最近在项目中使用了开源OLAP引擎——Mondrian实现一个多维分析系统,在项目后期系统优化阶段使用了Mondrian中的聚合表机制。这里结合 Mondrian官方资料和个人使用经验,对Mondrian中聚合表的概念、应用场景、如何使用、注意事项等内容做一个总结。
1. OLAP相关概念
Mondrian是一个基于Java语言的开源OLAP引擎,它通过MDX语句执行查询,从关系型数据库RDBMS中读取数据,以多维度的形式展示查询结果。
Mondrian通过Schema来定义一个多维数据库,它是一个逻辑概念上的模型,其中包含Cube(立方体)、Dimension(维度)、Hierarchy(层次)、Level(级别)、Measure(度量),这些被映射到数据库物理模型。Mondrian中Schema是以XML文件的形式定义的。
- Cube(立方体)是一系列Dimension和Measure的集合区域,它们共用一个事实表。
- Dimension(维度)是一个Hierarchy的集合,维度一般有其相对应的维度表,它由Hierarchy(层次)组成,而Hierarchy(层次)又是由组成Level(级别)的。
- Hierarchy(层次)是指定维度的层级关系的,如果没有指定,默认Hierarchy里面装的是来自立方体中的真实表。
- Level(级别)是Hierarchy的组成部分,使用它可以构成一个结构树,Level的先后顺序决定了Level在结构树上的位置,最顶层的 Level 位于树的第一级,依次类推。
- Measure(度量)是我们要进行度量计算的数值,支持的操作有sum、count、avg、distinct-count、max、min等。
概括总结一下:在多维分析中,关注的内容通常被称为度量(Measure),而把限制条件称为维度(Dimension)。多维分析就是对同时满足多种限制条件的所有度量值做汇总统计。包含度量值的表被称为事实表(Fact Table),描述维度具体信息的表被称为维表(Dimension Table),同时有一点需要注意:并不是所有的维度都要有维表,对于取值简单的维度,可以直接使用事实表中的一列作为维度展示。
下面是Mondrian中一个简单的Schema文件:
<Schema> <Cube name="Sales"> <Table name="sales_fact_1997"/> <Dimension name="Gender" foreignKey="customer_id"> <Hierarchy hasAll="true" allMemberName="All Genders" primaryKey="customer_id"> <Table name="customer"/> <Level name="Gender" column="gender" uniqueMembers="true"/> </Hierarchy> </Dimension> <Dimension name="Time" foreignKey="time_id"> <Hierarchy hasAll="false" primaryKey="time_id"> <Table name="time_by_day"/> <Level name="Year" column="the_year" type="Numeric" uniqueMembers="true"/> <Level name="Quarter" column="quarter" uniqueMembers="false"/> <Level name="Month" column="month_of_year" type="Numeric" uniqueMembers="false"/> </Hierarchy> </Dimension> <Measure name="Unit Sales" column="unit_sales" aggregator="sum" formatString="#,###"/> <Measure name="Store Sales" column="store_sales" aggregator="sum" formatString="#,###.##"/> <Measure name="Store Cost" column="store_cost" aggregator="sum" formatString="#,###.00"/> <CalculatedMember name="Profit" dimension="Measures" formula="[Measures].[Store Sales] - [Measures].[Store Cost]"> <CalculatedMemberProperty name="FORMAT_STRING" value="$#,##0.00"/> </CalculatedMember> </Cube> </Schema>
其中包含一个名为“Sales”的Cube,立方体中有两个维度:“Gender”和“Time”,两个度量值:“Unit Sales”和“Store Sales”。有关Mondrian的Schema文件的具体编写规则,可以参考官方文档:如何编写Schema。
2. 什么是聚合表
下图描述了一个数据库的结构。该数据库中共有五张表,分别是:Sales表,Customer表,Time表,Product表和Mfr表。这个数据库的作用是存储每一笔交易:包括这笔交易发生在什么时间,交易的产品类型,进行交易的客户信息,交易方式,交易了多少件产品以及成交金额是多少。
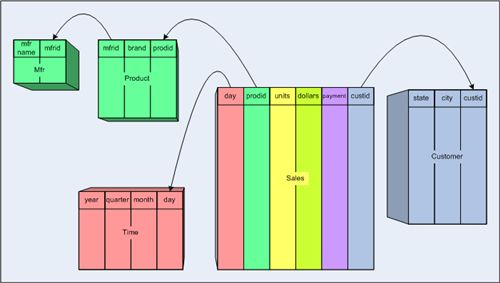
星型模型中有一张事实表(Sales),两个度量列(units和dollars),四个维度表(Product, Mfr, Customer, Time)。在这个星型模型的最顶层,我们创建了以下多维模型:
- [Sales]立方体包含[Unit sales]和[Dollar sales]两个度量值;
- [Product]维度包含[All Products],[Manufacturer],[Brand],[Prodid]四个级别;
- [Time]维度包含[All Time],[Year],[Quarter],[Month],[Day]五个级别;
- [Customer]维度包含[All Customers],[State],[City],[Custid]四个级别;
- [Payment Method]维度包含[All Payment Methods],[Payment Method]两个级别。
其中,大部分维度都有一个对应的维度表,除了两个地方:[Product]维度是一个雪花维度,它会把Product和Mfr两张表展开;[Payment Method]维度是一个退化的维度,直接使用事实表中的payment列作为维度属性,因此不需要一个单独的维表。
假设现在我们要对交易做一些统计,例如,某一件特定产品在某一个时间段内以某种特定方式总共卖出多少件或多少钱,这时成交产品数和成交金额是我们最终关注的内容,其他的因素例如时间、产品、方式等都只是对我们最终关注内容进行统计的限制条件。
在上面的例子中,限制条件有时间、产品类型、用户类型和交易方式,有时我们并不需要同时使用所有的限制条件,例如,当我们只想知道指定产品的成交总金额时,那么除了产品类型之外其他三个限制条件都是多余的,而在查询时,需要在整个事实表中执行查询,找出产品类型为指定类型的所有产品然后再做统计,为了提高查询效率,我们可以新建一张表,这张表按照产品类型把事实表中的行合并到一起,合并的方式是抛弃其他维,把度量值按特定的方式(max,min,sum,count或avg)整合到一起。这种表被叫做聚合表(Aggregate Table)。
3.聚合表的应用场景
事实表中的行构成了一个集合,每一维(或若干维)按照其取值的不同可以将事实表这个全集划分成若干个不相交的子集。聚合表所做的工作实际上就是把划分出的子集归为数据库表中的一行,这样做一方面可以减少数据库表的行数,另一方面也省去了查询时所需要做的一些统计工作,从而提高查询时的效率。
4. 如何在Mondrian中使用聚合表
在Mondrian应用中加入聚合表需要进行以下工作:
4.1. 定义聚合表
在Mondrian中,一张事实表可以有多张聚合表,但每个聚合表只对应一个事实表。目前Mondrian中支持两种聚合表:lost dimension和collapsed dimension。
1. lost dimension
lost dimension表示有维度完全消失的聚合表,举个例子,例如一个包含有时间、地域、产品三个维度,以及度量值sales的立方体,那么如果有一个聚合表不包含维度,那么就被称为lost dimension,这里度量sales会被聚合为所有地域下的值。一个聚合表可以把所有维度都消失掉,这个聚合表将只包含一行记录,代表所有时间、地域、产品维度下的sales总和。
fact table
time_id
product_id
location_id
measure
lost (location_id) dimension table
time_id
product_id
measure (aggregated over location)
fact_count
fully lost dimension table
measure (aggregated over everything)
fact_count
其中,聚合表中的fact_count列是一个附加列,表示事实表中有多少行记录被聚合到了聚合表中的这一行。
2. collapsed dimension
collapsed dimension表示有维度被退化的聚合表,所谓退化是指某个维度在聚合表中只包含了这个维度的若干级别(Level)。举个例子,时间维度下包含了day,month,quarter,year级别,而在聚合表中退化成了只包含month这个级别,那么聚合表中不会包含time_id列,而是包含month,quarter和year列。当MDX查询语句可以用到这个聚合表时,就不再查询时间维度的维表,而是直接通过聚合表查询所有有关时间的信息(month,quarter和year)。
time dimension table
time_id
day
month
quarter
year
fact table
time_id
measure
collapsed dimension table
month
quarter
year
measure (aggregated to month level)
fact_count
4.2. 数据库中创建聚合表
在创建聚合表时,只对聚合表的表名称和列名称有所要求。聚合表的名称以它所对应的事实表的名称为后缀。聚合表的名称由三部分组成:
- agg_[第二部分]_[对应的事实表的名字]
其中,第二部分原则上的要求是至少包含一个字符,可以以字母、数字或下划线,但通常会用第二部分说明聚合表的类型并且对聚合表进行编号。例如,事实表的名称是customer,那么下面这些都是合法的、对应于该事实表的聚合表名:
- agg_01_sales
- agg_02_sales
- agg_l_01_sales
- agg_l_02_sales
- agg_c_01_sales
- agg_lc_01_sales
通常,我们会使用类似后面四个这样的聚合表名,在聚合表名的第二部分,首先是l或c或lc(分别表示包含lost dimension,collapsed dimension或者同时包含两者的聚合表),然后是一个下划线,接着后面是聚合表的数字编号。
在给聚合表的列命名时,只要使聚合表中的列名称和类型与事实表或维表中对应列的名称一致即可。除此之外,在聚合表中必须新加一列,这一列的名称会由Schema中的<AggFactCount>标签所指定(下面会有详细说明),这一列的作用是统计聚合表中一行聚合了事实表中的行的数目。
另外,聚合表还可以增加一些度量值,增加的度量值所在列的名字由度量方法(sum, max, min, avg)加下滑线再加对应的事实表中的列名字组成。例如,在上图中的事实表有一个名为units的度量值,在聚合表中如果我们想对这个值求和,那么聚合表中保存对units求和结果的列的名字就可以被命名为sum_units。更具体的内容可以参考:聚合表与事实表的表名和列名匹配规则。
聚集表必须被构建,一般来说,聚合表示非实时的,它们需要被重新构建,例如每天凌晨重新构建一次,供第二天分析。
下面是个简单的例子,这里有一张sales_fact_1997事实表:
sales_fact_1997
product_id
time_id
customer_id
promotion_id
store_id
store_sales
store_cost
unit_sales
首先我们构建一个时间维度消失了的lost dimension聚合表:
CREATE TABLE agg_l_05_sales_fact_1997 (
product_id INTEGER NOT NULL,
customer_id INTEGER NOT NULL,
promotion_id INTEGER NOT NULL,
store_id INTEGER NOT NULL,
store_sales DECIMAL(10,4) NOT NULL,
store_cost DECIMAL(10,4) NOT NULL,
unit_sales DECIMAL(10,4) NOT NULL,
fact_count INTEGER NOT NULL);
CREATE INDEX i_sls_97_cust_id ON agg_l_05_sales_fact_1997 (customer_id);
CREATE INDEX i_sls_97_prod_id ON agg_l_05_sales_fact_1997 (product_id);
CREATE INDEX i_sls_97_promo_id ON agg_l_05_sales_fact_1997 (promotion_id);
CREATE INDEX i_sls_97_store_id ON agg_l_05_sales_fact_1997 (store_id);
INSERT INTO agg_l_05_sales_fact_1997 (
product_id,
customer_id,
promotion_id,
store_id,
store_sales,
store_cost,
unit_sales,
fact_count)
SELECT
product_id,
customer_id,
promotion_id,
store_id,
SUM(store_sales) AS store_sales,
SUM(store_cost) AS store_cost,
SUM(unit_sales) AS unit_sales,
COUNT(*) AS fact_count
FROM
sales_fact_1997
GROUP BY
product_id,
customer_id,
promotion_id,
store_id
接下来构建一个collapsed dimension聚合表,其中时间维度退化为月级别:
CREATE TABLE agg_c_14_sales_fact_1997 (
product_id INTEGER NOT NULL,
customer_id INTEGER NOT NULL,
promotion_id INTEGER NOT NULL,
store_id INTEGER NOT NULL,
month_of_year SMALLINT(6) NOT NULL,
quarter VARCHAR(30) NOT NULL,
the_year SMALLINT(6) NOT NULL,
store_sales DECIMAL(10,4) NOT NULL,
store_cost DECIMAL(10,4) NOT NULL,
unit_sales DECIMAL(10,4) NOT NULL,
fact_count INTEGER NOT NULL);
CREATE INDEX i_sls_97_cust_id ON agg_c_14_sales_fact_1997 (customer_id);
CREATE INDEX i_sls_97_prod_id ON agg_c_14_sales_fact_1997 (product_id);
CREATE INDEX i_sls_97_promo_id ON agg_c_14_sales_fact_1997 (promotion_id);
CREATE INDEX i_sls_97_store_id ON agg_c_14_sales_fact_1997 (store_id);
INSERT INTO agg_c_14_sales_fact_1997 (
product_id,
customer_id,
promotion_id,
store_id,
month_of_year,
quarter,
the_year,
store_sales,
store_cost,
unit_sales,
fact_count)
SELECT
BASE.product_id,
BASE.customer_id,
BASE.promotion_id,
BASE.store_id,
DIM.month_of_year,
DIM.quarter,
DIM.the_year,
SUM(BASE.store_sales) AS store_sales,
SUM(BASE.store_cost) AS store_cost,
SUM(BASE.unit_sales) AS unit_sales,
COUNT(*) AS fact_count
FROM
sales_fact_1997 AS BASE, time_by_day AS DIM
WHERE
BASE.time_id = DIM.time_id
GROUP BY
BASE.product_id,
BASE.customer_id,
BASE.promotion_id,
BASE.store_id,
DIM.month_of_year,
DIM.quarter,
DIM.the_year
4.3. 在Schema中声明聚合表
在Schema中声明聚合表时,需要把声明内容放到<table>标签中。声明聚合表时常用的标签及其含义如下:
<AggName> 和一个聚合表的声明相关的内容都放在这个标签内,并且通过这个标签的name属性,可以把这部分声明与数据库中的一个聚合表对应起来。例如,数据库中有一个聚合表的名字为:agg_l_01_sales,那么在Schema中可以这样声明这个聚合表:<AggName name=”agg_l_01_sales”> … </AggName>,其中…表示声明的其他部分,这部分由下面的一个或若干个标签组成,下面的标签都在<AggName>中使用,并且它们是平级的,不会相互出现在其他标签内。
<AggFactCount> 通过这个标签的column属性可以指定一个聚合表中用来统计每一行聚合了事实表中多少行的列的名字,例如:<AggFactCount name=”fact_count” />表示在这个聚合表中用一个名为fact_count的列来统计聚合表的一行聚合了事实表的多少行。
<AggForeignKey> 这个标签用来把事实表中的一个外键同聚合表中含义相同的标签匹配起来,例如<AggForeignKey factColumn=”product_id” aggColumn=”product_id” />表示在事实表中有一个外键product_id,而在该事实表所对应的聚合表中与它功能相同(是同一张维表的主键)的外键名字是 product_id。其中factColumn指定事实表中外键的名字,aggColumn指定聚合表中相匹配的外键的名字。
<AggLevel> 如果聚合表中的维不是一个外键,那么需要用这个标签来声明聚合表中的这一维。这里举两个例子来说明它的用法:
当聚合表中的这一维也是事实表中的一维时(例如上图中payment那一列),可以这样写:
<AggLevel name=”[Payment Method].[Payment Method]” column=”payment”/>
其中name属性由两部分组成,首先是事实表的这一维在Schema中声明时的维的名称(由<Dimension>标签的name属性所指定),然后加上一个.最后再加上这一维的层次结构(Hierarchy)的名字(由<Dimension>标签内的<Hierarchy>标签的name属性所指定)即可。而column属性则是聚合表中这一列的名字,此处标签只指定聚合表中列的名字而 没有指定事实表中相对应列的名字是因为Mondrian会根据列名字匹配规则自动在事实表中查找相匹配的列。
当聚合表中的这一维是维表中的一维时(例如上图中month那一列),与上一种情况写法完全相同即可,并不因为聚合表中这一列对应的是维表中的列而有所不同:
<AggLevel name=”[Time].[Month]” column=”month”/>
<AggMeasure> 用来声明聚合表中度量值和事实表中度量值的匹配关系,例如:
<AggMeasure name=”[Measures].[Dollar Sales]” column=”sum_dollars”/>
其中的name属性的写法是[Measures].后面跟上度量值在Schema中声明时所使用的名字,它由<Measure>标签中的name属性所指定。而column的值是聚合表中一列的名字。
5. 在Mondrian中使用聚合表的注意事项
5.1. 在什么情况下Mondrian会使用聚合表
当需要查询的度量值的维是一张聚合表所包含的维的子集时,这张聚合表就可能会被使用。这里说可能被使用是因为其他聚合表可能也满足使用条件,这时 Mondrian会首先选择满足条件且维数与行数之乘积最少的聚合表,如果有多张满足条件的聚合表维数相同,Mondrian会选择一个行数最少的聚合 表。如果没有聚合表满足条件,Mondrian会从事实表中进行查询。详细内容参考Mondrian配置属性:mondrian.rolap.aggregates.ChooseByVolume。
5.2. Mondrian的聚合表与事实表数据同步的问题
一般来说,事实表中的数据是静态不变的,目前,Mondrian并不提供聚合表和事实表同步的机制,聚合表的数据需要自己批量导入后计算生成。
也就是说,当事实表被修改时,Mondrian不会对聚合表做相应的更改,Mondrian不提供根据事实表向聚合表中导入数据和同步数据的功能。因此,如果自己的应用场景中事实表中数据是动态变化的,就需要自己考虑如何做到事实表和聚合表的同步更新。
6. Mondrian中聚合表的例子
6.1. 第一个例子
建立一个聚合表Agg_1,结构如下图所示:
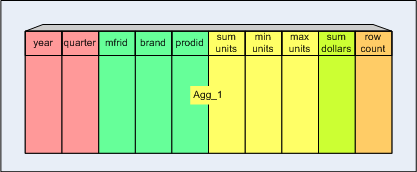
其中,
- Time维度被退化,只提取year、quarter列,忽略month和day列;
- Product相关的两个维度也在聚合表中被退化;
- Customer维度被丢掉;
- 对于事实表中的每个度量列(units,dollars),聚合表中可以有一个或多个聚合列(sum units,min units,max units,sum dollars);
- 同时聚合表中还有个度量列row count,表示出现的次数。
聚合表Agg_1对应的Schema声明如下:
<Cube name="Sales"> <Table name="sales"> <AggName name="agg_1_sales"> <AggFactCount column="row count"/> <AggMeasure name="[Measures].[Unit Sales]" column="sum units"/> <AggMeasure name="[Measures].[Min Units]" column="min units"/> <AggMeasure name="[Measures].[Max Units]" column="max units"/> <AggMeasure name="[Measures].[Dollar Sales]" column="sum dollars"/> <AggLevel name="[Time].[Year]" column="year"/> <AggLevel name="[Time].[Quarter]" column="quarter"/> <AggLevel name="[Product].[Mfrid]" column="mfrid"/> <AggLevel name="[Product].[Brand]" column="brand"/> <AggLevel name="[Product].[Prodid]" column="prodid"/> </AggName> </Table> <!-- Rest of the cube definition --> </Cube>
6.2. 第二个例子
建立一个聚合表Agg_2,结构如下图所示:
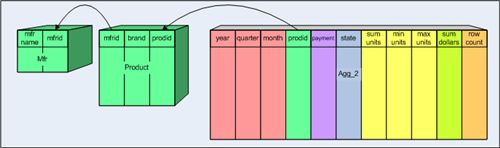
其中,
- Time维度被退化为year、quarter和month级别;
- Customer维度被退化为state级别;
- Payment Method被退化为Payment Method级别;
- Product维度保持了原始的雪花模型关系。
聚合表Agg_2对应的Schema声明如下:
<Cube name="Sales"> <Table name="sales"> <AggName name="agg_2_sales"> <AggFactCount column="row count"/> <AggForeignKey factColumn="prodid" aggColumn="prodid"/> <AggMeasure name="[Measures].[Unit Sales]" column="sum units"/> <AggMeasure name="[Measures].[Min Units]" column="min units"/> <AggMeasure name="[Measures].[Max Units]" column="max units"/> <AggMeasure name="[Measures].[Dollar Sales]" column="sum dollars"/> <AggLevel name="[Time].[Year]" column="year"/> <AggLevel name="[Time].[Quarter]" column="quarter"/> <AggLevel name="[Time].[Month]" column="month"/> <AggLevel name="[Payment Method].[Payment Method]" column="payment"/> <AggLevel name="[Customer].[State]" column="state"/> </AggName> </Table> <Dimension name="Product"> <Hierarchy hasAll="true" primaryKey="prodid" primaryKeyTable="Product"> <Join leftKey="mfrid" rightKey="mfrid"> <Table name="Product"/> <Table name="Mfr"/> </Join> <Level name="Manufacturer" table="Mfr" column="mfrid"/> <Level name="Brand" table="Product" column="brand"/> <Level name="Name" table="Product" column="prodid"/> </Hierarchy> </Dimension> <Dimension name="Day" foreignKey="day"> <Hierarchy hasAll="true" primaryKey="day"> <Table name="Time" /> <Level name="Year" column="year" type="Numeric" uniqueMembers="true" /> <Level name="Quarter" column="quarter" uniqueMembers="false" /> <Level name="Month" column="month" type="Numeric" uniqueMembers="false" /> </Hierarchy> </Dimension> <Dimension name="Customer" foreignKey="custid"> <Hierarchy hasAll="true" primaryKey="custid"> <Table name="Customer" /> <Level name="City" column="city" uniqueMembers="ture" /> <Level name="State" column="state" uniqueMembers="true" /> </Hierarchy> </Dimension> <Dimension name="Payment method"> <Hierarchy hasAll="true"> <Level name="Payment method" column="payment" uniqueMembers="ture" /> </Hierarchy> </Dimension> <AggMeasure name="Unit Sales" aggregator="sum" /> <AggMeasure name="Min Units" aggregator="min" /> <AggMeasure name="Max Units" aggregator="max" /> <AggMeasure name="Dollar Sales" aggregator="sum" /> </Cube>
其中,<AggForeignKey>标签用于声明prodid列连接到维表的prodid列,其他的所有列仍然从Product和Mfr维表中获取。
7. 总结
1. 使用Mondrian做大数据量(如>100W行)的OLAP分析时,考虑是否可以使用聚合表进行优化。
2. 然而Mondrian的优化方式又不限于聚合表这一种,是否要进行聚合表优化,要根据实际情况来决定。
3. Mondrian目前并不提供对聚合表的数据同步机制,如果要做实时OLAP,需要自己实现聚合表和事实表中的数据同步。
8. 参考资料
1. Mondiran在线文档