哈希函数(md5)进行二次哈希将二次哈希得到的结果存放到一张哈希表的一个桶里,再使用下一个函数进行计算,周而复始。正如我们前面所说的那样,采用了多个hash函数来减少相似检索的误差。这样,相似的图像就被放到同一个桶里,而不同的图像则被放到另外的桶里了,如图三所示。
- query图像时,计算其特征值,并从前面建立的多个表中查询出结果,拼接在一起,如图四所示。
- 针对上一步返回的近似图像,分别计算其欧式距离,排序,进一步去除极小概率上的false positive。



局部敏感哈希将多维近似检索的时间复杂度进一步降低到亚线性级别,同时,合理选择哈希函数的个数与种类又可以使检索的准确率和召回率达到平衡。
四、实验结果
为验证MPEG-7边缘直方图配合局部敏感哈希算法的结果,本文使用了隐网项目中的违禁数据库进行测试。测试环境为公司的Dell PC,测试条件如下所示:
样本库数量:14085
样本类别:国家安全类、文化传媒类、限售、药物器械
持久化index文件容量:3.07MB
从图片build时间:406ms
从索引文件build时间:15min
query时间:0ms
测试效果范例:
输入的待检索图片:
Query得到相似图片结果:
五、后续工作
1、sift特征的引入,局部图像检索的实现
2、lsh算法,参数的自动优化
3、百万级数据测试
4、不同场景、类别下策略的分析