K Nearest Neighbor问题的解决——KD-TREE Implementation
命题一:
已知的1000个整数的数组,给定一个整数,要求查证是否在数组中出现?
命题二:
已知1000个整数的数组,给定一个整数,要求查找数组中与之最接近的数字?
命题三:
已知1000个Point(包含X与Y坐标)结构的数组,给定一个Point,要求查找数组中与之最接近(比如:欧氏距离最短)的点。
命题四:
已知1,000,000个向量,每个向量为128维;给定一个向量,要求查找数组中与之最接近的K个向量
高维向量的KNN检索问题,在图像等多媒体内容搜索中是相当关键的。关于高维向量的讨论,网上资料比较少;在此,我将一些心得分享给大家。
与二叉树相比,KD-TREE也采用类似的划分方式,只不过树中的各节点均是高维向量,因此划分的方式,采用随机或指定的方式选取一个维度,在该指定维度上进行划分;整体的思想就是采用多个超平面对数据集空间进行两两切分,这一点,有点类似于数据挖掘中的决策树。
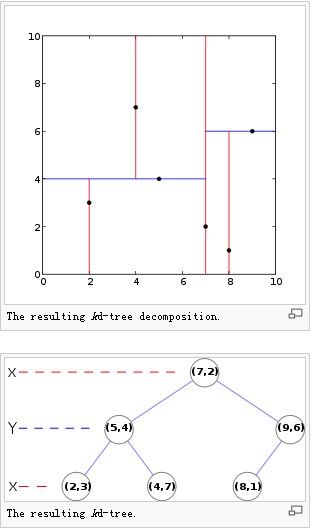
一个运用KD-TREE分割二维平面的DEMO如下:
KD-Tree build的代码如下:
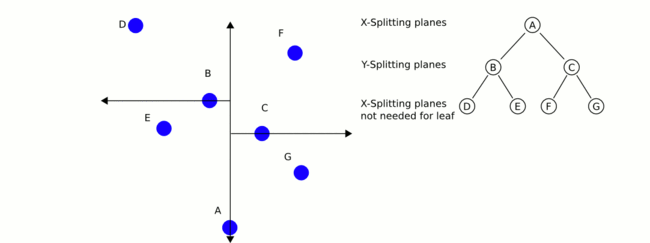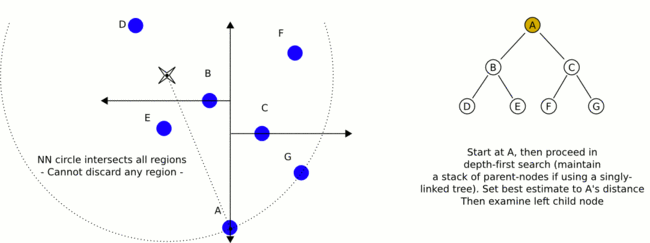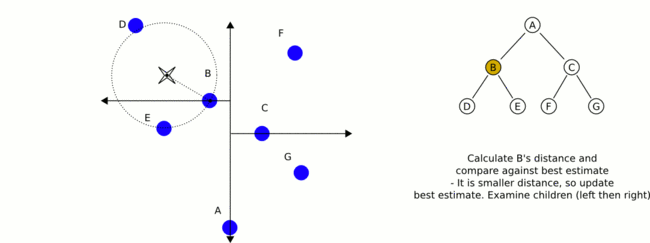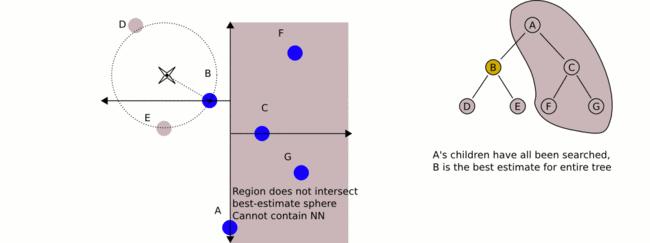
构建完一颗KD-TREE之后,如何使用它来做KNN检索呢?我用下面的图来表示(20s的GIF动画):
使用KD-TREE,经过一次二分查找可以获得Query的KNN(最近邻)贪心解,代码如下:
事实上,仅仅一次的遍历会有不小的误差,因此采用了一个优先级队列来存放每次决定遍历走向时,另一方向的节点。SizedPriorityQueue代码的实现,可参考我的另一篇文章:
http://grunt1223.iteye.com/blog/909739
一种减少误差的方法(BBF:Best Bin First)是回溯一定数量的节点:
可以用如下代码进行测试:
已知的1000个整数的数组,给定一个整数,要求查证是否在数组中出现?
命题二:
已知1000个整数的数组,给定一个整数,要求查找数组中与之最接近的数字?
命题三:
已知1000个Point(包含X与Y坐标)结构的数组,给定一个Point,要求查找数组中与之最接近(比如:欧氏距离最短)的点。
命题四:
已知1,000,000个向量,每个向量为128维;给定一个向量,要求查找数组中与之最接近的K个向量
- 对于命题一,如果不考虑桶式、哈希等方式,常用的方法应该是排序后,使用折半查找。
- 对于命题二,与命题一类似,比较折半查找得出的结果,以及附近的各一个元素,即可。整个过程相当于是把这个包含1000个数组的数据结构做成一颗二叉树,最后只需比较叶子节点与其父节点即可。
- 对于命题三、四其中命题三和四就是所谓的Nearest Neighbor问题。一种近似解决的方法就是KD-TREE
高维向量的KNN检索问题,在图像等多媒体内容搜索中是相当关键的。关于高维向量的讨论,网上资料比较少;在此,我将一些心得分享给大家。
与二叉树相比,KD-TREE也采用类似的划分方式,只不过树中的各节点均是高维向量,因此划分的方式,采用随机或指定的方式选取一个维度,在该指定维度上进行划分;整体的思想就是采用多个超平面对数据集空间进行两两切分,这一点,有点类似于数据挖掘中的决策树。
一个运用KD-TREE分割二维平面的DEMO如下:
KD-Tree build的代码如下:
private ClusterKDTree(Clusterable[] points, int height, boolean randomSplit){
if ( points.length == 1 ){
cluster = points[0];
}
else {
splitIndex = chooseSplitDimension//选取切分维度
(points[0].getLocation().length,height,randomSplit);
splitValue = chooseSplit(points,splitIndex);//选取切分值
Vector<Clusterable> left = new Vector<Clusterable>();
Vector<Clusterable> right = new Vector<Clusterable>();
for ( int i = 0; i < points.length; i++ ){
double val = points[i].getLocation()[splitIndex];
if ( val == splitValue && cluster == null ){
cluster = points[i];
}
else if ( val >= splitValue ){
right.add(points[i]);
} else {
left.add(points[i]);
}
}
if ( right.size() > 0 ){
this.right = new ClusterKDTree(right.toArray(new
Clusterable[right.size()]),
randomSplit ? splitIndex : height+1, randomSplit);
}
if ( left.size() > 0 ){
this.left = new ClusterKDTree(left.toArray(new
Clusterable[left.size()]),randomSplit ? splitIndex : height+1,
randomSplit);
}
}
}
private int chooseSplitDimension(int dimensionality,int height,boolean random){
if ( !random ) return height % dimensionality;
int rand = r.nextInt(dimensionality);
while ( rand == height ){
rand = r.nextInt(dimensionality);
}
return rand;
}
private double chooseSplit(Clusterable points[],int splitIdx){
double[] values = new double[points.length];
for ( int i = 0; i < points.length; i++ ){
values[i] = points[i].getLocation()[splitIdx];
}
Arrays.sort(values);
return values[values.length/2];//选取中间值以保持树的平衡
}
构建完一颗KD-TREE之后,如何使用它来做KNN检索呢?我用下面的图来表示(20s的GIF动画):
使用KD-TREE,经过一次二分查找可以获得Query的KNN(最近邻)贪心解,代码如下:
private Clusterable restrictedNearestNeighbor(Clusterable point, SizedPriorityQueue<ClusterKDTree> values){
if ( splitIndex == -1 ) {
return cluster; //已近到叶子节点
}
double val = point.getLocation()[splitIndex];
Clusterable closest = null;
if ( val >= splitValue && right != null || left == null ){
//沿右边路径遍历,并将左边子树放进队列
if ( left != null ){
double dist = val - splitValue;
values.add(left,dist);
}
closest = right.restrictedNearestNeighbor(point,values);
}
else if ( val < splitValue && left != null || right == null ) {
//沿左边路径遍历,并将右边子树放进队列
if ( right != null ){
double dist = splitValue - val;
values.add(right,dist);
}
closest = left.restrictedNearestNeighbor(point,values);
}
//current distance of the 'ideal' node
double currMinDistance = ClusterUtils.getEuclideanDistance(closest,point);
//check to see if the current node we've backtracked to is closer
double currClusterDistance = ClusterUtils.getEuclideanDistance(cluster,point);
if ( closest == null || currMinDistance > currClusterDistance ){
closest = cluster;
currMinDistance = currClusterDistance;
}
return closest;
}
事实上,仅仅一次的遍历会有不小的误差,因此采用了一个优先级队列来存放每次决定遍历走向时,另一方向的节点。SizedPriorityQueue代码的实现,可参考我的另一篇文章:
http://grunt1223.iteye.com/blog/909739
一种减少误差的方法(BBF:Best Bin First)是回溯一定数量的节点:
public Clusterable restrictedNearestNeighbor(Clusterable point, int numMaxBinsChecked){
SizedPriorityQueue<ClusterKDTree> bins = new SizedPriorityQueue<ClusterKDTree>(50,true);
Clusterable closest = restrictedNearestNeighbor(point,bins);
double closestDist = ClusterUtils.getEuclideanDistance(point,closest);
//System.out.println("retrieved point: " + closest + ", dist: " + closestDist);
int count = 0;
while ( count < numMaxBinsChecked && bins.size() > 0 ){
ClusterKDTree nextBin = bins.pop();
//System.out.println("Popping of next bin: " + nextBin);
Clusterable possibleClosest = nextBin.restrictedNearestNeighbor(point,bins);
double dist = ClusterUtils.getEuclideanDistance(point,possibleClosest);
if ( dist < closestDist ){
closest = possibleClosest;
closestDist = dist;
}
count++;
}
return closest;
}
可以用如下代码进行测试:
public static void main(String args[]){
Clusterable clusters[] = new Clusterable[10];
clusters[0] = new Point(0,0);
clusters[1] = new Point(1,2);
clusters[2] = new Point(2,3);
clusters[3] = new Point(1,5);
clusters[4] = new Point(2,5);
clusters[5] = new Point(1,1);
clusters[6] = new Point(3,3);
clusters[7] = new Point(0,2);
clusters[8] = new Point(4,4);
clusters[9] = new Point(5,5);
ClusterKDTree tree = new ClusterKDTree(clusters,true);
//tree.print();
Clusterable c = tree.restrictedNearestNeighbor(new Point(4,4),1000);
System.out.println(c);
}