参考:http://deerchao.net/tutorials/regex/regex.htm
package com.ydc.ln.codebase.java.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 参考:http://deerchao.net/tutorials/regex/regex.htm
*
* @ClassName RegexDemo
* @Description TODO
* @author ydc
* @date 下午8:46:14 2013-3-15
* @version V1.0
*/
public class RegexDemo {
// ------------------------------------------
// 元字符
// ------------------------------------------
/**
* hi后面不远处跟着一个Lucy : (\b)(.)(*)
*/
public static String pat01 = "\bhi\b.*\bLucy\b";
/**
* 中国的电话号码:(\d)
*/
public static String pat02 = "0\\d\\d-\\d\\d\\d\\d\\d\\d\\d\\d";
public static String pat02_1 = "0\\d{2}-\\d{8}";
/**
* 以字母a开关的单词
*/
public static String pat03 = "\\ba\\w*\\b";
/**
* 匹配刚好6个字符的单词
*/
public static String pat04 = "\\b\\w{6}\\b";
/**
* 匹配QQ号
*/
public static String pat05 = "^\\d{5,12}$";
// ------------------------------------------
// 字符转义
// ------------------------------------------
/**
* 查找元字符(.) 匹配deerchao.net
*/
public static String pat06 = "deerchao\\.net";
/**
* 匹配C:\Windows 注意(\)也需要转义
*/
public static String pat07 = "C:\\\\Windows";
// ------------------------------------------
// 重复
// ------------------------------------------
/**
* Windows后面跟1个或更多数字
*/
public static String pat08 = "Windows\\d+";
/**
* 匹配一行(或整个字符串)的第一个单词
*/
public static String pat09 = "^\\w+";
// ------------------------------------------
// 字符类
// ------------------------------------------
/**
* 匹配任何一个英文元音字母
*/
public static String pat10 = "[aeiou]";
/**
* 匹配标点符号(.?!)
*/
public static String pat11 = "[.?!]";
/**
* 一位数字:与(\d)代表含意一样
*/
public static String pat12 = "[0-9]";
/**
* 只考虑英文,等同于(\w)
*/
public static String pat13 = "[a-zA-Z0-9]";
/**
* 匹配几种格式的电话号码
*/
public static String pat14 = "\\(?0\\d{2}[) -]?\\d{8}";
// ------------------------------------------
// 分枝条件:正则表达式里的分枝条件指的是有几种规则,
// * 如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开
// ------------------------------------------
/**
* 匹配两种以连字号分隔的电话号码
* <p>
* 一种是三位区号,8位本地号 一种是四位区号,7位本地号
* </p>
*/
public static String pat15 = "0\\d{2}-\\d{8}|0\\d{3}-\\d{7}";
/**
* 匹配3位区号的电话号码:
* <p>
* 其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔
* </p>
*/
public static String pat16 = "\\(?0\\d{2}\\)?[- ]?\\d{8}|0\\d{2}[- ]?\\d{8}";
/**
* 匹配美国的邮政编码
* <p>
* 使用分枝条件时,要注意各个条件的顺序。
*
* 如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。
*
* 原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
* </p>
*/
public static String pat17 = "\\d{5}-\\d{4}|\\d{5}";
// ------------------------------------------
// 分组
// ------------------------------------------
/**
* 匹配简单的IP地址地址
*/
public static String pat18 = "(\\d{1,3}\\.){3}\\d{1,3}";
/**
* 正确的IP地址
*/
public static String pat19 = "((2[0-4]\\d|25[0-5]|[01]?\\d\\d?)\\.){3}(2[0-4]\\d|25[0-5]|[01]?\\d\\d?)";
// ------------------------------------------
// 反义
// * 查找不是某个字符或不在某个字符类里的字符的方法(反义)
// ------------------------------------------
/**
* 不包含空白符的字符串
*/
public static String pat20 = "\\S+";
/**
* 用尖括号括起来的以a开头的字符串
*/
public static String pat21 = "<a[^>]+>";
// ------------------------------------------
// 后向引用 使用小括号指定一个子表达式后,匹配这个子表达式的文本
// * 后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本
// ------------------------------------------
/**
* 匹配重复的单词,如:go go,或kitty kitty
*/
public static String pat22 = "\\b(\\w)\\b\\s+\\1\\\b";
/**
* 指定子表达式的组名
* <p>
* 把(\\w+)的组名指定为Word了
*
* (\k<Word>)引用这个分组捕获
*
* 尖括号可以换成('):(?'Word'\w+)
* </p>
*
*/
public static String pat23 = "(?<Word>\\w+)\\b\\s+\\k<Word>\\b";
// ------------------------------------------
// 零宽断言
// ------------------------------------------
/**
* (?=exp)也叫零宽度正预测先行断言
*
* 以ing结尾的单词的前面部分(除了ing以外的部分)
* <p>
* 如查找I'm singing while you're dancing.时,它会匹配sing和danc。
* </p>
*/
public static String pat24 = "\\b\\w+(?=ing\\b)";
/**
* (?<=exp)也叫零宽度正回顾后发断言
*
* 以re开头的单词的后半部分(除了re以外的部分)
* <p>
* 如在查找reading a book时,它匹配ading。
* </p>
*/
public static String pat25 = "(?<=\\bre)\\w+\\b";
/**
* 给一个很长的数字中每三位间加一个逗号(当然是从右边加起了)
* <p>
* 用它对1234567890进行查找时结果是234567890。
* </p>
*/
public static String pat26 = "((?<=\\d)\\d{3})+\\b";
/**
* 匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
*/
public static String pat27 = "(?<=\\s)\\d+(?=\\s)";
// ------------------------------------------
// 负向零宽断言
// 只是想要确保某个字符没有出现,但并不想去匹配它时
// ------------------------------------------
/**
* 匹配包含后面不是字母u的字母q的单词
* <p>
* 问题:如果q出现在单词的结尾的话,像Iraq,Benq,这个表达式就会出错
* </p>
*/
public static String pat28 = "\\b\\w*q[^u]\\w*\\b";
/**
* 负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。现在,我们可以这样来解决这个问题:。
*/
public static String pat28_2 = "\\b\\w*q(?!u)\\w*\\b";
/**
* 零宽度负预测先行断言(?!exp),断言此位置的后面不能匹配表达式exp。
* <p>
* 匹配三位数字,而且这三位数字的后面不能是数字
* </p>
*/
public static String pat29 = "\\d{3}(?!\\d)";
/**
* 匹配不包含连续字符串abc的单词。
*/
public static String pat30 = "\\b((?!abc)\\w)+\\b";
/**
* (?<!exp),零宽度负回顾后发断言来断言此位置的前面不能匹配表达式exp
* <p>
* 匹配前面不是小写字母的七位数字。
* </p>
*/
public static String pat31 = "(?<![a-z])\\d{7}";
/**
* 匹配不包含属性的简单HTML标签内里的内容
* <p>
* 请详细分析表达式(?<=<(\w+)>).*(?=<\/\1>),这个表达式最能表现零宽断言的真正用途。
* </p>
*/
public static String pat32 = "(?<=<(\\w+)>).*(?=<\\/\\1>)";
// ------------------------------------------
// 注释
// ------------------------------------------
/**
* 小括号的另一种用途是通过语法(?#comment)来包含注释。
*/
public static String pat33 = "2[0-4]\\d(?#200-249)|25[0-5](?#250-255)|[01]?\\d\\d?(?#0-199)";
// ------------------------------------------
// 贪婪与懒惰
// ------------------------------------------
/**
* 当正则表达式中包含能接受重复的限定符时,
*
* 通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符
* <p>
* 匹配最长的以a开始,以b结束的字符串。
*
* 如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
* </p>
*/
public static String pat34 = "a.*b";
/**
* 懒惰匹配,也就是匹配尽可能少的字符。
*
* 前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。
*
* 这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复
* <p>
* 匹配最短的,以a开始,以b结束的字符串。
*
* 如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)
*
* 正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权
* </p>
*/
public static String pat35 = "a.*?b";
// ------------------------------------------
// 平衡组/递归匹配
// ------------------------------------------
public static void main(String[] args) {
new RegexDemo().test01();
}
/**
*
* @Title: test01 void
* @throws
*/
public void test01() {
boolean result = false;
// result = Pattern.matches(pat16, "010)12345678");
result = Pattern.matches(pat26, "1234567890");
System.out.println(result);
}
public void demo() {
Pattern p = Pattern.compile("a*b");
Matcher m = p.matcher("aaaab");
boolean b = m.matches();
boolean b2 = Pattern.matches("a*b", "aaaab");
System.out.println(b + "\t" + b2);
}
}
平衡组/递归匹配
要求:
匹配像( 100 * ( 50 + 15 ) )这样的可嵌套的层次性结构
语法构造:
- (?'group') 把捕获的内容命名为group,并压入堆栈(Stack)
- (?'-group') 从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败
- (?(group)yes|no) 如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分
- (?!) 零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败
表达式:
< #最外层的左括号
[^<>]* #最外层的左括号后面的不是括号的内容
(
(
(?'Open'<) #碰到了左括号,在黑板上写一个"Open"
[^<>]* #匹配左括号后面的不是括号的内容
)+
(
(?'-Open'>) #碰到了右括号,擦掉一个"Open"
[^<>]* #匹配右括号后面不是括号的内容
)+
)*
(?(Open)(?!)) #在遇到最外层的右括号前面,判断黑板上还有没有没擦掉的"Open";如果还有,则匹配失败
> #最外层的右括号
注:为了避免(和\(把你的大脑彻底搞糊涂,用尖括号代替圆括号,
问题变成:问题变成了如何把xx <aa <bbb> <bbb> aa> yy这样的字符串里,最长的配对的尖括号内的内容捕获出来?
平衡组的一个最常见的应用就是匹配HTML
下面这个例子可以匹配嵌套的<div>标签:
<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>
相关截图:
===========================================================================
表1.常用的元字符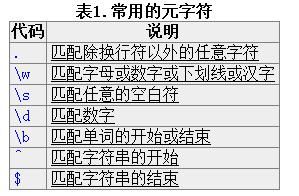
表2.常用的限定符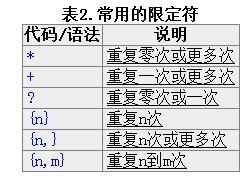
表3.常用的反义代码
表4.常用分组语法
表5.懒惰限定符
表6.常用的处理选项
表7.尚未详细讨论的语法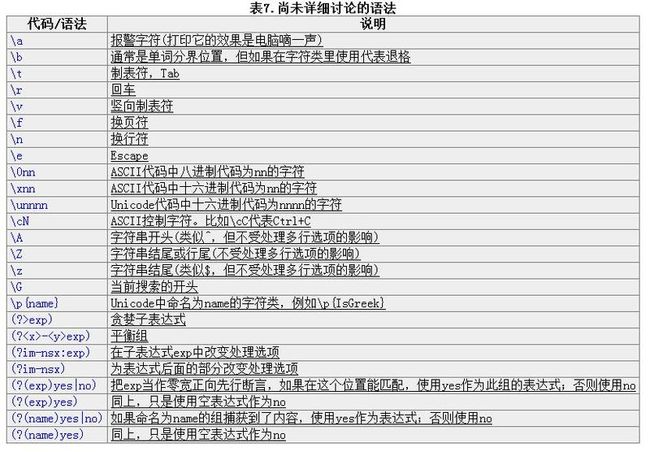
-----------------------------------------------------------------------------------------------------------------
@author Free Coding http://ln-ydc.iteye.com/