Cassandra Dev 1: Cassandra 入门
最近, Cassandra 绝对是一个比较前端的话题,随着互联网的不断发展, Distributed Database 的广受重视是一种必然, Cassandra 在存取效率、分散管理、容错能力、稳定性等方面的优点是其他Distributed Database 无法比拟的,So, 研究Cassandra 是非常有必要的。我将从下列方面学习Cassandra :
1. Cassandra目录结构
从http://cassandra.apache.org/download/下载最新Cassandra,解压后目录结构如下 :

如图由上向下:
bin中存放这一些可操作Cassandra脚本,如cassandra.bat,点击可以启动Cassandra
conf中包含一些Cassandra配置信息
interface中存放Cassandra的Thrift接口定义文件,可以用于生成各种语言的接口代码
javadoc中为Cassandra帮助文档(API)
lib中为Cassandra运行时依赖的包
2. Cassandra HelloWorld
从学C语言开始,HelloWorld是一种传统,所以先写个HelloWorld,在apache-cassandra-0.6.4\conf目录下storage-conf.xml文件中,该文件中包含Cassandra的所有配置,先列出简单一些:
<!-- A --> <ClusterName>Test Cluster</ClusterName> <!-- B --> <Keyspaces> <Keyspace Name="Keyspace1"> </Keyspace> </Keyspaces> <!-- C --> <CommitLogDirectory>/var/lib/cassandra/commitlog</CommitLogDirectory> <DataFileDirectories> <DataFileDirectory>/var/lib/cassandra/data</DataFileDirectory> </DataFileDirectories> <!-- D --> <ThriftPort>9160</ThriftPort>
如上:
A处定义Cluster名字(也称结点名字),一个Cluster可以包含多个Keyspace;
B处定义了此Cluster中包含一个Keyspace,且名字为Keyspace1,Keyspace相当于与关系数据库中的database;
C处定义了Cassandra数据和Commitlog存放的位置,如不对其做修改,在Windows下启动Cassandra,在D盘根目录下产生如上面所示的文件夹;
D处定义了Thrift RPC 端口号为9160,
在默认配置文件下启动Cassandra,然后编写如下代码:
package com.tibco.cassandra;
import java.io.UnsupportedEncodingException;
import java.util.Date;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnOrSuperColumn;
import org.apache.cassandra.thrift.ColumnPath;
import org.apache.cassandra.thrift.ConsistencyLevel;
import org.apache.cassandra.thrift.InvalidRequestException;
import org.apache.cassandra.thrift.NotFoundException;
import org.apache.cassandra.thrift.TimedOutException;
import org.apache.cassandra.thrift.UnavailableException;
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
public class CassandraHelloWorld {
public static void main(String[] args) throws UnsupportedEncodingException, InvalidRequestException, UnavailableException, TimedOutException, TException, NotFoundException {
//Part One
TTransport trans = new TSocket("127.0.0.1", 9160);
TProtocol proto = new TBinaryProtocol(trans);
Cassandra.Client client = new Cassandra.Client(proto);
trans.open();
//Part Two
String keyspace = "Keyspace1";
String cf = "Standard2";
String key = "kylinsoong";
long timestamp = new Date().getTime();
ColumnPath path = new ColumnPath(cf);
path.setColumn("id".getBytes("UTF-8"));
client.insert(keyspace, key, path, "520".getBytes("UTF-8"), timestamp, ConsistencyLevel.ONE);
path.setColumn("action".getBytes("UTF-8"));
client.insert(keyspace, key, path, "Hello, World, Cassandra!".getBytes("UTF-8"), timestamp, ConsistencyLevel.ONE);
//Part Three
path.setColumn("id".getBytes("UTF-8"));
ColumnOrSuperColumn cc = client.get(keyspace, key, path, ConsistencyLevel.ONE);
Column c = cc.getColumn();
String value = new String(c.value, "UTF-8");
System.out.println(value);
path.setColumn("action".getBytes("UTF-8"));
ColumnOrSuperColumn cc2 = client.get(keyspace, key, path, ConsistencyLevel.ONE);
Column c2 = cc2.getColumn();
String value2 = new String(c2.value, "UTF-8");
System.out.println(value2);
//Part four
trans.close();
}
}
运行代码,伟大的Hello,World将会出现在我们眼前,运行结果:
520 Hello, World, Cassandra!
先对代码做个简单分析,我将代码分为四个部分:
Part One,连接到数据库,相当于JDBC,具体这里是通过RPC通信协议连接到Cassandra的;
Part Two,向数据库中插入数据;
Part Three,读出刚才插入的数据;
Part four, 关闭数据库连接。
3. 和关系数据库从存储效率上做个比较:
我们先不说Cassandra的数据模型及它的集群,首先我们从实验的角度比较它与Mysql的存储效率,比较之前先做个解释;
关系数据库最小的存储单元是row,而Cassandra是grid(此说法只是为了形象比喻)如下图;
![]() 所示为一个row包含4个grid;
所示为一个row包含4个grid;
对关系数据库,可以一次插入或读取一行,而Cassandra只能一次插入或读取一个格,也就是说要插入此行信息关系数据库只需一个插入语句,而Cassandra需要四个,看上去关系数据库更有效率,实际上结果将会使你为之Shocking;
开始我们的实验,在本地开启Cassandra服务器:
在Mysql中创建一个数据库,在数据库中创建下表:
create table test ( parseTime varchar(40)primary key, id varchar(40), creationTime varchar(40), globalInstanceId varchar(255), msg varchar(255), severity varchar(20), modelName varchar(255), rComponent varchar(255), rExecutionEnvironment varchar(255), sExecutionEnvironment varchar(255), sLocation varchar(255), msgId varchar(255) );
此表中包含12 column,为了简单索引column对应类型都是字符串,
向此表中插入68768 * 2 条数据,查看记录测试时间,如下为测试程序输出Log
|
Mysql --- 0 ---- Error Error Error Error Error Error Total add: 68768, spent time: 1654569 --- 1 ---- Error Total add: 68768, spent time: 1687645 Total add: 137536, Error: 7, Spent Time: 3342214 Average: 24.3004 |
将同样的数据向Cassandra中插入68768 * 10条数据,查看记录测试时间,程序输出日志如下:
|
Cassandra --- 0 ----Total add: 68768, spent time: 212047 --- 1 ----Total add: 68768, spent time: 210518 --- 2 ----Total add: 68768, spent time: 211602 --- 3 ----Total add: 68768, spent time: 213543 --- 4 ----Total add: 68768, spent time: 209558 --- 5 ----Total add: 68768, spent time: 211302 --- 6 ----Total add: 68768, spent time: 214699 --- 7 ----Total add: 68768, spent time: 212685 --- 8 ----Total add: 68768, spent time: 215412 --- 9 ----Total add: 68768, spent time: 218858 Total: 687680 Time: 2130224 Average: Insert one key: 3.0977 Insert one column: 0.2581 |
分析日志文件,向Cassandra中插入687680条数据,实际执行(687680 * 12次插入),耗费时间:2130224毫秒,合计35分钟多一点,没有发生插入错误等现象,说明Cassandra稳定性比Mysql好,每插入一条记录所需时间仅为3.0977毫秒,执行一次插入所需时间为0.2581毫秒;
比较两组日志文件可以得出以下结论:
向Cassandra插入数据条数是向Mysql插入数据条数的5倍,但总消耗时间Cassandra少于Mysql;
就插入一条数据而言,Cassandra的效率是Mysql的8倍
在做另为一组实验:在数据库中载创建一个此时表,如下:
create table time ( id varchar(20) );
是的,此表只有一个字段,目的是让Cassandra与Mysql更有可比性。
同样先看Mysql输出日志:
|
Mysql Add 100 000 keys, Spent time: 2477828 Average: 24.7783 |
分析输出日志向Mysql数据库插入100 000条数据花费2477828毫秒,合计40分钟,执行一次插入所需时间为24.7783毫秒;
再看Cassandra输出日志
|
Cassandra Add 100 000 keys, Spent time: 25281 Average: 0.2528 |
分析日志,同样向Cassandra插入100 000条数据,花费时间为25281毫秒,执行一次插入所需时间为0.2528毫秒;
比较两组输出日志:
在插入数据条数相同的情况下(100 000条)Mysql花费的时间是Cassandra的98倍;
执行一次操作Mysql花费的时间是Cassandra的98倍;
结论:Cassandra的存储效率是Mysql的100倍左右
4. Cassandra数据模型
Twitter的数据存储用的就是Cassandra,这里我将以Twitter存储数据的模型为例,说明Cassandra的数据模型,先将我们上面的storage-conf.xml配置文件做一下修改,如下:
<Storage> <ClusterName>Kylin-PC</ClusterName> <Keyspaces> <Keyspace Name="Twitter"> <ColumnFamily CompareWith="UTF8Type" Name="Statuses" /> <ColumnFamily CompareWith="UTF8Type" Name="StatusAudits" /> <ColumnFamily CompareWith="UTF8Type" Name="StatusRelationships" CompareSubcolumnsWith="TimeUUIDType" ColumnType="Super" /> <ColumnFamily CompareWith="UTF8Type" Name="Users" /> <ColumnFamily CompareWith="UTF8Type" Name="UserRelationships" CompareSubcolumnsWith="TimeUUIDType" ColumnType="Super" /> </Keyspace> </Keyspaces> </Storage>
上面Keyspace就是真实的Twitter存储数据的模型的定义,它里面包含5个ColumnFamily,对照Mysql,Keyspace相当于一个数据库,ColumnFamily 相当于数据库中一张表;
上面配置文件中ClusterName表示Cassandra的一个节点实例(逻辑上的一个Cassandra Server,一般为一台PC),名字为Kylin-PC,一个节点实例可以包括多个Keyspace;
下面我分别结合实例从以下几个方面说明Cassandra的数据模型:
(一)、ColumnFamily
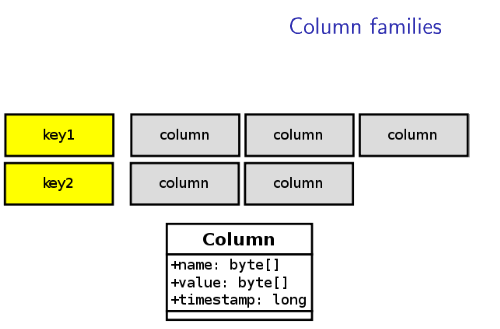
如图,ColumnFamily 包含多个Row,上面说过ColumnFamily 相当于关系数据库中的一个Table,每一个Row都包含有Client提供的Key以及和该Key相关的一系列Column,每个Column都包括name,value,timestamp,值得注意每个Row中包含的Column不一定相同;
修改上面HelloWorld程序,修给后代码如下:
public static void main(String[] args) throws Exception {
TTransport trans = new TSocket("127.0.0.1", 9160);
TProtocol proto = new TBinaryProtocol(trans);
Cassandra.Client client = new Cassandra.Client(proto);
trans.open();
String keyspace = "Twitter";
String columnFamily = "Users";
ColumnPath path = new ColumnPath(columnFamily);
String row1 = "kylin";
path.setColumn("id".getBytes());
client.insert(keyspace, row1, path,"101".getBytes(),new Date().getTime(),ConsistencyLevel.ONE);
path.setColumn("name".getBytes());
client.insert(keyspace, row1, path,"Kylin Soong".getBytes(),new Date().getTime(),ConsistencyLevel.ONE);
String row2 = "kobe";
path.setColumn("id".getBytes());
client.insert(keyspace, row2, path,"101".getBytes(),new Date().getTime(),ConsistencyLevel.ONE);
path.setColumn("name".getBytes());
client.insert(keyspace, row2, path,"Kobe Bryant".getBytes(),new Date().getTime(),ConsistencyLevel.ONE);
path.setColumn("age".getBytes());
client.insert(keyspace, row2, path,"32".getBytes(),new Date().getTime(),ConsistencyLevel.ONE);
path.setColumn("desc".getBytes());
client.insert(keyspace, row2, path,"Five NBA title, One regular season MVP, Two Final Games MVP".getBytes(),new Date().getTime(),ConsistencyLevel.ONE);
path.setColumn("id".getBytes());
ColumnOrSuperColumn cos11 = client.get(keyspace, row1, path, ConsistencyLevel.ONE);
path.setColumn("name".getBytes());
ColumnOrSuperColumn cos12 = client.get(keyspace, row1, path, ConsistencyLevel.ONE);
Column c11 = cos11.getColumn();
Column c12 = cos12.getColumn();
System.out.println(new String(c11.getValue()) + " | " + new String(c12.getValue()));
path.setColumn("id".getBytes());
ColumnOrSuperColumn cos21 = client.get(keyspace, row2, path, ConsistencyLevel.ONE);
path.setColumn("name".getBytes());
ColumnOrSuperColumn cos22 = client.get(keyspace, row2, path, ConsistencyLevel.ONE);
path.setColumn("age".getBytes());
ColumnOrSuperColumn cos23 = client.get(keyspace, row2, path, ConsistencyLevel.ONE);
path.setColumn("desc".getBytes());
ColumnOrSuperColumn cos24 = client.get(keyspace, row2, path, ConsistencyLevel.ONE);
Column c21 = cos21.getColumn();
Column c22 = cos22.getColumn();
Column c23 = cos23.getColumn();
Column c24 = cos24.getColumn();
System.out.println(new String(c21.getValue()) + " | " + new String(c22.getValue())+ " | " + new String(c23.getValue()) + " | " + new String(c24.getValue()));
trans.close();
}
上面代码所示:向名字为“Users”的columnFamily中添加2行,第一行包含2个Column,Column名字分别为:id、name;第二行包含4个Column,Column名字非别为id、name、age、desc;运行上述代码结果如下:
101 | Kylin Soong 101 | Kobe Bryant | 32 | Five NBA title, One regular season MVP, Two Final Games MVP
(二)SuperColumn
SuperColumn中包含多个Column,下面我们用程序实现向SuperColumn中添加,读取数据,先看下图:
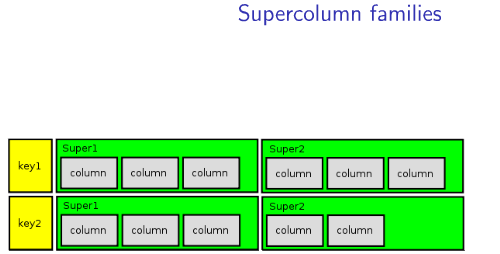
如上图所示ColumnFamily 包括2行,每行包括2个SuperColumn,每个SuperColumn中包含多个Column,下面我们用代码演示上图情景,为了简单,我们把两行,简化为一行;
修改HelloWorld代码,如下:
public static void main(String[] args) throws Exception {
TTransport trans = new TSocket("127.0.0.1", 9160);
TProtocol proto = new TBinaryProtocol(trans);
Cassandra.Client client = new Cassandra.Client(proto);
trans.open();
String keyspace = "Twitter";
String columnFamily = "UserRelationships";
String row = "row";
Map<String, List<ColumnOrSuperColumn>> cfmap = new HashMap<String, List<ColumnOrSuperColumn>>();
List<ColumnOrSuperColumn> cslist = new ArrayList<ColumnOrSuperColumn>();
ColumnOrSuperColumn cos = new ColumnOrSuperColumn();
List<Column> columnList = new ArrayList<Column>();
Column id = new Column();
id.setName("id".getBytes());
id.setValue("101".getBytes());
id.setTimestamp(new Date().getTime());
Column name = new Column();
name.setName("name".getBytes());
name.setValue("Kylin Soong".getBytes());
name.setTimestamp(new Date().getTime());
columnList.add(id);
columnList.add(name);
SuperColumn sc = new SuperColumn();
sc.setColumns(columnList);
sc.setName("super1".getBytes());
cos.super_column = sc;
cslist.add(cos);
cfmap.put(columnFamily, cslist);
Map<String, List<ColumnOrSuperColumn>> cfmap2 = new HashMap<String, List<ColumnOrSuperColumn>>();
List<ColumnOrSuperColumn> cslist2 = new ArrayList<ColumnOrSuperColumn>();
ColumnOrSuperColumn cos2 = new ColumnOrSuperColumn();
List<Column> columnList2 = new ArrayList<Column>();
Column id2 = new Column();
id2.setName("id".getBytes());
id2.setValue("101".getBytes());
id2.setTimestamp(new Date().getTime());
Column name2 = new Column();
name2.setName("name".getBytes());
name2.setValue("Kobe Bryant".getBytes());
name2.setTimestamp(new Date().getTime());
Column age = new Column();
age.setName("age".getBytes());
age.setValue("32".getBytes());
age.setTimestamp(new Date().getTime());
Column desc = new Column();
desc.setName("desc".getBytes());
desc.setValue("Five NBA title, One regular season MVP, Two Final Games MVP".getBytes());
desc.setTimestamp(new Date().getTime());
columnList2.add(id2);
columnList2.add(name2);
columnList2.add(age);
columnList2.add(desc);
SuperColumn sc2 = new SuperColumn();
sc2.setColumns(columnList2);
sc2.setName("super2".getBytes());
cos2.super_column = sc2;
cslist2.add(cos2);
cfmap2.put(columnFamily, cslist2);
client.batch_insert(keyspace, row, cfmap, ConsistencyLevel.ONE);
client.batch_insert(keyspace, row, cfmap2, ConsistencyLevel.ONE);
ColumnPath path = new ColumnPath(columnFamily);
path.setSuper_column("super1".getBytes());
ColumnOrSuperColumn s = client.get(keyspace, row, path, ConsistencyLevel.ONE);
System.out.println(new String(s.super_column.columns.get(0).value) + " | " + new String(s.super_column.columns.get(1).value));
path.setSuper_column("super2".getBytes());
ColumnOrSuperColumn s2 = client.get(keyspace, row, path, ConsistencyLevel.ONE);
System.out.println(new String(s2.super_column.columns.get(2).value) + " | " + new String(s2.super_column.columns.get(3).value) + " | " + new String(s2.super_column.columns.get(0).value) + " | " + new String(s2.super_column.columns.get(1).value));
trans.close();
}
上述代码演示往名字叫“UserRelationships”的columnFamily中添加一行,这一行中包含两个SuperColumn,名字分别:super1和super2,super1包含2个Column,名字分别为id,name;super2包含4个Column,名字分别为id,name,age,desc,运行结果:
101 | Kylin Soong 101 | Kobe Bryant | 32 | Five NBA title, One regular season MVP, Two Final Games MVP
(三)Column
从上面一、二可以看到Column是Cassandra的最小存储单位,它的结构如下:
struct Column {
1: binary name,
2: binary value,
3: i64 timestamp,
}
(四)keyspace
如上面一二中 String keyspace = "Twitter"; 都定义了keyspace 是名字为“Twitter”,相当于干系数据库中的Schema或数据库。
结束