Map Reduce什么的我是不懂啊。 今天是帮马同学搭建hadoop。 用的2.2.0版本,结果运行时发现提示 “libhadoop.so.1.0.0 which might have disabled stack guard” 的警告。 Google了一下发现是因为 hadoop 2.2.0提供的是libhadoop.so库是32位的,而我们的机器是64位。 解决的办法就是重新在64位的机器上编译hadoop。 恰好马同学刚刚步入linux用户的行列,连机器上的Ubuntu都是新装的,因此,为了编译hadoop,一切都得从头配置。
目录
- 编译环境
- Java 环境配置
- 安装依赖包
- 安装配置 protobuf
- 安装配置 maven
- 创建新用户及用户组
- 编译 hadoop 2.2.0
- 安装配置 hadoop 2.2.0
编译环境
OS: Ubuntu 12.04 64-bit
hadoop version: 2.2.0
Java: Jdk1.7.0_45
java环境配置
空白的电脑,什么都没有啊
下载 jdk : http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
在 /usr/lib/下新建jvm文件夹,将刚下的压缩文件解压到/usr/lib/jvm/目录下
修改~/.bashrc 配置环境变量
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
更新一下,使其生效
$ source .bashrc
检查一下是否配置成功
$ java -version java version "1.7.0_45" Java(TM) SE Runtime Environment (build 1.7.0_45-b18) Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
安装依赖包
这些库啊包啊基本都会在编译过程中用到,缺少的话会影响编译,看到error了再找solution非常麻烦,提前装好一劳永逸。
$ sudo apt-get install g++ autoconf automake libtool cmake zlib1g-dev pkg-config libssl-dev
因为还要用到ssh,所以如果机器上没有的话,装个openssh的客户端就好啦 (ubuntu 12.04应该预装了)
$ sudo apt-get install openssh-client
当然想装server的话就
$ sudo apt-get install openssh-server
编译过程中还会用到protobuf 貌似需要最新的2.5.0,因此有低版本的也重新安装一下
安装配置 protobuf
下载最新的protobuf: https://code.google.com/p/protobuf/downloads/list
解压,依次运行
$ ./configure --prefix=/usr $ sudo make $ sudo make check $ sudo make install
检查一下版本
$ protoc --version libprotoc 2.5.0
安装配置 maven
ubuntu下用apt-get安装
$ sudo apt-get install maven
创建新用户及用户组
我们为hadoop创建一个新组叫“hadoop”,创建一个新用户叫“hduser”属于“hadoop”组 (网上都这么起名字,我们也跟风好了)
$ sudo addgroup hadoop $ sudo adduser --ingroup hadoop hduser
有了新用户以后,我们下面的操作就都要在新用户下完成了
$ su hduser
建立ssh信任
hadoop启动的时候要ssh访问localhost,建立信任关系省得老输密码
$ cd /home/hduser $ ssh-keygen -t rsa -P "" $ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
用命令验证一下是否可以免密码链接localhost
$ ssh localhost
这是没有给rsa密钥设密码的情况,但是我觉得吧,一般还是给个密码好,可以用ssh-agent管理,以后也不许要每次都输入
$ ssh-add ~/.ssh/id_rsa.pub# 参数写成公钥了,应该传私钥进去,感谢twlkyao提醒 $ ssh-add ~/.ssh/id_rsa
编译 hadoop 2.2.0
下载 hadoop 2.2.0 http://www.apache.org/dyn/closer.cgi/hadoop/common/
解压到用户目录 /home/hduser/. 进入 hadoop-2.2.0-src 目录
因为已经安装了maven, protobuf, java环境也有了,compiler也有了所以直接运行
$ mvn package -Pdist,native -DskipTests -Dtar
正常应该不会有什么错误了, 参数和其他编译选择请看 hadoop目录下的 BUILDING.txt文件
安装配置 hadoop 2.2.0
此时编译好的文件位于 hadoop-2.2.0-src/hadoop-dist/target/hadoop-2.2.0/ 目录中
1、安装ant,并输入ant -version测试可以正常工作
2、进入到eclipse插件包的eclipse-plugin的根目录下,路径是/home/lm/Downloads/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin
3、执行命令ant jar -Dversion=2.2.0 -Declipse.home=/home/lm/Downloads/eclipse -Dhadoop.home=/home/lm/Downloads/hadoop-2.2.0-src/hadoop-dist/target/hadoop-2.2.0。注意这两个路径,分别是eclipse的根路径,和hadoop2.2.0的根路径
4、最终的生成jar的路径在,/home/lm/Downloads/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.2.0.jar目录下
5、OK,至此已经成功完成,把此插件拷贝eclipse的插件目录下,重新启动eclipse即可。
三、配置Eclipse、Hadoop开发环境
第一步:安装Eclipse-Hadoophadoop集成插件
把hadoop-eclipse-plugin-1.1.1.jar插件放到/home/eclipse/plugins中,然后重新启动Eclipse如下图。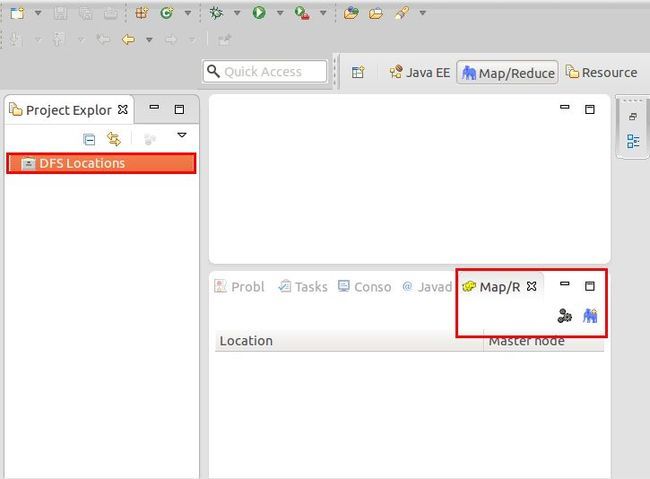
细心的你从上图左侧“Project Explorer”下面发现“DFS Locations”,说明Eclipse已经识别刚才放入的Hadoop Eclipse插件了。
第二步:在Eclipse中指定Hadoop的安装目录
选择“Window”菜单下的“Preference”,然后弹出一个窗体,在窗体的左侧中找到“Hadoop Map/Reduce”选项,点击此选项,选择Hadoop的安装目录(如我的Hadoop目录:/home/hadoop/hadoop-1.1.1)。结果如下图: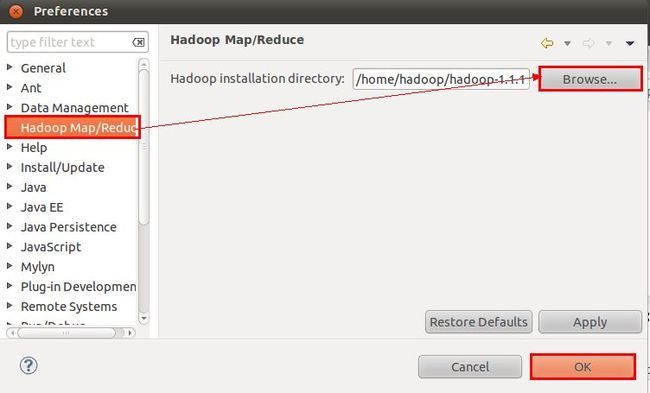
第三步:切换“Map/Reduce”工作目录
有两种方法:
1)、选择“Window”菜单下选择“Open Perspective–>Other”,弹出一个窗体,从中选择“Map/Reduce”选项即可进行切换。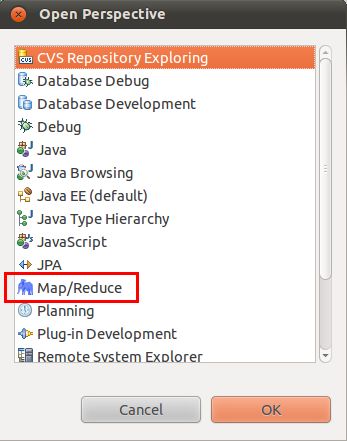
2)、在Eclipse软件的右上角,点击图标“”中的“”,从中选择“Map/Reduce”,然后点击“OK”即可确定。
{kind=link}
{kind=link}
切换到“Map/Reduce”工作目录下的界面如下图所示。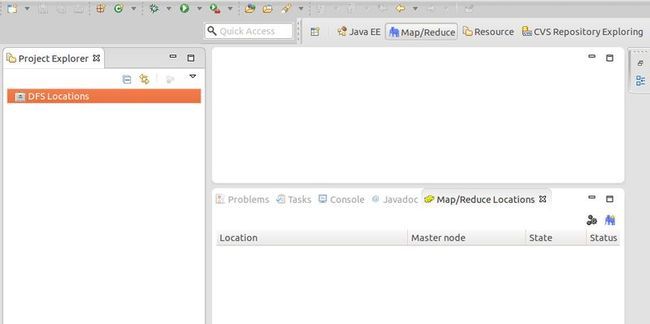
第四步:配置DFS Locations
建立与Hadoop集群的连接,在Eclipse软件下面的“Map/Reduce Locations”进行右击,弹出一个选项,选择“New Hadoop Location ”,然后弹出一个窗体。
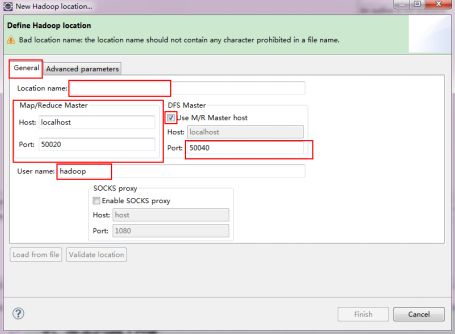
注意上图中的红色标注的地方,是需要我们关注的地方。
Location Name:可以任意填,标识一个“Map/Reduce Location”
Map/Reduce Master
Host:xx.xx.xx.xx(Master.Hadoop的IP地址,即/home/hadoop/hadoop-1.1.1/conf/mapred-site.xml中ip)
Port:xx(即/home/hadoop/hadoop-1.1.1/conf/mapred-site.xml中端口)
DFS Master
Use M/R Master host:前面的勾上。(因为我们的NameNode和JobTracker都在一个机器上。)
Host:xx.xx.xx.xx(/home/hadoop/hadoop-1.1.1/conf/core-site.xml中ip)
Port:xxxx (/home/hadoop/hadoop-1.1.1/conf/core-site.xml中端口)
User name:hadoop(操作hadoop的用户)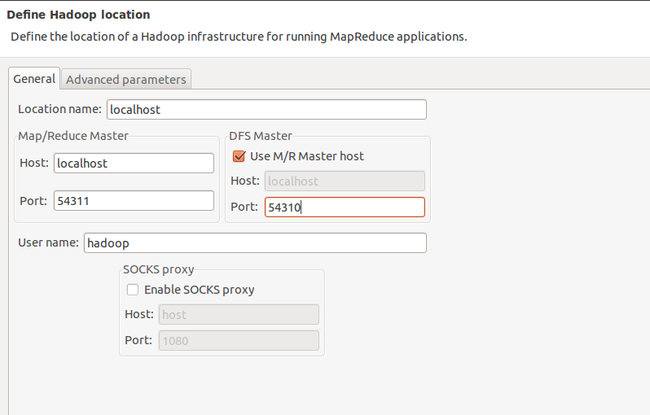
接着点击“Advanced parameters”从中找到“hadoop.tmp.dir”,修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是“/home/hadoop/hadoop-datastore/”,这个参数在“core-site.xml”进行了配置。
再从中找到“fs.default.name”,修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是“hdfs://localhost:54310”,这个参数在“core-site.xml”进行了配置。
点击“finish”之后,会发现Eclipse软件下面的“Map/Reduce Locations”出现一条信息, 就是我们刚才建立的“Map/Reduce Location ”。
第五步:查看HDFS文件系统
查看HDFS文件系统,点击Eclipse软件左侧的“DFS Locations”下面的“localhost”,就会展示出HDFS上的文件结构(记得要先启动hadoop,不然看不到效果)。
到此为止,我们的Hadoop Eclipse开发环境已经配置完毕。