在进行文本文件的处理时,有时需要从已经分组的数据中去除重复的行,当文件较大无法放入内存时会更为麻烦。集算器的分组运算支持丰富的选项,同时支持文件游标读取整组数据,易于实现此类算法,下面通过例子来看一下具体作法。
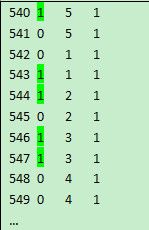
文件EPRom.log有4列,列之间以tab分隔,数据已按第二列分组。现在要去除数据中重复的行(只保留各组的第一行)。部分源数据如下:
集算器代码:
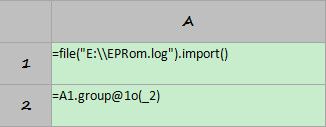
A1=file("E:\\EPRom.log").import()
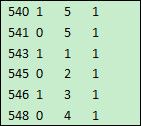
这句代码用来将文件读入内存,默认分隔符是tab,默认列名依次是_1,_2,_3……如果文件来自csv文件,则应当指定分隔符,代码形如:import(;”,”)。如果文件的第一行包含列名,则可用选项t读入列名,代码形如import@t()。A1的计算结果如下:
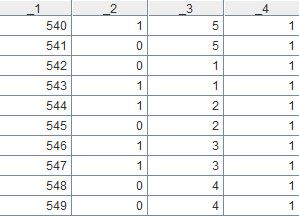
A2=A1.group@1o(_2)
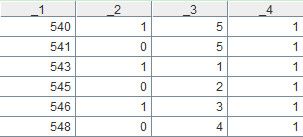
这句代码用来取出A1中各组数据的第1条,分组字段是_2,即第2个字段。A2就是本案例的最终计算结果,如下:
函数group默认情况下可对数据重新分组,比如代码A1.group(_2)会将A1按照第2个字段分为两组,如下: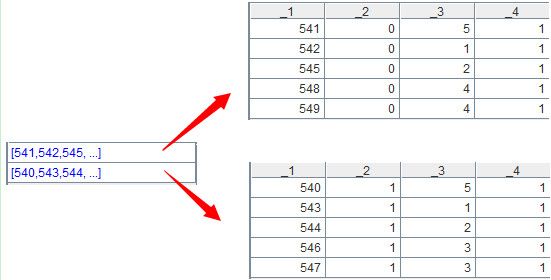
使用选项@o时,函数group不重新分组,比如代码A1.group@o(_2)的结果如下:
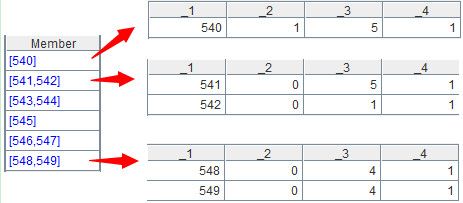
使用选项@1时,函数group会取出各组的第1条,选项@1和@o连用,即可获得本案例的计算目标。
当文件太大无法放入内存时,可以使用集算器游标来解决问题,代码如下:

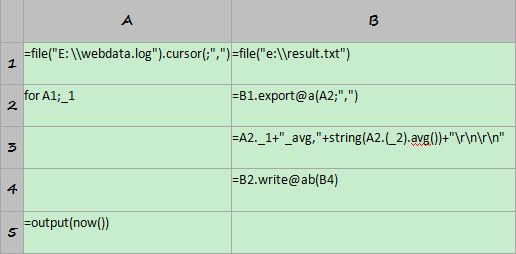
A1=file("E:\\EPRom.log").cursor()
这句代码以游标的方式打开日志文件。函数cursor表示根据文件对象返回游标对象,默认分隔符是tab,默认列名是_1,_2…_n。值得注意的是,这句代码只是建立游标对象,并没有读入数据,实际的读入动作会在遇到语句for或函数fetch时触发。
B1= file("e:\\result.txt")
这句代码新建文件对象,将来可写入计算结果。
A2:for A1;_2
这句代码对游标A1进行循环读数,每次读入第2列(列名为_2)相同的一组数据,此时数据才会真正读入内存。
注意这里的for 语句。集算器有for cs,n这样的写法,这表示每次读入游标cs中的n条记录。而for cs;x表示每次读入游标cs中的一组记录,每组记录的x字段相同,数据需要按照x事先分组。
语句for cs;x中的x也可以是表达式,即:每次读入多条数据,直到表达式x发生变化,比如:for A1 ; floor(_1/5)。这句代码会对字段_1除5后取整,如果未发生变化,集算器就会把这些记录归为一组。比如第1条到第5条就是同组数据。
B2=file("e:\\result.txt").export@a([A2(1)])
这是for语句A2的循环体,用来对每组数据进行同样的数据处理,具体算法是:取出当前组中的第1条,追加到文件result.txt中。代码中的A2代表循环变量,可以表示当前组对应的所有记录。A2(1)表示A2中的第1条记录。函数export用来将结构化数据写入文件,@a表示追加写。由于A2(1)是单条记录,不是数组,因此要用运算符[]来转换类型。
打开result.txt,可以看到本案例的最终结果:
集算器中for语句的作用范围用缩进就可以表示,而无需用括号或begin/end等标记。比如下面的代码中,B2-B5就是A2的作用范围。