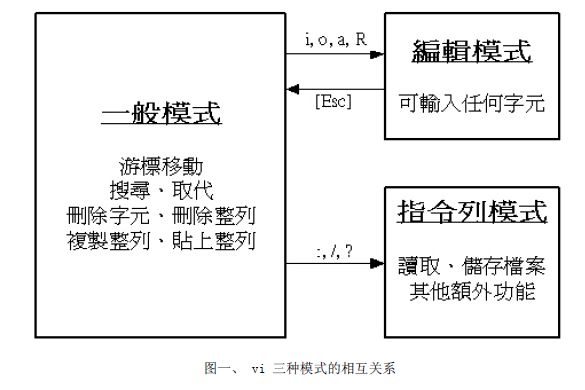
vi 共分为三种模式,分别是『一般模式』、 『编辑模式』与『指令列命令模式』
[root@linux ~]# vi test.txt
| 一般模式: 移动光标的方法 |
|
| h 或 向左方向键 (← ) |
光标向左移动一个字符 |
| j 或 向下方向键 (↓ ) |
光标向下移动一个字符 |
| k 或 向上方向键 (↑ ) |
光标向上移动一个字符 |
| l 或 向右方向键 (→ ) |
光标向右移动一个字符 |
| 如果想要进行多次移动的话,例如向下移动 30 行,可以使用 "30j" 或 "30↓ " 的组合按键, 亦即加上想要进行的次数 (数字 )后,按下动作即可! |
|
| [Ctrl] + [f] |
屏幕『向下』移动一页,相当于 [Page Down]按键 (常用 ) |
| [Ctrl] + [b] |
屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用 ) |
| [Ctrl] + [d] |
屏幕『向下』移动半页 |
| [Ctrl] + [u] |
屏幕『向上』移动半页 |
| + |
光标移动到非空格符的下一列 |
| - |
光标移动到非空格符的上一列 |
| n<space> |
那个 n 表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的 n 个字符。例如 20<space> 则光标会向后面移动 20 个字符距离。 |
| 0 |
这是数字『 0 』:移动到这一行的最前面字符处 (常用 ) |
| $ |
移动到这一行的最后面字符处 (常用 ) |
| H |
光标移动到这个屏幕的最上方那一行 |
| M |
光标移动到这个屏幕的中央那一行 |
| L |
光标移动到这个屏幕的最下方那一行 |
| G |
移动到这个档案的最后一行 (常用 ) |
| nG |
n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行 (可配合 :set nu) |
| gg |
移动到这个档案的第一行,相当于 1G 啊! (常用 ) |
| n<Enter> |
n 为数字。光标向下移动 n 行 (常用 ) |
| 一般模式: 搜寻与取代 |
|
| /word |
向光标之下寻找一个字符串名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用 ) |
| ?word |
向光标之上寻找一个字符串名称为 word 的字符串。 |
| n |
这个 n 是英文按键。代表『重复前一个搜寻的动作』的意思。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! |
| N |
这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 |
| :n1,n2s/word1/word2/g |
n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则: 『 :100,200s/vbird/VBIRD/g』。 (常用 ) |
| :1,$s/word1/word2/g |
从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 ! (常用 ) |
| :1,$s/word1/word2/gc |
从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给使用者确认 (conform) 是否需要取代! (常用 ) |
| 一般模式: 删除、复制与贴上 |
|
| x, X |
在一行字当中, x 为向后删除一个字符 (相当于 [del] 按键 ), X 为向前删除一个字符 (相当于 [backspace] 亦即是退格键 ) (常用 ) |
| nx |
n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『 10x』。 |
| dd |
删除游标所在的那一整行(常用 ) |
| ndd |
n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用 ) |
| d1G |
删除光标所在到第一行的所有数据 |
| dG |
删除光标所在到最后一行的所有数据 |
| d$ |
删除游标所在处,到该行的最后一个字符 |
| d0 |
那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
| yy |
复制游标所在的那一行 (常用 ) |
| nyy |
n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行 (常用 ) |
| y1G |
复制光标所在列到第一列的所有数据 |
| yG |
复制光标所在列到最后一列的所有数据 |
| y0 |
复制光标所在的那个字符到该行行首的所有数据 |
| y$ |
复制光标所在的那个字符到该行行尾的所有数据 |
| p, P |
p 为将已复制的数据在光标下一行贴上, P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用 ) |
| J |
将光标所在列与下一列的数据结合成同一列 |
| c |
重复删除多个数据,例如向下删除 10 行, [ 10cj ] |
| u |
复原前一个动作。 (常用 ) |
| [Ctrl]+r |
重做上一个动作。 (常用 ) |
| 这个 u 与 [Ctrl]+r 是很常用的指令!一个是复原,另一个则是重做一次~ 利用这两个功能按键,您的编辑,嘿嘿!很快乐的啦! |
|
| . |
不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果您想要重复删除、重复贴上等等动作,按下小数点『 .』就好了! (常用 ) |
| 进入编辑模式 |
|
| i, I |
插入:在目前的光标所在处插入输入之文字,已存在的文字会向后退; 其中, i 为『从目前光标所在处插入』, I 为『在目前所在行的第一个非空格符处开始插入』。 (常用 )
|
| a, A |
a 为『从目前光标所在的下一个字符处开始插入』, A 为『从光标所在行的最后一个字符处开始插入』。 (常用 ) |
| o, O |
这是英文字母 o 的大小写。 o 为『在目前光标所在的下一行处插入新的一行』; O 为在目前光标所在处的上一行插入新的一行! (常用 ) |
| r, R |
取代: r 会取代光标所在的那一个字符; R会一直取代光标所在的文字,直到按下 ESC 为止; (常用 ) |
| 上面这些按键中,在 vi 画面的左下角处会出现『 --INSERT--』或『 --REPLACE--』的字样。 由名称就知道该动作了吧!!特别注意的是,我们上面也提过了,你想要在档案里面输入字符时, 一定要在左下角处看到 INSERT/REPLACE 才能输入喔! |
|
| Esc |
退出编辑模式,回到一般模式中 (常用 ) |
| 指令列命令模式 |
|
| :w |
将编辑的数据写入硬盘档案中 (常用 ) |
| :w! |
若档案属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟您对该档案的档案权限有关啊! |
| :q |
离开 vi (常用 ) |
| :q! |
若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 |
| 注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ |
|
| :wq |
储存后离开,若为 :wq! 则为强制储存后离开 (常用 ) |
| :e! |
将档案还原到最原始的状态! |
| ZZ |
若档案没有更动,则不储存离开,若档案已经经过更动,则储存后离开! |
| :w [filename] |
将编辑的数据储存成另一个档案(类似另存新档) |
| :r [filename] |
在编辑的数据中,读入另一个档案的数据。亦即将 『 filename』 这个档案内容加到游标所在行后面 |
| :n1,n2 w [filename] |
将 n1 到 n2 的内容储存成 filename 这个档案。 |
| :! command |
暂时离开 vi 到指令列模式下执行 command 的显示结果!例如 『 :! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! |
| :set nu |
显示行号,设定之后,会在每一行的前缀显示该行的行号 |
| :set nonu |
与 set nu 相反,为取消行号! |
| 区块选择的按键意义 |
|
| v |
字符选择,会将光标经过的地方反白选择! |
| V |
行选择,会将光标经过的行反白选择! |
| [Ctrl]+v |
区块选择,可以用长方形的方式选择资料 |
| y |
将反白的地方复制起来 |
| d |
将反白的地方删除掉 |
多档案编辑
| 多档案编辑的按键 |
|
| :n |
编辑下一个档案 |
| :N |
编辑上一个档案 |
| :files |
列出目前这个 vim 的开启的所有档案 |
# 在这个档案中利用上个小节提到的区块选择,按下 [ctrl]+v 来进行区块选择,并复制。
# 然后按下 :n 在指令列的地方输入这玩意儿,就会转到下一个档案去,这个时候,
# 就可以按下 p 将刚刚复制的 IP 给贴到您的档案中啰!如果您按下 :files ,则显示:
:files
1 %a "hosts" line 1
2 # "/etc/hosts" line 1
Hit ENTER or type command to continue
在一个vim环境里如何开启新窗口呢? 很简单啊!在指令列模式输入:『:sp {filename}』
| 多窗口情况下的按键功能 |
|
| :sp [filename] |
开启一个新窗口,如果有加 filename, 表示在新窗口开启一个新档案,否则表示两个窗口为同一个档案内容(同步显示)。 |
| [ctrl]+wj |
按键的按法是:先按下 [ctrl] 不放, 再按下 w 后放开所有的按键,然后再按下 j ,则光标可移动到下方的窗口。 |
| [ctrl]+wk |
同上,不过光标移动到上面的窗口。 |
| [ctrl]+wq |
其实就是 :q 结束离开啦! 举例来说,如果我想要结束下方的窗口,那么利用 [ctrl]+wj 移动到下方窗口后,按下 :q 即可离开, 也可以按下 [ctrl]+wq 啊! |
vim 环境设定
vim 的环境设定参数有很多,如果您想要知道目前的设定值,可以在一般模式时输入:『 :set all 』 来查阅
| vim 的环境设定参数 |
|
| :set nu |
还记得这个吧?!就是设定行号啊!取消的话,就是 :set nonu |
| :set hlsearch |
这个就是设定是否将搜寻的字符串反白的设定值。 默认值就是 hlsearch ,如果不想要反白,就 :set nohlsearch 。 |
| :set autoindent |
是否自动缩排?autoindent 就是自动缩排, 不想要缩排就 :set noautoindent 。 |
| :set backup |
是否自动储存备份档?一般是 nobackup 的, 如果设定 backup 的话,那么当你更动任何一个档案时,则源文件会被另存成一个档名为 filename~ 的档案。 举例来说,我们编辑 hosts ,设定 :set backup ,那么当更动 hosts 时,在同目录下,就会产生 hosts~ 文件名的档案,记录原始的 hosts 档案内容~ |
| :set ruler |
还记得我们提到的右下角的一些状态列说明吗? 这个 ruler 就是在显示或不显示该设定值的啦! |
| :set showmode |
这个则是,是否要显示 --INSERT-- 之类的字眼在左下角的状态列。 |
| :set backspace=(012) |
一般来说, 如果我们按下 i 进入编辑模式后,可以利用退格键 (backspace) 来删除任意字符的。 但是,某些 distribution 则不许如此。此时,我们就可以透过 backspace 来设定啰~ 当 backspace 为 2 时,就是可以删除任意值;0 或 1 时,仅可删除刚刚输入的字符, 而无法删除原本就已经存在的文字了! |
| :set all |
显示目前所有的环境参数设定值。 |
| :syntax (off|on) |
是否依据程序相关语法显示不同颜色? 举例来说,在编辑一个纯文字文件时,如果开头是以 # 开始,那么该行就会变成蓝色。 如果您懂得写程序,那么这个 :syntax on 还会主动的帮您除错呢!但是,如果您仅是编写纯文本文件,要避免颜色对您的屏幕产生的干扰,则可以取消这个设定 :syntax off 。
|
查询某个指令是来自于外部指令(指的是其它非 bash 套件所提供的指令) 或是内建在 bash 当中的
参数:
:不加任何参数时,则 type 会显示出那个 name 是外部指令还是 bash 内建的指令!
-t :当加入 -t 参数时,type 会将 name 以底下这些字眼显示出他的意义:
file :表示为外部指令;
alias :表示该指令为命令别名所设定的名称;
builtin :表示该指令为 bash 内建的指令功能;
-p :如果后面接的 name 为指令时,会显示完整文件名(外部指令)或显示为内建指令;
-a :会将由 PATH 变量定义的路径中,将所有含有 name 的指令都列出来,包含 alias
范例:
[root@linux ~]# type cd
cd is a shell builtin
为了区别与自订变量的不同,环境变量通常以大写字符来表示
变量的取用与设定:echo, 变量设定规则, unset
[root@linux ~]# echo $PATH
/bin:/sbin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin:/usr/X11R6/bin
[root@linux ~]# echo ${PATH}
1. 变量与变量内容以等号『=』来连结;
2. 等号两边不能直接接空格符;
3. 变量名称只能是英文字母与数字,但是数字不能是开头字符;
4. 若有空格符可以使用双引号『 " 』或单引号『 ' 』来将变量内容结合起来,但须要特别留意, 双引号内的特殊字符可以保有变量特性,但是单引号内的特殊字符则仅为一般字符;
5. 必要时需要以跳脱字符『 \ 』来将特殊符号 ( 如 Enter, $, \, 空格符, ' 等 ) 变成一般符号;
6. 在一串指令中,还需要藉由其它的指令提供的信息,可以使用 quote 『 ` command` 』;(特别特别注意,那个 ` 是键盘上方的数字键 1 左边那个按键,而不是单引号!)
7. 若该变量为扩增变量内容时,则需以双引号及 $变量名称 如:『 "$PATH":/home』继续累加内容;
8. 若该变量需要在其它子程序执行,则需要以 export 来使变量变成环境变量, 如『export PATH』;
9. 通常大写字符为系统预设变量,自行设定变量可以使用小写字符,方便判断 ( 纯粹依照使用者兴趣与嗜好 ) ;
10. 取消变量的方法为:『unset 变量名称』。
[root@linux ~]# name=VBird
范例二:承上题,若变量内容为 VBird's name 呢?
[root@linux ~]# name="VBird's name" <==OK 的啦!
[root@linux ~]# name=VBird\'s\ name
# 利用反斜线 (\) 跳脱特殊字符,例如单引号与空格键,这也是 OK 的啦!范例三,我要将 name 的内容多出 "yes" 呢?
范例三,我要将 name 的内容多出 "yes" 呢?
[root@linux ~]# name="$name"yes
[root@linux ~]# name=${name}yes
举例来说,我想要知道每个 crontab 相关档名的权限:
[root@linux ~]# ls -l `locate crontab`
如此一来,先以 locate 将文件名数据都列出来,再以 ls 指令来处理的意思
范例一:列出目前的 shell 环境下的所有环境变量与其内容。
[root@linux ~]# env
HOSTNAME=linux.dmtsai.tw <== 这部主机的主机名称
SHELL=/bin/bash <== 目前这个环境下,使用的 Shell 是哪一个程序?
TERM=xterm <== 这个终端机使用的环境是什么类型
HISTSIZE=1000 <== 这个就是『记录指令的笔数』在 FC4 预设可记录 1000 笔
USER=root <== 使用者的名称啊!
所有的变量说明: set
除了会将环境变量列出来之外,其它我们的自订变量,与所有的变量,都会被列出来
[root@linux ~]# set
!),这个东西就是我们的『命令提示字符』啊! 当我们每次按下 [Enter] 按键去执行某个指令后,最后要再次出现提示字符时, 就会主动去读取这个变数值了。
\d :代表日期,格式为 Weekday Month Date,例如 "Mon Aug 1"
\H :完整的主机名称。举例来说,鸟哥的练习机 linux.dmtsai.tw ,那么这个主机名称就是 linux.dmtsai.tw
\h :仅取主机名称的第一个名字。以上述来讲,就是 linux 而已, .dmtsai.tw 被省略。
\t :显示时间,为 24 小时格式,如: HH:MM:SS
\T :显示时间,12 小时的时间格式!
\A :显示时间,24 小时格式, HH:MM
\u :目前使用者的账号名称;
\v :BASH 的版本信息;
\w :完整的工作目录名称。家目录会以 ~ 取代;
\W :利用 basename 取得工作目录名称,所以仅会列出最后一个目录名。
\# :下达的第几个指令。
\$ :提示字符,如果是 root 时,提示字符为 # ,否则就是 $ 啰~
[root@linux /home 17:02 #85]#
代表的是『目前这个 Shell 的执行绪代号』,亦即是所谓的 PID (Process ID)。
想要知道我们的 shell 的 PID ,就可以: echo $$ 即可
当我们执行某些指令时, 这些指令都会回传一个执行后的代码。一般来说,如果成功的执行该指令, 则会回传一个 0 值,如果执行过程发生错误,就会回传『错误代码』才对
例如:
[root@linux ~]# echo $SHELL
/bin/bash
[root@linux ~]# echo $?
0
例如:
[cloudsolv@CDC-V-Cent-8 22:04 #13]$ echo $MACHTYPE
x86_64-redhat-linux-gnu
export 变量
Linux 到底支持了多少的语系呢?这可以由 locale 这个指令来查询到
[root@linux ~]# locale -a
要读取来自键盘输入的变量,就是用 read 这个指令了。这个指令最常被用在 shell script 的撰写当中, 以跟使用者进行对谈。
[root@linux ~]# read [-pt] variable
参数:
-p :后面可以接提示字符!
-t :后面可以接等待的『秒数!』这个比较有趣~不会一直等待使用者啦!
范例:
范例一:让使用者由键盘输入一内容,将该内容变成 atest 变量
[root@linux ~]# read atest
This is a test
[root@linux ~]# echo $atest
This is a test
declare 或 typeset 是一样的功能,就是在宣告变量的属性。如果使用 declare 后面并没有接任何参数, 那么 bash 就会主动的将所有的变量名称与内容通通叫出来,就好像使用 set 一样啦
[root@linux ~]# declare [-aixr] variable
参数:
-a :将后面的 variable 定义成为数组 (array)
-i :将后面接的 variable 定义成为整数数字 (integer)
-x :用法与 export 一样,就是将后面的 variable 变成环境变量;
-r :将一个 variable 的变量设定成为 readonly ,该变量不可被更改内容,也不能 unset
范例一:让变量 sum 进行 100+300+50 的加总结果
[root@linux ~]# declare -i sum=100+300+50
[root@linux ~]# echo $sum
450
范例二:将 sum 变成环境变量
[root@linux ~]# declare -x sum
数组的设定方式是:
var[index]=content
范例:设定上面提到的 var[1] ~ var[3] 的变数。
[root@linux ~]# var[1]="small min"
[root@linux ~]# var[2]="big min"
[root@linux ~]# var[3]="nice min"
[root@linux ~]# echo "${var[1]}, ${var[2]}, ${var[3]}"
可以『限制使用者的某些系统资源』的,包括可以开启的档案数量, 可以使用的 CPU 时间,可以使用的内存总量等等.
[root@linux ~]# ulimit [-SHacdflmnpstuv] [配额]
参数:
-H :hard limit ,严格的设定,必定不能超过设定的值;
-S :soft limit ,警告的设定,可以超过这个设定值,但是会有警告讯息,
并且,还是无法超过 hard limit 的喔!也就是说,假设我的 soft limit
为 80 , hard limit 为 100 ,那么我的某个资源可以用到 90 ,
可以超过 80 ,还是无法超过 100 ,而且在 80~90 之间,会有警告讯息的意思。
-a :列出所有的限制额度;
-c :可建立的最大核心档案容量 (core files)
-d :程序数据可使用的最大容量
-f :此 shell 可以建立的最大档案容量 (一般可能设定为 2GB)单位为 Kbytes
-l :可用于锁定 (lock) 的内存量
-p :可用以管线处理 (pipe) 的数量
-t :可使用的最大 CPU 时间 (单位为秒)
-u :单一使用者可以使用的最大程序(process)数量。
[root@linux ~]# alias lm='ls -l | more'
取消命令别名的话,那么就使用 unalias
[root@linux ~]# unalias lm
[root@linux ~]# history [n]
[root@linux ~]# history [-c]
[root@linux ~]# history [-raw] histfiles
参数:
n :数字,意思是『要列出最近的 n 笔命令列表』的意思!
-c :将目前的 shell 中的所有 history 内容全部消除
-a :将目前新增的 history 指令新增入 histfiles 中,若没有加 histfiles ,
则预设写入 ~/.bash_history
-r :将 histfiles 的内容读到目前这个 shell 的 history 记忆中;
-w :将目前的 history 记忆内容写入 histfiles 中!
执行历史命令
[root@linux ~]# !number
[root@linux ~]# !command
[root@linux ~]# !!
参数:
number :执行第几笔指令的意思;
command :由最近的指令向前搜寻『指令串开头为 command』的那个指令,并执行;
!! :就是执行上一个指令(相当于按↑按键后,按 Enter)
[root@linux ~]# ../../bin/more .bashrc
以要执行这一层目录的命令就使用『 ./command 』即可
[root@linux ~]# ./squid
利用 source 或小数点 (.) 都可以将设定档的内容读进来目前的 shell 环境中
[root@linux ~]# source file
范例:
[root@linux ~]# source ~/.bashrc
[root@linux ~]# . ~/.bashrc
数据传送的指令:
1. 标准输入(stdin) :代码为 0 ,使用 < 或 << ;
2. 标准输出(stdout):代码为 1 ,使用 > 或 >>(>会覆盖, >>进行累加) ;
3. 标准错误输出(stderr):代码为 2 ,使用 2> 或 2>> ;
[root@linux ~]# ls -l / > ~/rootfile
1. 该档案 (本例中是 ~/rootfile) 若不存在,系统会自动的将他建立起来,但是,
2. 当这个档案存在的时候,那么系统就会先将这个档案内容清空,然后再将数据写入!
3. 也就是若以 > 输出到一个既存盘案中,呵呵,那个档案就会被覆盖掉啰!

[dmtsai@linux ~]$ find /home -name testing > list_right 2> list_error
如果我要将数据都写到同一个档案中呢?这个时候写法需要用到特殊写法:
[dmtsai@linux ~]$ find /home -name testing > list 2>&1 <==正确写法
[dmtsai@linux ~]$ find /home -name testing 2> /dev/null
testing
cat file test
<==这里按下 [ctrl]+d 结束输入来离开!
[root@linux ~]# cat > catfile < somefile
在指令与指令中间利用分号 (;) 来隔开,这样一来,分号前的指令执行完后, 就会立刻接着执行后面的指令了
我想要在某个目录底下建立一个档案,也就是说,如果该目录存在的话, 那我才建立这个档案,如果不存在,那就算了:
[root@linux ~]# ls /tmp && touch /tmp/testingagin
如果我想要当某个档案不存在时,就去建立那个档案, 否则就略过:
[root@linux ~]# ls /tmp/vbirding || touch /tmp/vbirding
这个管线命令『 | 』仅能处理经由前面一个指令传来的正确信息,也就是 standard output ( STDOUT ) 的信息,对于 stdandard error 并没有直接处理的能力,请记得。
例如想要知道 /etc/ 底下有多少档案,透过 less 指令的协助:
[root@linux ~]# ls -al /etc | less
cut
cut 不就是『切』吗?没错啦!这个指令可以将一段讯息的某一段给他『切』出来~ 处理的讯息是以『行』为单位喔, 将『同一行里面的数据进行分解!』
[root@linux ~]# cut -d'分隔字符' -f fields
[root@linux ~]# cut -c 字符区间
参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段讯息分割成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
范例:
范例一:将 PATH 变量取出,我要找出第三个路径。
[root@linux ~]# echo $PATH
/bin:/usr/bin:/sbin:/usr/sbin:/usr/local/bin:/usr/X11R6/bin:/usr/games:
[root@linux ~]# echo $PATH | cut -d ':' -f 5
# 嘿嘿!如此一来,就会出现 /usr/local/bin 这个目录名称!
# 因为我们是以 : 作为分隔符,第五个就是 /usr/local/bin 啊!
范例三:用 last 将这个月登入者的信息中,仅留下使用者大名
[root@linux ~]# last | cut -d ' ' -f 1
grep 是分析一行讯息, 若当中有我们所需要的信息,就将该行拿出来~
[root@linux ~]# grep [-acinv] '搜寻字符串' filename
参数:
-a :将 binary 档案以 text 档案的方式搜寻数据
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
[root@test root]# grep 'root' /var/log/secure
将 /var/log/secure 这个档案中有 root 的那一行秀出来
[root@test root]# grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
sort
[root@linux ~]# sort [-fbMnrtuk] [file or stdin]
参数:
-f :忽略大小写的差异,例如 A 与 a 视为编码相同;
-b :忽略最前面的空格符部分;
-M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法;
-n :使用『纯数字』进行排序(预设是以文字型态来排序的);
-r :反向排序;
-u :就是 uniq ,相同的数据中,仅出现一行代表;
-t :分隔符,预设是 tab 键;
-k :以那个区间 (field) 来进行排序的意思,
范例一:个人账号都记录在 /etc/passwd 下,请将账号进行排序。
[root@linux ~]# cat /etc/passwd | sort
adm:x:3:4:adm:/var/adm:/sbin/nologin
apache:x:48:48:Apache:/var/www:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
# 我省略很多的输出~由上面的数据看起来, sort 是预设『以第一个』数据来排序
排序完成了,将重复的资料仅列出一个显示
[root@linux ~]# uniq [-ic]
参数:
-i :忽略大小写字符的不同;
-c :进行计数
范例二:使用 last 将账号列出,仅取出账号栏,想要知道每个人的登入总次数呢?
[root@linux ~]# last | cut -d ' ' -f1 | sort | uniq -c
想要知道某个档案里面有多少字?多少行?多少字符,可以利用 wc 这个指令来达成
[root@linux ~]# wc [-lwm]
参数:
-l :仅列出行;
-w :仅列出多少字(英文单字);
-m :多少字符;
[root@linux ~]# cat /etc/man.config | wc
138 709 4506
# 输出的三个数字中,分别代表: 『行、字数、字符数』
想要将这个数据流的处理过程中,将某段讯息存下来
[root@linux ~]# tee [-a] file
参数:
-a :以累加 (append) 的方式,将数据加入 file 当中!
范例:
[root@linux ~]# ls -l /home | tee ~/homefile | more
# 这个范例则是将 ls 的数据存一份到 ~/homefile ,同时屏幕也有输出讯息!
tr
tr 可以用来删除一段讯息当中的文字,或者是进行文字讯息的替换
[root@linux ~]# tr [-ds] SET1 ...
参数:
-d :删除讯息当中的 SET1 这个字符串;
-s :取代掉重复的字符!
范例:
范例一:将 last 输出的讯息中,所有的小写变成大写字符:
[root@linux ~]# last | tr '[a-z]' '[A-Z]'
范例二:将 /etc/passwd 输出的讯息中,将冒号 (:) 删除
[root@linux ~]# cat /etc/passwd | tr -d ':'
[root@linux ~]# col [-x]
参数:
-x :将 tab 键转换成对等的空格键
[root@linux ~]# cat /etc/man.config | col -x | cat -A | more
# 嘿嘿!如此一来, [tab] 按键会被取代成为空格键,输出就美观多了!
paste 直接『将两行贴在一起,且中间以 [tab] 键隔开』
[root@linux ~]# paste [-d] file1 file2
参数:
-d :后面可以接分隔字符。预设是以 [tab] 来分隔的!
- :如果 file 部分写成 - ,表示来自 standard input 的资料的意思。
范例一:将 /etc/passwd 与 /etc/group 同一行贴在一起
[root@linux ~]# paste /etc/passwd /etc/group
这玩意儿就是在将 [tab] 按键转成空格键
[root@linux ~]# expand [-t] file
参数:
-t :后面可以接数字。一般来说,一个 tab 按键可以用 8 个空格键取代。
我们也可以自行定义一个 [tab] 按键代表多少个字符呢!
[root@linux ~]# split [-bl] file PREFIX
参数:
-b :后面可接欲分割成的档案大小,可加单位,例如 b, k, m 等;
-l :以行数来进行分割。
范例一:我的 /etc/termcap 有七百多K,若想要分成 300K 一个档案时?
[root@linux ~]# cd /tmp; split -b 300k /etc/termcap termcap
,在管线命令当中,常常会使用到前一个指令的 stdout 作为这次的 stdin , 某些指令需要用到文件名称 (例如 tar) 来进行处理时,该 stdin 与 stdout 可以利用减号 "-" 来替代, 举例来说:
[root@linux ~]# tar -cvf - /home | tar -xvf -
上面这个例子是说:『我将 /home 里面的档案给他打包,但打包的数据不是纪录到档案,而是传送到 stdout; 经过管线后,将 tar -cvf - /home 传送给后面的 tar -xvf - 』。后面的这个 - 则是取用前一个指令的 stdout, 因此,我们就不需要使用 file 了。
1) /bin/bash, /bin/tcsh, /bin/csh 2) /etc/shells 3) bash ,亦即是 /bin/bash。
例题二、利用 [] 来搜寻集合字符
如果我不想要 oo 前面有 g 的话呢?此时,可以利用在集合字符的反向选择 [^] 来达成
[root@test root]# grep -n '[^g]oo' regular_express.txt
例题三、行首与行尾字符 ^ $:
那如果我想要让 the 只在行首列出呢?
[root@test root]# grep -n '^the' regular_express.txt
12:the symbol '*' is represented as start.
注意到了吧?那个 ^ 符号,在字符集合符号(括号[])之内与之外是不同的! 在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义!要分清楚喔!
[root@test root]# grep -n '^$' regular_express.txt
假设我需要找出 g??d 的字符串,亦即共有四个字符, 起头是 g 而结束是 d ,我可以这样做:
[root@test root]# grep -n 'g..d' regular_express.txt
因为 * 代表的是『重复 0 个或多个前面的 RE 字符』的意义, 因此,『o*』代表的是:『拥有空字符或一个 o 以上的字符』, 特别注意,因为允许空字符(就是有没有字符都可以的意思),
因此, grep -n 'o*' regular_express.txt 将会把所有的数据都打印出来屏幕上!
[root@test root]# grep -n 'ooo*' regular_express.txt
[root@test root]# grep -n 'g.*g' regular_express.txt
『.* 就代表零个或多个任意字符』
因为 { 与 } 的符号在 shell 是有特殊意义的,因此, 我们必须要使用跳脱字符 \ 来让他失去特殊意义才行。
假设我要找到两个 o 的字符串,可以是:
[root@test root]# grep -n 'o\{2\}' regular_express.txt
|
RE 字符
|
意义与范例
|
|
^word
|
待搜寻的字符串 (word)在行首!
|
|
范例: grep -n '^#' regular_express.txt 搜寻行首为 # 开始的那一行!
|
|
|
word$
|
待搜寻的字符串 (word)在行尾!
|
|
范例: grep -n '!$' regular_express.txt 将行尾为 ! 的那一行打印出来!
|
|
|
.
|
代表『任意一个』字符,一定是一个任意字符!
|
|
范例: grep -n 'e.e' regular_express.txt
搜寻的字符串可以是 (eve) (eae) (eee) (e e) , 但不能仅有 (ee) !亦即 e 与 e 中间『一定』仅有一个字符,而空格符也是字符!
|
|
\
|
跳脱字符,将特殊符号的特殊意义去除!
|
|
范例: grep -n \' regular_express.txt 搜寻含有单引号 ' 的那一行!
|
|
|
*
|
重复零个或多个的前一个 RE 字符
|
|
范例: grep -n 'ess*' regular_express.txt 找出含有 (es) (ess) (esss) 等等的字符串,注意,因为 * 可以是 0 个,所以 es 也是符合带搜寻字符串。另外,因为 * 为重复『前一个 RE 字符』的符号, 因此,在 * 之前必须要紧接着一个 RE 字符喔!例如任意字符则为『 .*』!
|
|
|
\{n,m\}
|
连续 n 到 m 个的『前一个 RE 字符』若为 \{n\} 则是连续 n 个的前一个 RE 字符, 若是 \{n,\} 则是连续 n 个以上的前一个 RE 字符!
|
|
范例: grep -n 'go\{2,3\}g' regular_express.txt 在 g 与 g 之间有 2 个到 3 个的 o 存在的字符串,亦即 (goog)(gooog)
|
|
|
[]
|
字符集合的 RE 特殊字符的符号
|
|
[list] 范例: grep -n 'g[ld]' regular_express.txt 搜寻含有 (gl) 或 (gd) 的那一行~ 需要特别留意的是,在 [] 当中『谨代表一个待搜寻的字符』, 例如: a[afl]y 代表搜寻的字符串可以是 aay, afy, aly 亦即 [afl] 代表 a 或 f 或 l 的意思! [ch1-ch2]
范例: grep -n '[0-9]' regular_express.txt 搜寻含有任意数字的那一行!需特别留意,在字符集合 [] 中的减号 - 是有特殊意义的,他代表两个字符之间的所有连续字符!但这个连续与否与 ASCII 编码有关, 因此,您的编码需要设定正确 (在 bash 当中,需要确定 LANG 与 LANGUAGE 的变量是否正确! )
例如所有大写字符则为 [A-Z] [^] 范例: grep -n 'oo[^t]' regular_express.txt 搜寻的字符串可以是 (oog) (ood) 但不能是 (oot) ,那个 ^ 在 [] 内时, 代表的意义是『反向选择』的意思~例如,我不要大写字符,则为 [^A-Z] ~ 但是,需要特别注意的是,如果以 grep -n [^A-Z] regular_express.txt 来搜寻, 却发现该档案内的所有行都被列出,为什么?因为这个 [^A-Z] 是『非大写字符』的意思, 因为每一行均有非大写字符,例如第一行的 "Open Source" 就有 p,e,n,o.... 等等的小写字符, 以及双引号 (") 等字符,所以当然符合 [^A-Z] 的搜寻!
|
『ls -l a* 』代表的是以 a 为开头的任何档名的档案
|
RE 字符
|
意义与范例
|
|
+
|
重复『一个或一个以上』的前一个 RE 字符
|
|
范例: egrep -n 'go+d' regular_express.txt 搜寻 (god) (good) (goood)... 等等的字符串。那个 o+ 代表『一个以上的 o 』所以,上面的执行成果会将第 1, 9, 13 行列出来。
|
|
|
?
|
『零个或一个』的前一个 RE 字符
|
|
范例: egrep -n 'go?d' regular_express.txt 搜寻 (gd) (god) 这两个字符串。那个 o? 代表『空的或 1 个 o 』所以,上面的执行成果会将第 13, 14 行列出来。有没有发现到,这两个案例 ( 'go+d' 与 'go?d' )的结果集合与 'go*d' 相同? 想想看,这是为什么喔! ^_^
|
|
|
|
|
用或 ( or )的方式找出数个字符串
|
|
范例: egrep -n 'gd|good' regular_express.txt 搜寻 gd 或 good 这两个字符串,注意,是『或』! 所以,第 1,9,14 这三行都可以被打印出来喔!那如果还想要找出 dog 呢?就这样啊: egrep -n 'gd|good|dog' regular_express.txt
|
|
|
( )
|
找出『群组』字符串
|
|
范例: egrep -n 'g(la|oo)d' regular_express.txt 搜寻 (glad) 或 (good) 这两个字符串,因为 g 与 d 是重复的,所以, 我就可以将 la 与 oo 列于 ( ) 当中,并以 | 来分隔开来,就可以啦! 此外,这个功能还可以用来作为『多个重复群组』的判别喔!举例来说: echo 'AxyzxyzxyzxyzC' | egrep 'A(xyz)+C' 上面的例子当中,意思是说,我要找开头是 A 结尾是 C ,中间有一个以上的 "xyz" 字符串的意思~
|
[root@linux ~]# printf '打印格式' 实际内容
参数:
关于格式方面的几个特殊样式:
\a 警告声音输出
\b 退格键(backspace)
\f 清除屏幕 (form feed)
\n 输出新的一行
\r 亦即 Enter 按键
\t 水平的 [tab] 按键
\v 垂直的 [tabl] 按键
\xNN NN 为两位数的数字,可以转换数字成为字符。
关于 C 程序语言内,常见的变数格式
%ns 那个 n 是数字, s 代表 string ,亦即多少个字符;
%ni 那个 n 是数字, i 代表 integer ,亦即多少整数字数;
%N.nf 那个 n 与 N 都是数字, f 代表 floating (浮点),如果有小数字数,
假设我共要十个位数,但小数点有两位,即为 %10.2f 啰!
sed 可以分析 Standard Input (STDIN) 的数据, 然后将数据经过处
理后,再将他输出到 standrad out (STDOUT) 的一个工具。至于处理呢?可以进行取代、删除、新增、撷取特定行等等的功能。
[root@linux ~]# sed [-nefr] [动作]
参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN
的数据一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过
sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在指令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的
sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作
是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』
function 有底下这些咚咚:
a :新增, a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字符串,这些字符串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运作~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配
正规表示法!例如 1,20s/old/new/g 就是啦!
范例一:将 /etc/passwd 的内容列出,并且我需要打印行号,同时,请将第 2~5 行删除!
[root@linux ~]# nl /etc/passwd | sed '2,5d'
范例二:承上题,在第二行后(亦即是加在第三行)加上『drink tea?』字样!
[root@linux ~]# nl /etc/passwd | sed '2a drink tea'
范例五:仅列出第 5-7 行
[root@linux ~]# nl /etc/passwd | sed -n '5,7p'
awk 比较倾向于一行当中分成数个『字段』来处理。因此,awk 相当的适合小型的数据处理,awk 主要是处理『每一行的字段内的数据』,而预设的『字段的分隔符为 "空格键" 或 "[tab]键" 』!
[root@linux ~]# awk '条件类型1{动作1} 条件类型2{动作2} ...' filename
例如:
若我想要取出账号与登入者的 IP ,且账号与 IP 之间以 [tab] 隔开
[root@linux ~]# last | awk '{print $1 "\t" $3}'
diff
diff 就是用在比对两个档案之间的差异的,一般是用在 ASCII 纯文字文件的比对上。
[root@linux ~]# diff [-bBi] from-file to-file
参数:
from-file :一个档名,作为原始比对档案的档名;
to-file :一个档名,作为目的比对档案的档名;
注意,from-file 或 to-file 可以 - 取代,那个 - 代表『Standard input』之意。
-b :忽略一行当中,仅有多个空白的差异(例如 "about me" 与 "about me" 视为相同
-B :忽略空白行的差异。
-i :忽略大小写的不同。
范例一:比对 /tmp/test/passwd 与 /etc/passwd 的差异:
[root@linux ~]# diff /etc/passwd /tmp/test/passwd
diff 也可以比对整个目录下的差异喔! 举例来说,我们将两个目录比对一下:
[root@linux ~]# diff /etc /tmp/test
相对于 diff 的广泛用途, cmp 似乎就用的没有这么多了~ cmp 主要也是在比对两个档案,他主要利用『位』单位去比对,因此, 当然也可以比对 binary file 啰~(还是要再提醒喔, diff 主要是以『行』为单位比对, cmp 则是以『位』为单位去比对,这并不相同!)
[root@linux ~]# cmp [-s] file1 file2
参数:
-s :将所有的不同点的位处都列出来。因为 cmp 预设仅会输出第一个发现的不同点。
如何执行script档案,可以有底下几个方法:
• 将 shell.sh 加上可读与执行 (rx) 的权限,然后就能够以 ./shell.sh 来执行了;
• 直接以 sh shell.sh 的方式来直接执行即可。
功能说明:显示文字。
语 法:echo [-ne][字符串]或 echo [--help][--version]
补充说明:echo会将输入的字符串送往标准输出。输出的字符串间以空白字符隔开, 并在最后加上换行号。
参 数:-n 不要在最后自动换行
-e 若字符串中出现以下字符,则特别加以处理,而不会将它当成一般
文字输出:
\a 发出警告声;
\b 删除前一个字符;
\c 最后不加上换行符号;
\f 换行但光标仍旧停留在原来的位置;
\n 换行且光标移至行首;
\r 光标移至行首,但不换行;
\t 插入tab;
\v 与\f相同;
\\ 插入\字符;
\nnn 插入nnn(八进制)所代表的ASCII字符;
–help 显示帮助
–version 显示版本信息
使用 [] 要特别注意的是,在上述的每个组件中间都需要有空格键来分隔,假设我空格键使用『□』来表示, 那么,在这些地方你都需要有空格键:
[ "$HOME" == "$MAIL" ]
[□"$HOME"□==□"$MAIL"□]
↑ ↑ ↑ ↑
上面的例子在说明,两个字符串 $HOME 与 $MAIL 是否相同的意思。
• 在中括号 [] 内的每个组件都需要有空格键来分隔;
• 在中括号内的变量,最好都以双引号来设定;
• 在中括号内的常数,最好都以单或双引号来设定。
shell script 帮我们设定好一些指定的变量了!变量的对应是这样的:
/path/to/scriptname opt1 opt2 opt3 opt4 ...
$0 $1 $2 $3 $4 ...
这样够清楚了吧?!执行的文件名为 $0 这个变量,第一个接的参数就是 $1 啊
例如假设我要执行一个 script ,执行后,该 script 会自动列出自己的档名, 还有后面接的前三个参数:
[root@linux scripts]# vi sh07.sh
echo "The script naem is ==> $0"
[ -n "$1" ] && echo "The 1st paramter is ==> $1" || exit 0
[ -n "$2" ] && echo "The 2nd paramter is ==> $2" || exit 0
[ -n "$3" ] && echo "The 3th paramter is ==> $3" || exit 0
执行结果如下:
[root@linux scripts]# sh sh07.sh theone haha quot
利用 if .... then
当符合某个条件判断的时候, 就予以进行某项工作就是了。
if [ 条件判断式 ]; then
当条件判断式成立时,可以进行的指令工作内容;
fi
if [ 条件判断式一 ]; then
当条件判断式一成立时,可以进行的指令工作内容;
elif [ 条件判断式二 ]; then
当条件判断式二成立时,可以进行的指令工作内容;
else
当条件判断式一与二均不成立时,可以进行的指令工作内容;
fi
这个指令可以查询到目前主机有开启的网络服务端口, 可以利用『 netstat -tuln 』来取得目前主机有启动的服务。
case $变量名称 in
"第一个变量内容")
程序段
;;
"第二个变量内容")
程序段
;;
*)
不包含第一个变量内容与第二个变量内容的其它程序执行段
exit 1
;;
esac
case 的结尾当然就是将 case 倒着写,自然就是 esac, 每一个变量内容的程序段最后都需要两个分号 (;;) 来代表该程序段落的结束,这挺重要的。
例如:
case $1 in
"hello")
echo "Hello, how are you ?"
;;
"")
echo "You MUST input parameters, ex> $0 someword"
;;
*)
echo "Usage $0 {hello}"
;;
esac
function 的语法是这样的:
function fname() {
程序段
}
常见的两种循环
while [ condition ]
do
程序段落
done
这种方式中, while 是『当....时』,所以,这种方式说的是『当 condition 条件成立时,就进行循环,直到 condition 的条件不成立才停止』的意思。
until [ condition ]
do
程序段落
done
这种方式恰恰与 while 相反,它说的是『当 condition 条件成立时,就终止循环, 否则就持续进行循环的程序段。』
while [ "$yn" != "yes" ] && [ "$yn" != "YES" ]
do
read -p "Please input yes/YES to stop this program: " yn
done
for 这种语法,是『 已经知道要进行几次循环』的状态!他的语法是:
for (( 初始值; 限制值; 执行步阶 ))
do
程序段
done
我们还可以利用底下的方式来进行非数字方面的循环运作喔!
for var in con1 con2 con3 ...
do
程序段
done
我们可以做个简单的练习。假设我有三种动物,分别是 dog, cat, elephant 三种, 我想每一行都输出这样:『There are dogs...』之类的字样,则可以:
for animal in dog cat elephant
do
echo "There are ""$animal""s.... "
done
[root@linux ~]# sh [-nvx] scripts.sh
参数:
-n :不要执行 script,仅查询语法的问题;
-v :再执行 sccript 前,先将 scripts 的内容输出到屏幕上;
-x :将使用到的 script 内容显示到屏幕上,这是很有用的参数!
范例:
范例一:测试 sh16.sh 有无语法的问题?
[root@linux ~]# sh -n sh16.sh
# 若语法没有问题,则不会显示任何信息!
例题1:请建立一支 script ,当你执行该 script 的时候,该 script 可以显示: 1. 你目前的身份 (用 whoami ) 2. 你目前所在的目录 (用 pwd)
#!/bin/bash echo -e "Your name is ==> `whoami`" echo -e "The current directory is ==> `pwd`"
declare -i count=0
accounts=`cat /etc/passwd | cut -d ':' -f1`
cat /etc/passwd | cut -d ':' -f1
for account in $accounts
do
count=$(($count+1))
echo "The $count account is $account"
done
【新增使用者: useradd】
[root@linux ~]# useradd [-u UID] [-g initial_group] [-G other_group] \
> -[Mm] [-c 说明栏] [-d home] [-s shell] username
参数:
-u :后面接的是 UID ,是一组数字。直接指定一个特定的 UID 给这个账号;
-g :后面接的那个群组名称就是我们上面提到的 initial group 啦~
该 group ID (GID) 会被放置到 /etc/passwd 的第四个字段内。
-G :后面接的群组名称则是这个账号还可以支持的群组。
这个参数会修改 /etc/group 内的相关资料喔!
-M :强制!不要建立使用者家目录
-m :强制!要建立使用者家目录!
-c :这个就是 /etc/passwd 的第五栏的说明内容啦~可以随便我们设定的啦~
-d :指定某个目录成为家目录,而不要使用默认值;
-r :建立一个系统的账号,这个账号的 UID 会有限制 (/etc/login.defs)
-s :后面接一个 shell ,预设是 /bin/bash 的啦~
范例一:完全参考默认值建立一个使用者,名称为 vbird1
[root@linux ~]# useradd vbird1
[root@linux ~]# usermod [-cdegGlsuLU] username
参数:
-c :后面接账号的说明,即 /etc/passwd 第五栏的说明栏,可以加入一些账号的说明。
-d :后面接账号的家目录,即修改 /etc/passwd 的第六栏;
-e :后面接日期,格式是 YYYY-MM-DD 也就是在 /etc/shadow 内的第八个字段数据啦!
-g :后面接 group name,修改 /etc/passwd 的第四个字段,亦即是 GID 的字段!
-G :后面接 group name,修改这个使用者能够支持的群组,修改的是 /etc/group 啰~
-l :后面接账号名称。亦即是修改账号名称, /etc/passwd 的第一栏!
-s :后面接 Shell 的实际档案,例如 /bin/bash 或 /bin/csh 等等。
-u :后面接 UID 数字啦!即 /etc/passwd 第三栏的资料;
-L :暂时将使用者的密码冻结,让他无法登入。其实仅改 /etc/shadow 的密码栏。
-U :将 /etc/shadow 密码栏的 ! 拿掉,解冻啦!
范例:
范例一:修改使用者 dmtsai 的说明栏,加上『VBird's test』的说明。
[root@linux ~]# usermod -c "VBird's test" dmtsai
[root@linux ~]# userdel [-r] username
参数:
-r :连同使用者的家目录也一起删除
范例:
范例一:删除 vbird2 ,连同家目录一起删除
[root@linux ~]# userdel -r vbird2
【/etc/passwd】
这个档案的内容有点像这样:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
每一字段的意义是:
1. 账号名称
2. 密码
3. UID:这个就是使用者识别码 (ID)
4. GID:这个与 /etc/group 有关
5. 使用者信息说明栏:这个字段基本上并没有什么重要用途, 只是用来解释这个账号的意义而已
6. 家目录:这是使用者的家目录
7. Shell:登入 Linux 时为何预设是 bash 呢?就是这里设定的啦~ 这里比较需要注意的是,有一个 shell 可以用来替代成让账号无法登入的指令!那就是 /sbin/nologin 这个东西!这也可以用来制作纯 pop 邮件账号者的数据呢
【/etc/shadow】
内容有点像这样:
root:$1$i9Ejldjfjio389u9sjl$jljsoi45QE/:12959:0:99999:7:::
bin:*:12959:0:99999:7:::
共有九个字段啊, 这九个字段的用途是这样的:
1. 账号名称
2. 密码:这个才是真正的密码,而且是 经过编码过的密码啦
3. 最近更动密码的日期:这个字段记录了『更动密码的那一天』的日期
4. 密码不可被更动的天数: 第四个字段记录了这个账号的密码需要经过几天才可以被变更!如果是 0 的话, 表示密码随时可以更动的意思。
5. 密码需要重新变更的天数:必须要在这个时间之内重新设定你的密码,否则这个账号将会暂时失效。
6. 密码需要变更期限前的警告期限:当账号的密码失效期限快要到的时候, 就是上面那个『必须变更密码』的那个时间时, 系统会依据这个字段的设定,发出『警告』言论给这个账号
7. 密码过期的恕限时间:,当密码失效后,你还可以用这个密码在 n 天内进行登入的意思。 而如果在这个天数后还是没有变更密码,呵呵!那么您的账号就失效了!无法登入!
8. 账号失效日期:这个日期跟第三个字段一样,都是使用 1970 年以来的总日数设定。这个字段表示: 这个账号在此字段规定的日期之后,将无法再使用。
9. 保留:最后一个字段是保留的,看以后有没有新功能加入。
【chsh】
[dmtsai@linux ~]$ chsh [-ls]
参数:
-l :列出目前系统上面可用的 shell ,其实就是 /etc/shells 的内容!
-s :设定修改自己的 Shell 啰
范例:
范例一:列出目前系统上面所有的 shell ,并且指定 csh 为自己的 shell
[dmtsai@linux ~]$ chsh -s /bin/csh; grep dmtsai /etc/passwd
【chfn】
[root@linux ~]# chfn [-foph]
参数:
-f :后面接完整的大名;
-o :您办公室的房间号码;
-p :办公室的电话号码;
-h :家里的电话号码!
【id】
id 这个指令则可以查询某人或自己的相关 UID/GID 等等的信息
范例一:查阅自己的相关信息!
[root@linux ~]# id
uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),10(wheel)
范例二:查阅一下 dmtsai 吧~
[root@linux ~]# id dmtsai
【/etc/group】
这个档案就是在记录 GID 与群组名称的对应关系,内容有点像这样:
root:x:0:root
bin:x:1:root,bin,daemon
也是以冒号『:』作为字段的分隔符,共分为四栏,每一字段的意义是:
1. 群组名称:就是群组名称啦!
2. 群组密码:通常不需要设定,因为我们很少使用到群组登入! 不过,同样的,密码也是被纪录在 /etc/gshadow 当中啰!
3. GID:就是群组的 ID 啊~
4. 支持的账号名称:加入这个群组里面的所有的账号, 我们知道,一个使用者是可以加入多个群组的。举例来说,如果我想要让 dmtsai 也加入 root 这个群组,那么在第一行的最后面加上『,dmtsai』,注意不要有空格, 使成为『 root:x:0:root,dmtsai』就可以啰~
【/etc/gshadow】
内容有点像这样:
root:::root
bin:::root,bin,daemon
2. 密码栏,同样的,开头为 ! 表示无法登入;
3. 群组管理员的账号 (相关信息在后续介绍)
4. 该群组的所属账号 (与 /etc/group 内容相同!)
[root@linux ~]# groupadd [-g gid] [-r]
参数:
-g :后面接某个特定的 GID ,用来直接给予某个 GID ~
-r :建立系统群组啦!与 /etc/login.defs 内的 GID_MIN 有关。
范例一:新建一个群组,名称为 group1
[root@linux ~]# groupadd group1
范例二:新建一个系统群组,名称为 group2
[root@linux ~]# groupadd -r group2
【groupmod】
跟 usermod 类似的,这个指令仅是在进行 group 相关参数的修改而已。
[root@linux ~]# groupmod [-g gid] [-n group_name]
参数:
-g :修改既有的 GID 数字;
-n :修改既有的群组名称
【groupdel】
groupdel 自然就是在删除群组
[root@linux ~]# groupdel [groupname]
范例一:将刚刚的 groupname 删除!
[root@linux ~]# groupdel groupname
[root@linux ~]# passwd [useraccount]
范例一:如果 root 要帮 dmtsai 修改密码时?
[root@linux ~]# passwd dmtsai
参数:
-l :将 username 这个账号的密码锁住 (lock),在 /etc/shadow 内的密码栏修订~
-u :将 -l 的 lock 解开!
-n :后面接天数 (数字) ,最短天数;亦即是 /etc/shadow 内的第四栏;
-x :后面接天数 (数字) ,最长天数;亦即是 /etc/shadow 内的第五栏;
-w :后面接天数 (数字) ,警告天数;亦即是 /etc/shadow 内的第六栏;
-S :显示目前这个 username 的相关信息。
[root@linux ~]# su [-lcm] [username]
参数:
- :如果执行 su - 时,表示该使用者想要变换身份成为 root ,且使用 root 的
环境设定参数档,如 /root/.bash_profile 等等。
-l :后面可以接使用者,例如 su -l dmtsai ,这个 -l 好处是,可使用欲变换身份者
他的所有相关环境设定档。
-m :-m 与 -p 是一样的,表示『使用目前的环境设定,而不重新读取新使用者的设定档。』
-c :仅进行一次指令,所以 -c 后面可以加上指令喔!
当 su 后面没有加上使用者账号时, 那么预设就是以 root 作为你切换的那个身份啦;
这也会造成后来的 root 身份在执行时的困扰。
[dmtsai@linux ~]$ su - -c "head -n 3 /etc/shadow"
范例三:原本是 dmtsai 这个使用者,想要变换身份成为 vbird 时?
[dmtsai@linux ~]$ su -l vbird
[root@linux ~]# sudo [-u [username|#uid]] command
参数:
-u :后面可以接使用者账号名称,或者是 UID。例如 UID 是 500 的身份,可以:
-u #500 来作为切换到 UID 为 500 的那位使用者。
范例一:一般身份使用者使用 sudo 在 /root 底下建立目录:
[dmtsai@linux ~]$ sudo mkdir /root/testing
范例二:dmtsai 想要切换身份成为 vbird 来进行 touch 时?
[dmtsai@linux ~]$ sudo -u vbird touch /home/vbird/test
查询使用者: w, who, last, lastlog
【w 命令详解功能说明】:显示目前登入系统的用户信息。
linux w 命令补充说明:执行这项指令可得知目前登入系统的用户有那些人,以及他们正在执行的程序。单独执行 w 命令会显示所有的用户,您也可指定用户名称,仅显示某位用户的相关信息。
命令参数:
-f 开启或关闭显示用户从何处登入系统。
-h 不显示各栏位的标题信息列。
-l 使用详细格式列表,此为预设值。
-s 使用简洁格式列表,不显示用户登入时间,终端机阶段作业和程序所耗费的CPU时间。
-u 忽略执行程序的名称,以及该程序耗费CPU时间的信息。
-V 显示版本信息。
【who 命令详解】
功能说明:显示目前登入系统的用户信息。
语 法:who [-Himqsw][--help][--version][am i][记录文件]
补充说明:执行这项指令可得知目前有那些用户登入系统,单独执行who指令会列出登入帐号,使用的终端机,登入时间以及从何处登入或正在使用哪个X显示器。
参数:
-H或--heading 显示各栏位的标题信息列。
-i或-u或--idle 显示闲置时间,若该用户在前一分钟之内有进行任何动作,将标示成"."号,如果该用户已超过24小时没有任何动作,则标示出"old"字符串。
-m 此参数的效果和指定"am i"字符串相同。
-q或--count 只显示登入系统的帐号名称和总人数
【last说明】
功能说明:列出目前与过去登入系统的用户相关信息。
linux系统中last命令的作用是显示近期用户或终端的登录情况,它的使用权限是所有用户。通过last命令查看该程序的log,管理员可以获知谁曾经或企图连接系统。
格式
last [—R] [—n][-f file][-t tty] [—h 节点][-I —IP][—1][-y][ID]
主要参数
- R: 省略 hostname 的栏位
-n:指定输出记录的条数。
-f file:指定用文件file作为查询用的log文件。
-t tty:只显示指定的虚拟控制台上登录情况。
-h 节点:只显示指定的节点上的登录情况。
-i IP:只显示指定的IP上登录的情况。
-1:用IP来显示远端地址。
-y:显示记录的年、月、日。
-ID:知道查询的用户名。
-x:显示系统关闭、用户登录和退出的历史。
例如:
[root@linux ~]# last -6 #6条登录记录
【lastlog】 列出每个账号最后登录的时间和登录终端的地址,如果此用户从来没有登录,则显示:**Never logged in**
【使用者对谈: talk, mesg, wall】
write 直接将讯息传给接收者
举例来说,我们的 Linux 目前有 vbird 与 dmtsai 两个人在在线:
[vbird@linux ~]$ write dmtsai
Hi, How are you doing today....
<==这里按下 [ctrl]+d
此时,另一端的 dmtsai 在他的终端接口上就会出现该信息
如果 dmtsai 这个人不想要接受任何讯息, 直接下达这个动作:
[dmtsai@linux ~]$ mesg n
如果想要解开的话,再次下达『 mesg y 』就好啦!
wall 对所有系统上面的使用者传送简讯
例如:
[root@linux ~]# wall "I will shutdown the linux server about 5m later.
举例来说,我以 vbird 寄信给 dmtsai:
[vbird@linux ~]$ mail dmtsai
Subject: hello world
well done!
. <==这里很重要喔,结束时,最后一行输入小数点 . 直接 [Enter]即可!
EOT
如果是要收信呢?
假设我以 dmtsai 的身份登入主机,然后输入 mail 后,会得到什么?
[dmtsai@linux ~]$ mail
Mail version 8.1 6/6/93. Type ? for help.
"/var/spool/mail/dmtsai": 1 message 1 new
>N 1 [email protected] Fri Sep 2 23:53 16/552 "nice to meet you"
& <==这里可以输入很多的指令,如果要查阅,输入 ? 即可!