Cassandra Vs Voldemort
目的
在Medallia,我们的系统目前有一个关键组件是运行在一个开源的关系型数据库上.由于此组件主要通过主键来查询数据库的条目,我们想尝试将此组件切换到一个键值存储系统上,以利用键值系统提供的多种好处,包含分布式复制、负载均衡以及失败切换.对此组件进行重构以实现纵向扩展是我们的一个目标,附带的其它好处是,可以缓解我们目前较高的磁盘存储需求.
最近,我们花了部分时间来研究这项技术(以及部分其他技术改进,Medallia激动人心的时刻!),考察了多个不同选项.长话短说,最终落在以下两个选择上:Apache Cassandra 与Project Voldemort .
这两个项目看似是他们所在开源类别中最成熟的了,都可以提供内置的分散化集群支持,包含分区、容错性以及高可用性.两者都是基于Amazon的Dynamo论文 ,主要的差异是,Voldemort遵循简单的键值模型,而Cassandra使用了基于BigTable 持久化模型的面向列的模型.两者都支持读一致性,也就是读操作总是返回最新的数据,这一点是我们业务所需要的.
高层次的比较
Project Voldemort
虽然不是一份详尽的清单,下面是我们考查这两个存储系统最关心的优势与劣势.
- 优势
- 更简单的API
- 基于Berkley DB的持久化,一个成熟并广泛使用的键值DB
- 使用向量时钟而不是简单的时间戳.它不需要节点(客户端)的时钟保持同步.
- 劣势
- 没有内置的”多数据中心”相关路由支持(意味着至少有一个额外的数据中心有此数据的一份拷贝)
Apache Cassandra
- 优势
- 更广泛的生产系统部署(Facebook、Twitter、Digg、Rackspace)
- 更丰富的API,值可以支持动态的列结构(Schema-free).列可以独立演化,意味着你不需要读出整个结构就可以更新其中的一列.
- 为写操作做过专门优化(设计上).
- 可配置的一致性级别(在每个请求上指定)
- 劣势
- 文件格式仍在开发中,内部结构仍然可能会发生变化.鉴于它所支持的灵活性,文件格式更加复杂也更加难以理解,在性能方面尤其如此
- 需要同步时钟(NTP)(节点与客户端都需要)
- 与竞争产品相比,读操作更加磁盘密集
- 不支持客户端的冲突检测,因此最近的数据总是赢家
性能测试
令我们吃惊的是,这是 我们找到的对这两个项目的进行性能比较的唯一链接,因此,我们决定写这篇文章来分享我们的研究.我们使用了vpork 的测试框架,对它的代码做了修改以适应我们的需求,升级客户端代码到最新版本、添加热身阶段、增加了重写能力。下面是我们测试的结果.
配置:
- 版本
- Voldemort v0.80.1
- Cassandra 0.6.0-beta3
- 机器-3个类似与如下配置的节点
- 最大4GB的堆大小(heap size)
- 复制参数: N=3(每个条目的副本数),R=2(每次读时需要等待返回的节点数),W=2(每次写需要等待响应的节点数)
- 每台服务器上有8个处理器(Intel(R) Xeon(R) CPU E5504 @2.00GHz)
- 1TB的磁盘空间(Seagate ST31000340NS,7200rpm,32MB Cache)
- 持久化参数
- Voldemort(默认值)
- Key-serializer: String
- Value-serializer : identity(字节数组)
- persistence=bdb(Berkley DB)
- Cassandra
- ColumnFamily定义: CompareWith=”BytesType” RowsCached=”10000″
- ReplicationFactor=3
- Partitioner=org.apache.cassandra.dht.RandomPartitioner
- ConcurrentReads=16
- ConcurrenWrites=32
- Voldemort(默认值)
- 测试
- 客户端线程数: 40
- 初始加载:500万记录-每次测试开始前就有的记录数
- 热身:2万记录-在记录测试时间前的初始化写操作
- 每次测试的操作次数:50万
我们测试以下4种不同的写-重写-读配置.一次写操作等价于一个包含一条新记录(不存在的Key)的put操作.一次重写操作是一个包含已有Key的put操作.一次读是对一个已有Key的get操作.下面是我们测试的配置:
- 50% Write 50% Read
- 10% Write 40% Rewrite 50% Read
- 50% Rewrite 50% Read
- 90% Rewrite 10% Read
所有这些测试,我们都测试两组不同的Value大小,15KB与1.5KB.虽然我们评估了不同的选项,但是,对于我们的需求来讲,最后一种配置以及15KB的数据条目大小才是最具代表性的场景.
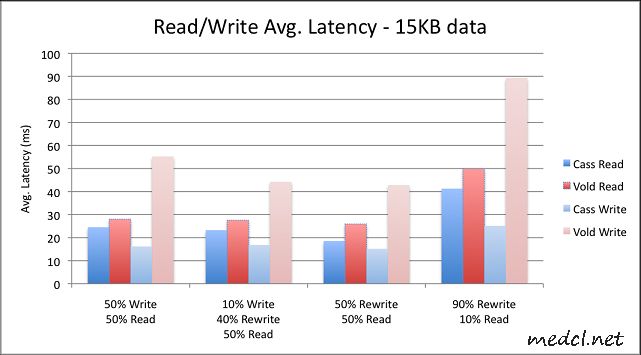
第一组图表展示延时(Latency),或者说是每个读写操作在每种情况下完成所需的平均时间.值越低越好.与预期一致,Cassandra的写操作(或重写)时间总是优于Voldemort,随着场景的不同读操作时间有点变化,不过总体上两者相差不大.

第二组图显示99%条件下的最大延时时间;仍然是值越小越好:
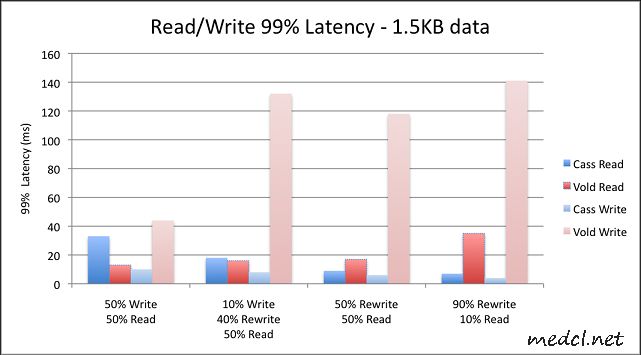
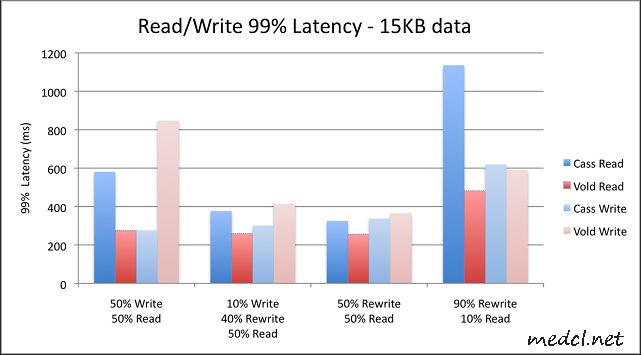
在前端,我们有一个写回高速缓存,这意味着写操作不会影响用户体验.另一方面,读操作直接与页面加载有关系.这也是为什么我们特别关注Cassandra在最后一个场景中处理15KB数据的峰值时间.我们还做了一些更进一步的测试,来度量99.9%与99.99%条件下的情况,差异更加明显:在99.9%时,Cassandra需要5050ms,Voldemort需要748ms,在99.99%时,Cassandra需要9176ms,Voldemort需要1129ms.这个巨大的差异是影响我们决策的一个关键指标.
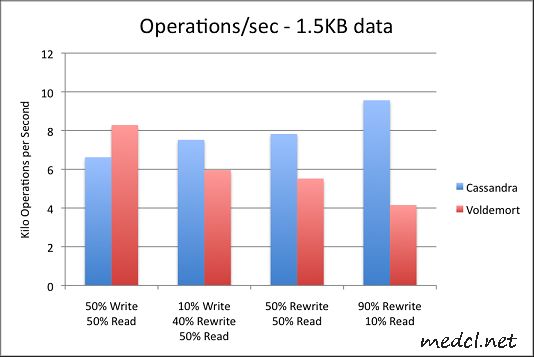
最后这两个图表展示每秒操作数(读/写)的吞吐量.在这两个图中,值越大越好:
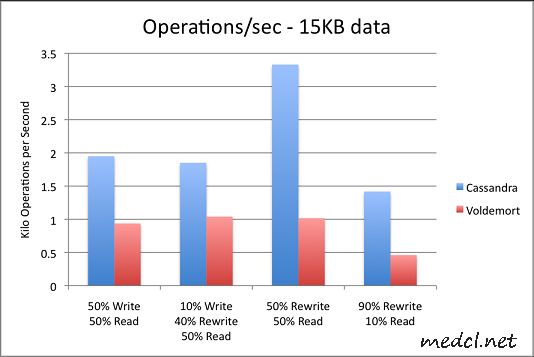
附注:
- Cassandra建议将Commit log与数据目录分别存储在不同的磁盘上以提高性能,我们的测试使用的都是同一块磁盘.
在测试过程中发现的问题:
- 如果在不同的线程中调用同一个Key,Voldemort的client.put(K key,V value)(不是取出特定版本对象的那个方法)会抛出异常ObsoleteVersionException. javadoc的表述是”关联这个Key的给定值,覆盖这个key之前已经存储的任何值”,因此这个错误是预料之外的.
最后的赢家是…
大体上,我认为没有明确的赢家.最佳选择依赖于多个因素,这需要每个公司自己去评估.我的偏好也在考查与测试过程中发生了多次变化.
已经说过,我们必须做出选择,并且最后决定选择使用Project Voldemort.主要的原因是简单、更好的版本控制、成熟的持久化层,以及延时
的可预测性.
我们现在已经开始开发新的解决方案,在我们将其应用到生产环境可能还需要一段时间,但是,我们想要将我们的初步成果与所有考虑这两个选项之一的人共享,这样,他们在做决策的时候就可以多一个参考.
我将对持续关注它的走向.
Diego Erdody
Lead Software Engineer
原文:http://log.medcl.net/item/2010/06/cassandra-vs-voldemort/