SQL查询性能分析
SQL查询性能的好坏直接影响到整个数据库的价值,对此,必须郑重对待。
SQL Server提供了多种工具,下面做一个简单的介绍:
一、SQL Profiler工具
SQL Profiler可用于:
l 图形化监视SQLServer查询;
l 在后台收集查询信息;
l 分析性能;
l 诊断像死锁这样的问题;
l 调试Transact-SQL(T-SQL)语句;
l 模拟重放SQLServer活动
注意:定义一个跟踪最有效的方法是通过系统存储过程,但是学习的起点还是通过GUI。
1.1、Profiler跟踪:
建议使用标准模版
1.2、事件:
一个事件表现SQLServer中执行的各种活动。可以简单分类为:事件类、游标事件、锁事件、存储过程事件和T-SQL事件。
对于性能分析,主要关心以下部分:
l SQL活动涉及哪一类的CPU使用?
l 使用了多少内存?
l 涉及多少I/O操作?
l SQL活动执行了多长时间?
l 特定的查询执行的频率多高?
l 查询面对哪类错误和警告?
跟踪查询结束的事件:
| 事件类 |
事件 |
描述 |
| Stored Procedures |
RPC:Completed |
RPC完成事件 |
| SP:Completed |
存储过程完成事件 |
|
| SP:StmtCompleted |
在存储过程中一条SQL语句完成事件 |
|
| TSQL |
SQL:BatchCompleted |
T-SQL批完成事件 |
| SQL:StmtCompleted |
一条T-SQL语句完成事件 |
RPC事件表示存储过程使用远程过程调用(RPC)机制通过OLEDB命令执行。如果一个数据库应用程序使用T-SQL EXECUTE语句执行一个存储过程,那么会被转化为一个SQL批而不是一个RPC,RPC通常比EXECUTE请求快,因为它们绕过了SQLServer中的许多语句解析和参数处理。
T-SQL批是一组被一起提交到SQLServer的SQL查询,以GO结束。GO不是一条T-SQL语句,而是有Sqlcmd使用程序和Management Studio识别。象征着批的结束。T-SQL批由一条或多条T-SQL语句组成。语句或T-SQL语句在存储过程(以下简称SP)中也是独立和离散的。用SP:StmtCompleted或SQL:StmtCompleted事件捕获单独的语句可能代价很高。收集时要非常谨慎,特别在生产环境上。
跟踪查询性能的事件:
| 事件类 |
事件 |
描述 |
| Security Audit(安全审计) |
Audit Login(登录审计) |
记录用户连接到SQL Server或断开连接时数据库的连接 |
| Audit Logou(注销审计) |
||
| Seesions(会话) |
ExistingConnection(现有连接) |
表示所有在跟踪开始之前连接到SQLServer的用户 |
| Cursors(游标) |
CursorImplicitConversion(游标隐含转换) |
表明创建的游标类型与所请求的类型不同。 |
| Errors and Warnings(错误和警告) |
Attention(注意) |
表示由于客户撤销查询或者数据库连接破坏引起的请求中断 |
| Exception(异常) |
表明SQLServer中发生了异常 |
|
| Execution Warnings(执行警告) |
表明在查询或SP执行过程中出现了警告 |
|
| Hash Warning(hash警告) |
表明hash操作中发生了错误 |
|
| Missing Column Statistics(列统计丢失) |
表明优化器要求的确定处理策略用的列统计丢失。 |
|
| Missing Join Predicate(连接断言丢失) |
表明查询在两表之间没有连接断言情况下执行。 |
|
| Sort Warnings(排序警告) |
表明像select这样的查询中执行的排序操作没有合适的内存。 |
|
| Locks(锁) |
Lock: Deadlock(死锁) |
标志着死锁的出现 |
| Lock: Deadlock Chain(死锁链) |
显示产生死锁的查询链条 |
|
| Lock: Timeout(锁超时) |
表示锁已经超过了其超时参数,该参数由SET LOCK_TIMEOUT timeout_period(MS)命令设置 |
|
| Stored Procedures(存储过程) |
SP:Recompile(重编译) |
表明用于一个存储过程的执行计划必须重编译,原因是执行计划不存在,强制的重编译,或者现有的执行计划不能重用。 |
| SP:Starting(开始) SP:StmtStarting(语句开始) |
分别表示一个SP:StmtStarting存储过程和存储过程中的一条SQL语句的开始。它们对于识别开始但因为一个操作导致Attention事件而未能结束的查询很有用。 |
|
| Transactions(事务) |
SQLTransaction(SQL事务) |
提供数据库事务的信息,包括事务开始/结束的时间、事务持续时间的信息。 |
1.3、数据列:事件的特性。如事件的类、用于该事件的SQL语句、锁资源开销及事件来源。
| 数据列 |
描述 |
| EventClass(事件类) |
事件类型,如SQL:StatementCompleted |
| TextData |
事件所用的SQL语句 |
| CPU |
事件的CPU开销(ms) |
| Reads |
为一个事件所执行的逻辑读操作数量。 |
| Writes |
一个事件所执行的逻辑写操作数量。 |
| Duration |
事件的执行事件(ms) |
| SPID |
该事件的进程ID |
| StratTime |
事件开始的事件 |
逻辑读、写由内存中的8KB页面活动组成,可能需要0或者多个物理I/O。找到物理I/O操作数,使用系统监视工具。
二、跟踪的自动化
注意:SQL Profiler对性能存在负面影响,如非必要不要在生产环境长期使用。
1.使用GUI捕捉跟踪:
可以使用两种方法创建脚本化的跟踪——手工或GUI:
可以使用Profiler的导出功能导出脚本。
2.使用存储过程捕捉跟踪:
l Sp_trace_create:创建一个跟踪定义。
l Sp_trace_setevent:添加事件和事件列到跟踪中。
l Sp_trace_setfilter:将过滤器应用到跟踪。
可以使用内建函数:fn_trace_getinfo确定正在运行的跟踪:
SELECT * FROM ::fn_trace_getinfo(default);
可以使用:sp_trace_setstatus停止特定的跟踪:
EXEC sp_trace_setstatus 1,0
—停止id为1的跟踪。
关闭跟踪后,必须删除:
EXEC sp_trace_setstatus 1,2
可以重新执行fn_trace_getinfo函数确认是否已经关闭。
三、结合跟踪和性能监视器输出
可以结合SQL Profiler和性能监视器来分析性能,此处不多说
四、SQL Profiler建议
使用SQL Profiler时,要考虑以下几点:
l 限制事件和数据列的数量;
l 抛弃用于性能分析的启动事件;
l 限制跟踪输出大小;
l 避免联机数据列排序;
l 远程运行Profiler
1、 限制事件和数据列:
捕捉像锁和执行计划这样的事件时应该小心进行,因为输出会变得非常大并降低SQL Server性能。
2、 丢弃性能分析所用的启动事件:
像SP:StmtStarting这样的启动事件不提供分析信息,因为只有事件完成才能计算I/O量、CPU负载和查询的持续时间。
使用捕捉启动事件的时机是:预期某些SQL查询因为错误而不能结束执行,或者频繁发现Attention事件按的时候捕捉。因为Attention事件一般表示用户中途撤销了查询或者查询超时,可能因为查询运行了太长时间。
3、 限制跟踪输出大小:
在Edit Filter(编辑过滤器)对话框中做以下设置:
l Duration-Greater than or equal:2(持续事件>=2):持续事件等于0或1ms的查询不能进一步优化。
l Reads-Greater than or equal:2(读操作数量>=2):逻辑读数量等于0或1的查询不能进一步优化。
4、 避免在线数据列排序:
(1)、捕捉跟踪,不做任何排序或分组。
(2)、保存跟踪输出到一个跟踪文件。
(3)、打开跟踪文件并按照需要排序。
5、 远程运行Profiler:
使用系统存储过程比使用GUI对性能方面有好处。
6、 限制使用某些事件:在已经遇到压力的系统上,不要使用Showplan XML事件
五、没有Profiler情况下的查询性能度量
对于需要立即捕捉系统,使用DMV:sys.dm_exec_query_stats比Profiler有效,如果需要查询运行机器单独开销的历史记录,跟踪仍是更好的工具。
sys.dm_exec_query_stats:获取服务器上查询计划统计的信息:
| 列 |
描述 |
| Plan_handle |
引用执行计划的指针 |
| Creation_time |
计划创建的时间 |
| Last_execution time |
查询最后一次使用计划的时间 |
| Execution_count |
计划已经使用的次数 |
| Total_worker_time |
从创建起计划使用的CPU时间 |
| Total_logical_reads |
从创建起计划使用的读操作数量 |
| Total_logical_writes |
从创建起计划使用的写操作数量 |
| Query_hash |
可用于识别有类似逻辑的查询的一个二进制hash |
| Query_plan_hash |
可用于识别有相似逻辑的计划的一个二进制hash |
为了过滤信息,需要关联其他DMF。如sys.dm_exec_sql_text来查看查询文本。
Sys.dm_query_plan显示查询的执行计划。从而限制不必要的返回信息。
六、开销较大的查询
对于收集结果,应该分析两部分:
l 导致大量系统资源压力的查询;
l 速度降低最严重的查询
1、 识别开销较大的查询:
对于返回的跟踪数据,CPU和Reads列显示了查询开销所在。在执行读操作时,内存页面必须在操作查询中被备份,在第一次数据访问期间写入,并在内存瓶颈时被移到磁盘。过多页面CPU还会增加管理页面的负担。
导致大量逻辑读的查询通常在相应的大数据集上得到锁。即使读,也需要在所有数据上的共享锁。阻塞了其他请求修改的查询。但不阻塞读数据的查询。如果查询很久,那么会持续阻塞其他查询,被阻塞的查询进一步阻塞其他查询,引起数据中的阻塞链。
结论,识别开销大的查询并首先优化它们从而达到以下效果:
l 增进开销较大的查询本身的性能;
l 降低系统资源上的总体压力;
l 减少数据库阻塞;
开销大的查询有两类:
l 单次执行:查询一次开销较大
l 多次执行:查询本身不大,但是重复执行导致系统资源上的压力。
1.单次执行开销较大的查询:
可以使用SQL Profiler,或者查询sys.dm_exec_query_stats来识别开销大的查询。
(1)、捕捉表示典型工作负载的Profiler跟踪。
(2)、将跟踪输出保存到一个跟踪文件。
(3)、打开跟踪文件进行分析。
(4)、打开跟踪的Properties(属性)窗口,单击Event Selection(事件选择)选项卡。
(5)、单机按钮打开Organize Columns(组织列)窗口。
(6)、在Reads列上分组跟踪输出。
(7)、使用分组的跟踪。
2.多次执行开销较大的查询:
l 这种情况下,Profiler中跟踪输出的以下列上分组:EventClass、TextData和Reads。
l 导出Profiler跟踪表。使用内建函数fn_trace_gettable导入到一个跟踪表。
l 访问sys.dm_exec_query_statsDMV从生产服务器检索信息。
把数据装入到数据库的一个表中
SELECT *
INTO Trace_Table
FROM ::
FN_TRACE_GETTABLE('C:\PerformanceTrace.trc', DEFAULT)
执行下面语句查询多次执行的读操作总数:
SELECT COUNT(*) AS TotalExecutions ,
EventClass ,
TextData ,
SUM(Duration) AS Duration_Total ,
SUM(CPU) AS CPU_Total ,
SUM(Reads) AS Reads_Total ,
SUM(Writes) AS Writes_Total
FROM Trace_Table
GROUP BY EventClass ,
TextData
ORDER BY Reads_Total DESC
SQL Server 2008不支持在NTEXT数据类型进行分组。而TextData是ntext类型,要转换成Nvarchar(max)
SELECT ss.sum_execution_count ,
t.text ,
ss.sum_total_elapsed_time ,
ss.sum_total_worker_time ,
ss.sum_total_logical_reads ,
ss.sum_total_logical_writes
FROM ( SELECT s.plan_handle ,
SUM(s.execution_count) sum_execution_count ,
SUM(s.total_elapsed_time) sum_total_elapsed_time ,
SUM(s.total_worker_time) sum_total_worker_time ,
SUM(s.total_logical_reads) sum_total_logical_reads ,
SUM(s.total_logical_writes) sum_total_logical_writes
FROM sys.dm_exec_query_stats s
GROUP BY s.plan_handle
) AS ss
CROSS APPLY sys.dm_exec_sql_text(ss.plan_handle) t
ORDER BY sum_total_logical_readsDESC
3.识别运行缓慢的查询:
需要定期监视输入的SQL查询的执行时间,并找出运行缓慢的查询的响应时间。但是不是所有运行缓慢的查询都是由于资源问题形成。如阻塞那些都有可能导致缓慢的查询。
可以在Duration上跟踪。
七、执行计划
1、 分析查询计划
执行计划从右到左,从上到下的顺序阅读。每个步骤代表获得查询最终输出所执行的操作。执行计划有以下特征:
l 如果查询由多个查询的批组成,每个查询的执行计划按照执行的顺序显示。批中的每个执行将有一个相对的估算开销,整个批的总开销为100%。
l 执行计划中的每个图标代表一个操作符。有相对的估算开销,所有节点的总开销为100%。
l 执行计划中的一个起始操作符通常表示一个数据库对象(表或索引)的数据检索机制。
l 数据检索通常是一个表操作或索引操作。
l 索引上的数据检索将是索引扫描或索引查找。
l 索引上的数据检索的命名惯例是[表名].[索引名]。
l 数据从右到左在两个操作之间流动,由一个连接箭头表示。
l 操作符之间连接箭头的宽度是传输行数的图形表示。
l 同一列的两个操作符之间的连接机制将是嵌套的循环连接,hash匹配连接或者合并连接。
l 将光标放置在执行计划的一个节点上,显示一个具有一些细节的弹出窗口。
l 在Properties(属性)窗口中有完整的一组关于操作符的细节。可以右键单击操作符并选择Properties。
l 操作符细节在顶部显示物理和逻辑操作的类型。物理操作代表存储引擎实际使用的,而逻辑操作是优化器用于建立估算执行计划的结构。如果相同,只显示物理操作。还会显示其他信息:I/O、CPU等。
l 操作符细节弹出窗口的Argument(参数)部分在分析中特别有用,因为显示了优化器锁使用的过滤或连接条件。
2、 识别执行计划中开销较大的步骤:
l 执行计划中每个节点显示整个计划中的相对开销,整个计划总开销为100%。关注最高相对开销的节点。
l 执行计划可能来自于一批语句,因此可能也需要查找开销最大的语句。
l 查看节点之间连接箭头的宽度。非常宽的连接箭头表示对应节点之间的传输大量的行。分析箭头左边的节点以理解需要这么多行的原因,还要检查箭头的属性。可能看到估计的行和实际的行不一样,这可能由过时的统计造成。
l 寻找hash连接操作。对于小的数据集,嵌套的循环连接通常是首选的连接技术。
l 寻找书签查找操作。对于大结果集的书签操作可能造成大量的逻辑读。
l 如果操作符上有一个叹号的警告,是需要立刻注意的领域。这些警告可能是由各种问题造成的,包括没有连接条件的连接或者丢失统计的索引和表。
l 需找执行排序操作的步骤,这表示数据没有以正确的排序进行检索。
3、 分析索引有效性:
要关注【扫描】,扫描代表访问大量的行。可以通过以下方式判断索引有效性:
l 数据检索操作
l 连接操作
有时候执行计划中没有【断言】(predicate),缺乏断言意味着整个表(聚簇索引就是该表)被作为合并连接操作符的输入进行扫描。
4、 分析连接有效性:
SQLServer使用3中连接类型:
l Hash连接;
l 合并连接
l 嵌套循环连接
1、 Hash连接:
1.1、Hash连接高效处理大的、未排序的、没有索引的输入。
1.2、Hash连接使用两个连接输入:建立输入(build input)和探查输入(probe input)。建立输入是执行计划中上面的那个输入,探查输入是下面那个输入。
1.3、最常见的hash连接方式——in-memory hash join,整个建立输入被扫描或计算然后在内存中建立一个hash表。每个行根据计算的hash键值(相等断言中的一组列)被插入一个hash表元中。
内存hash连接的示意图:
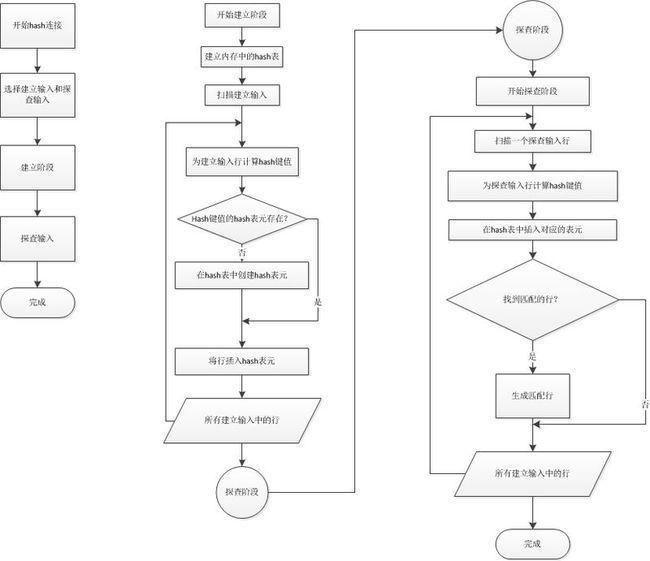
2、 合并连接:
2.1、合并连接要求两个输入在合并列上排序,这将在连接条件中定义。如果两个连接有索引,那么连接输入由该索引排序。由于每个连接输入都被排序了,合并排序从每个输入得到一行并比较是否相等。如果相等,匹配行被生成。过程被重复到所有行都被处理。
2.2、如果优化器发现连接输入都在其连接列上排序,合并连接就比hash连接更快而被选中。
3、 嵌套循环连接:
3.1、始终从单独的表中访问有限数量的行,为了理解使用较小结果集的效果,在查询中降低连接输入。
3.2、使用一个连接输入作为外部(outer)输入表。另一个作为内部(inner)输入表。外部表是执行计划的上方输入,内部表是下方输入。外部循环逐行消费外部输入表。内部循环为每个外部行执行一次,搜索内部输入表的匹配行。
3.3、如果外部输入相当小,内部输入大但有索引,嵌套循环连接是非常高效的。连接通过牺牲其他方面来提高速度——使用内存来取得小的数据集并快速与第二个数据集比较。合并排序与此类似,使用内存和一小部分tempdb排序,hash连接使用内存和tempdb建立hash表。
3.4、虽然循环连接更快,但是随着数据集变得更大,比hash或合并消耗更多的内存。所以SQL Server会在不同数据集的情况下使用不同计划的原因。
3种连接类型的特性:
| 连接类型 |
连接列上的索引 |
连接表的一般大小 |
预先排序 |
连接子句 |
| Hash |
内部表:不需要索引 外部表:可选 最佳条件:小的外部表,大的内部表 |
任意 |
不需要 |
Equi-join |
| 合并 |
内部/外部表:必须 最佳条件:两个表都有聚簇索引或覆盖索引 |
大 |
需要 |
Equi-join |
| 嵌套循环 |
内部表:必须 外部表:最好有 |
小 |
可选 |
所有 |
注意:在hash和嵌套循环连接中,外部表一般是两个连接表中较小的一个。
5、 实际执行计划vs估算执行计划:
估算执行计划对临时表无法生成。
6、 计划缓存:
一般是保存在内存空间。可以使用DMV来查询:
SELECT p.query_plan ,
t.text
FROM sys.dm_exec_cached_plansr
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) p
CROSS APPLY sys.dm_exec_sql_text(r.plan_handle) t
八、查询开销
1、 客户统计:将计算机作为服务器的一个客户端,从这个角度去发出捕捉执行信息。
点击SSMS中的【查询】→【包含客户统计】,但这一步不是很好的收集方法。有时候需要重置:【查询】→【重置客户统计】
2、 执行时间:
Duration和CPU都代表着查询的时间因素,可以使用SET STATISTICS TIME来取得执行时间。

其中最后一行的CPU时间等于Profiler的CPU值,占用时间代表Duration值。0毫秒的分析和编译时间说明重用了执行计划。可以执行:DBCC FREEPROCCACHE清除缓存。但是不要在生产系统上执行,因为某种情况下,这和重启的开销相同。
3、 STATISTICS IO:
Profiler获取的Reads列的读取次数尝尝是Duration、CPU、Reads和Writes这些因素中最重要的。在解读STATISTICS IO的输出时,多半参考【逻辑读】操作。有时候也会参考扫描计数。物理读操作和预读数量在数据不能在内存中找到时将不为0,但一旦数据填写到内存,物理读和预读将趋向于0。在优化期间,可以监控单表的读操作次数以确保确实减少了该表的数据访问开销。