MDX&Mondrian介绍
文章目录
-
- MDX
-
- MDX数据库
- 基本概念
-
- 维度(Dimensions)、级别(Levels)、成员(Members)和度量值(Measures)
- 轴维度和切片器维度
- 单元(Cell)、元组(Tuple)和集合(Set)
- 基本语法
- MDX与SQL的区别
- 维度成员
-
- 成员范围
- 全部成员
- 下级成员
- 成员属性
- 集合操作
-
- NON EMPTY
- CROSS JOIN
- FILTER
- ORDER
- 计算成员
- 命名集合
- 主要函数
- Mondrian
-
- 介绍
- 表现层(the presentation layer)
- 维度层(the dimensional layer)
- 集合层(the star layer)
- 存储层(the storage layer)
- 更多参考
MDX
MDX(Multidimensional Expressions)是多维数据库(OLAP 数据库)的查询语言。
MDX数据库
MDX标准几乎被所有的大型数据库软件提供商所采用。微软有SSAS(Microsoft SQL Server Analysis Services),甲骨文有Essbase,SAP有SAP BW,IBM有TM1,除此之外还有各种各样的OLAP服务提供商的商用软件支持该标准。
基本概念
多维表达式 (MDX) 的用途是使对多个维度的数据的访问更为简单和直观。它的主要概念如下:
- 维度(Dimensions)、级别(Levels)、成员(Members)和度量值(Measures)
- 单元(Cells)、元组(Tuples)和集合(Sets)
- 轴维度和切片器维度(Axis and Slicer Dimensions)
维度(Dimensions)、级别(Levels)、成员(Members)和度量值(Measures)
这组概念只从单个维度角度理解,不涉及到维度的交集:

上图中多维数据集使用了三个维度(dimensions):“时间”、“路线”和“源”,还有两个度量值:“包”和“上一次”。
-
维度(Dimensions):对于多维数据,则可以用具有两个以上维度(Dimensions)的结构来表示。这些称作多维数据集的结构具有多个维度。
-
级别(Levels):可以认为是对维度的细分,如维度“路线”分为“东半球”和“西半球”两个级别(levels)。
-
成员:代表维度中一次或多次数据出现的项。把维度中的成员看做基础数据库中的一个或多个记录,其该列内的值归入该分类。
成员表示属于某个属性的实际数据值。例如,下图中的关系图中加入阴影表示"时间.[下半年].[第三季度]"的成员。可以理解成员是某个维度级别(维度属性)的数据元素集合(此处集合和下面集合为不同概念)。

-
度量值:是单元格中聚合为总和、计数、百分比、最小值、最大值或平均值的数值数据值。 度量值是实时计算出的动态值,响应用户导航并与数据透视表交互。
轴维度和切片器维度
- 轴维度:SELECT语句用来选择要返回的维度和成员,称为轴维度;
- 切片器维度:WHERE语句用来将返回的数据限定为特定维度和成员条件,称为切片器维度。
轴维度预期返回多个成员的数据,而切片器维度预期返回单个成员的数据。
(1)轴
用 on {axis}语法来把维度分配到轴(Axis,复数 Axes)上,一个查询可以有多个轴。
不同轴用逗号分隔,分配的顺序是没关系的。但如果把轴调换(如 A on columns, B on rows 改成 A on rows, B on columns),结果的行和列也会转置过来。
轴用 axis(0),axis(1),axis(2)…表示,前五个轴可以使用别名 Columns,Rows,Pages,Chapters,Sections。因此 on Columns 等价于 on axis(0)。超过 5 个轴时只能用 axis(5),axis(6)…来表示(极少会需要这么多的轴)。
很多实现(包括 Mondrian)支持仅用数字表示轴,因此 on Columns 可以写成 on 0。axis(0)和别名表示可以混用,例如下面语句是可以的:
SELECT
{ [Time].[Q1, 2005], [Time].[Q2, 2005] } on axis(0),
{ [Customer].[MA], [Customer].[CT] } on rows
FROM Sales
轴必须从 0 开始,并且连续,不能跳过。下面的是不可以的:
SELECT
{ [Time].[Q1, 2005], [Time].[Q2, 2005] } on rows,
{ [Customer].[MA], [Customer].[CT] } on pages
FROM Sales
在大多查询中,轴一般是两个。一个轴也可以,甚至 0 个轴。
如果轴多于两个,就没法在平面上表示。如果维度多于两个,需要把多个维度(交叉后)放到一个轴上。
(2)切片维度
切片(Slice)维度就是出现在MDX语句WHERE子句中的维度,跟SQL一样,表示对数据集的限制。例如 MDX 语句:
SELECT
{[Product].[All Products].[Food], [Product].[All Products].[Drink]} ON COLUMNS
FROM [Sales]
WHERE [Time].[Year].[2005]
限制了查询的数据范围,只限于2005年。语法和SQL不一样,[Time].[Year].[2005](是一个元组)本身就表示了一个条件。这可以看成对数据立方体从某个方向进行切片(从 Time维度的方向)得到一个子立方体,因此叫切片。
切片维度不会出现在轴上,即上面的时间维度不会出现在轴上。
一个维度不能同时出现在轴维度(SELECT 的维度)和切片维度上。
单元(Cell)、元组(Tuple)和集合(Set)
SQL从表返回二维数据子集,而MDX从多维数据集返回多维数据集子集。
(1)单元(Cells)
所有维度共同确定的一个成员。
多维数据集关系图表明多维成员的交集创建单元(Cells),从这些单元可以获取数据。为标识和析取这类数据(不管这些数据是单个单元还是多个单元块),MDX称为元组(Tuples)的参照系。
如上图中元组标识其中值为240的单元:
(源.[东半球].非洲, 时间.[下半年].[第四季度], 路线.航空, 度量值.包)
(2)元组
元组列出维度和成员来标识多维数据集内的单个单元和更大的单元部分;因为各个单元是多维数据集所有维度的交集,所以元组可以唯一标识多维数据集中的每个单元。
元组可以标识多维数据集中的一部分,不必指定某个特定单元,也不必包括多维数据集中的所有维度。如一下示例均为多维数据集关系图的元组:
(源.[东半球])
(时间.[下半年],源.[西半球])
([Customer].[Chicago, IL], [Time].[Jan, 2005])
-
单元组:只有一个维度的确定的元组
时间.[下半年] -
多元组:由多个维度共同确定的元组,需要将维度放在圆括号内,逗号隔开
(时间.[下半年], 源.[非陆地].[航空])
(3)集合(Set)
集合(Set)是零个、一个或多个元组的有序集合。在轴维度和切片器维度有这种元组集合组成:
{ (时间.[上半年], 源.非陆地.航空), (时间.[下半年], 源.非陆地.海路) }
{ [Customer].[MA],[Customer].[CT] }
{ ( [Time].[2005], [Measures].[Dollar Sales] ), ( [Measures].[Unit Sales], [Time].[Feb, 2005] ) }
基本语法
语句构成:
- 语言语句(例如,SELECT、FROM、WHERE)
- OLAP维度(产品、日期或地理位置、日期层次结构)
- 度量值(销售额、库存)
- MDX函数(SUM、AVG、FILTER)
- 集合(排序的成员集合)
SELECT
[axis specification] ON COLUMNS,
[axis specification] ON ROWS
FROM [cube name]
WHERE [slicer specification]

例如:
(1)例子一
SELECT
{[Measures].[Reseller Sales Amount],[Measures].[Internet Sales Amount]} on columns,
[Date].[Calendar Year]. Members on rows
FROM[Adventure Works]
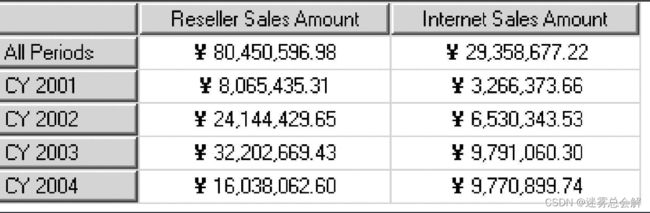
- COLUMNS和ROWS:两者可以调换过来,如 A on columns, B on rows 改成 A on rows, B on columns,相应的查询结果的行列也会调换过来。
- SELECT:字句指定一个集合,把它放到轴上;
- FROM:指定查询的cube
- 方括号“[]”:用户维度名、级别名、维度成员名,避免和函数混淆(函数名不加方括号),或者中间有空格或特殊符号
- WHERE:指定切片,对不出现在轴上的维度成员进行限定
- 分组:没有group by字句,分组是隐含的;
- 排序:没有order by字句,排序只会对某个轴进行,使用排序函数
- 不区分大小写
- 注释:支持sql注释外,还有://和/* … */注释。
(2)例子二
SELECT
{ [Measures].[Dollar Sales], [Measures].[Unit Sales] } on columns,
{ [Time].[Q1, 2005], [Time].[Q2, 2005] } on rows
FROM [Sales]
WHERE ([Customer].[MA])
查询对[Customer].[MA]这个客户在2005年第一、第二季度的销售额、单位销售额。
(3)例子三
SELECT
{ [Time].[Q1, 2005], [Time].[Q2, 2005], [Time].[Q3, 2005] } on columns,
{ [Customer].[MA], [Customer].[CT] } on rows
FROM Sales
WHERE ( [Measures].[Dollar Sales] )
查询对[Customer].[MA], [Customer].[CT]这两个客户在2005年前三个季度的销售额。
MDX与SQL的区别
(1)维度意义的差别
SQL处理查询仅涉及到列和行两个维度,而MDX在查询中可以处理多个维度。
(2)语句含义
在SQL中,SELECT语句中的列用于指定查询的列布局,而WHERE字句用于过滤返回的数据行;在MDX中,SELECT字句可用于定义几个轴维度,而WHERE字句可对查询限制特定的维度或成员。
(3)创建查询过程
在SQL语言中,查询的创建者将二维行集的结构形象化并且加以定义,通过编写对一个或多个表的查询来对该结构的内容进行填充。
MDX查询的创建者通常将多维数据集的结构形象化并且加以定义,通过编写对单个多维数据集的查询来对该结构的内容进行填充。
(4)查询结果集
SQL中查询结果集是行与列组成的二维表;MDX的结果集可以有多个维度,结构形象化比较困难。
维度成员
要把维度成员放在轴上,可以列举维度的成员,例如{ [Customer].[MA], [Customer].[CT] }。也可以通过范围语法或一个函数得到成员的集合。
成员范围
冒号(:)语法可以表示成员范围。冒号前后是同一个层次的起点和终点两个成员。
SELECT
{ [Time].[2003] : [Time].[2008] } on columns,
{ [Product].[Drinks] : [Product].[Bread] } on rows
FROM [Sales]
时间维度表示 2003 年到 2008 年(6 个成员),产品维度表示从 Drinks 到 Bread。这通常跟排序方式有关。
集合里可以包含子集合。例如下面集合,包含 2001 年的前三个月跟后三个月。
{ { [Time].[January-2001] : [Time].[March-2001] } ,{ [Time].[October-2001] : [Time].[December-2001] } }
全部成员
大多时候需要得到一个维度、层次、层的全部成员,这个时候可以使用.Members 操作(函数)。比如[Time].[Years].Members 可以得到所有年份。
SELECT
{ [Time].[Years].Members} ON COLUMNS,
{ [Product].[Line].Members} ON ROWS
FROM [SteelWheelsSales]
WHERE [Measures].[sales]
这个语句查询所有年份、所有产品线的销售额,把年份放在列上,产品线放在行上。
下级成员
有时候需要得到某个成员的下一层次的全部成员,这是需要用**.Children 函数**。这在下钻操作时经常用到。
例如要得到产品线 Classic Cars 下的所有产品,可以这样:
[Product].[Line].[Classic Cars].Children
[Product].[Line].[Classic Cars]是 Product 维度 Line 层的一个成员。
.Children 只能得到直接下级成员,如果需要多级,需要使用 Descendants()函数。语法是:
Descendants (member [, [ level ] [, flag]] )
Descendants 返回 member 成员下 level 层的成员,可选标志 flag 有多个选项,以设置包含最下一层上面的哪些层的成员。
以下是一个例子,查询 Tools 和 Toys 两类产品在 2005 年各月的销售额,因为年和月两个层次中间有一个季度层次,所以不能用[Time].[2005].Children。
SELECT
{ [Product].[Tools], [Product].[Toys] } ON COLUMNS,
Descendants ([Time].[2005],[Time].[Month],SELF_AND_BEFORE) ON ROWS
FROM Sales
WHERE [Measures].[Dollar Sales]
flag 设为 SELF_AND_BEFORE,可以看到行上包含了 2005 年和各个季度(如果设为SELF 则不会包含)。
成员属性
有时要获取维度成员的属性(维表上的某些列),这时可以使用 dimemsion properties子句。dimemsion关键字可以省略。
以下查询同时获取客户所在地的邮编属性:
SELECT
{ [Customer].[Akron, OH].Children }
DIMENSION PROPERTIES [Customer].[Zip Code]
on columns,
{ [Product].[Category].Members } on rows
FROM Sales
WHERE ([Measures].[Units Sold], [Time].[July 3, 2005])
集合操作
NON EMPTY
在多维空间,数据很多时候是稀疏的。比如:不是每一个产品都销售给了所有的客户,不是每一个客户在每个时期都购买了产品。如果按维度所有成员交叉得出报表,就会有很多空行、空列。
要从查询结果去掉这些空行:
SELECT
{ [Time].[Jan,2005],[Time].[Feb,2005] } ON COLUMNS ,
NON EMPTY { [Product].[Toys], [Product].[Toys].Children } ON ROWS
FROM Sales
WHERE ([Measures].[Dollar Sales], [Customer].[TX])
这样空行就去掉了。non empty 可用于任何轴上。
CROSS JOIN
很多时候,我们需要对两个不同的集合进行交叉,也就是要得到两个集合成员的所有组合。CrossJoin()函数就是用来得到组合的最直接方式,它的语法是 CrossJoin (set1, set2)。
以下语句在每个季度下分出两个度量:
SELECT
CrossJoin (
{ [Time].[Q1, 2005], [Time].[Q2, 2005]},
{ [Measures].[Dollar Sales], [Measures].[Unit Sales] }
) ON COLUMNS,
{ [Product].[Tools], [Product].[Toys] } ON ROWS
FROM Sales
CrossJoin 的结果是一个集合。因此支持CrossJoin 嵌套。
FILTER
Filter 函数用来筛选一个集合,它以一个集合和一个 boolean 表达式为参数Filter (set,boolean-expression)。
例如,以下表达式会返回关联的产品销售额至少为500 的产品分类的集合。
Filter (
{ [Product].[Product Category].Members },
[Measures].[Dollar Sales] >= 500
)
要求销售额至少为 150 并且销售额要至少在成本的1.2 倍以上:
Filter (
{ [Product].[Product Category].Members },
([Measures].[Dollar Sales] >= 1.2 *[Measures].[Dollar Costs])
AND [Measures].[Dollar Sales] >= 150
)
ORDER
Order()函数用于对一个集合进行排序,语法:
Order (set1, expression[,ASC| DESC | BASC | BDESC])
例子:
SELECT
{ [Measures].[Dollar Sales] } on columns,
Order (
[Product].[Product Category].Members,
[Measures].[Dollar Sales],
BDESC
) on rows
FROM [Sales]
WHERE [Time].[2004]
计算成员
在 sql 中可以增加计算出来的列,MDX 中同样也可以,在 MDX 中叫计算成员(CalculatedMember)。因为MDX 操作的是多维数据,计算成员实际是给一个维度增加成员。
语法:
with
member 成员标识 as '表达式' [, 属性...]
select ...
表达式用单引号引注。
以下例子增加一个新的度量[Avg Sales Price]:
WITH
MEMBER [Measures].[Avg Sales Price] AS
'[Measures].[Dollar Sales] / [Measures].[Unit Sales]'
SELECT
{ [Measures].[Dollar Sales], [Measures].[Unit Sales],
[Measures].[Avg Sales Price]
} on columns,
{ [Time].[Q1, 2005], [Time].[Q2, 2005] } on rows
FROM Sales
WHERE ([Customer].[MA])
命名集合
命名集合(Named Set)允许预先定义的一个集合,供后面的语句使用。语法和计算成员类似。
with
set 集合标识 as '集合表达式'
select ...
WITH
SET [User Selection] AS '{ [Product].[Action Figures], [Product].[Dolls] }'
MEMBER [Product].[UserTotal] AS 'Sum ( [User Selection] )'
SELECT
{ [Time].[Jan, 2005], [Time].[Feb, 2005] } ON COLUMNS,
{ [Product].[Toys], [User Selection], [Product].[UserTotal] } ON ROWS
FROM Sales
WHERE ([Measures].[Unit Sales])
主要函数
http://mondrian.pentaho.com/documentation/mdx.php
列出一些重要的,按返回类型来分类。
(1)union
合并两个集合。语法:Union(set1,set2[, ALL]) All 标志指示保留重复元素
(2)Except
从set1里去除set2的元素,即求两个集合的差。Except(set1,set2[, ALL])
(3)Head/Tail
返回集合Head/Tail元素 。 Head/Tail(set[, ))。
(4).SIBLINGS
返回成员的兄弟成员,包括它自己。.Siblings。
(5).MEMBERS
返回维度/层次的成员。.Members
(6) DESCENDANTS
返回成员的后代成员。Descendants (member, [level[,flag]])
flag 可以是:SELF、BEFORE、SELF_BEFORE_AFTER、LEAVES、AFTER、SELF_AND_BEFORE、SELF_AND_AFTER。
(7)DrillDownLevel(set,[level])
下钻(一级)成员。
(8) DrillDownLevelBottom(set,index[,level][,numeric])
下钻最下一级成员。
(9) DrillDownLevelBTop(set,index[,level][,numeric])
下钻最上一级成员。
(10) DrillDownMember
下钻集合2中的成员.DrillDownMember(set1,set2[,Recursive])
(11) TopCount 返回前n个数据的集合
(TopCount, BottomCount, TopPercent, Hierarchize ,etc.)
(12) 统计函数
count (set [,INCLUDEEMPTY])
Sum (set [,数值表达式]])
max/min/median/avg(set [,数值表达式]])
(13)逻辑函数
-
IS
[Jan 2000].PrevMember IS NULL [Jan 2000].Level IS [Time].[Month] -
ISEMPTY
判断一个值是否为空。语法:IsEmpey(表达式)。
(14)字符串函数
- NAME:返回维度、层次等的名称。语法:.Name
- PROPERTIES:返回成员的属性值。语法:.properties(<属性名>)
Mondrian
介绍
Mondrian是一个开源项目。一个用Java写成的OLAP引擎。它用MDX语言实现查询,从关系数据库(RDBMS)中读取数据。然后经过java API以多维的方式对结果进行展示。它实现了MDX语言、XML解析、JOLAP规范。
Mondrian的使用方式同JDBC驱动类似。可以非常方便的与现有的Web项目集成。
Mondrian OLAP 系统由四个层组成; 从最终用户到数据中心, 顺序为:
- 表现层(the presentation layer)
- 维度层(the dimensional layer)
- 集合层(the star layer)
- 存储层(the storage layer)
结构图如下:

表现层(the presentation layer)
表现层决定了最终用户将在他们的显示器上看到什么, 及他们如何同系统产生交互。
有许多方法可以用来向用户显示多维数据集, 有 pivot 表 (一种交互式的表), pie, line 和图表(bar charts)。它们可以用Swing 或 JSP来实现。
表现层以多维"文法(grammar)(维、度量、单元)”的形式发出查询,然后OLAP服务器返回结果。
JPivot 是Mondrian的表现层TagLib,一直保持着良好的开发进度。
- jpivot使用XML/ XSLT渲染OLAP报表:
- JPivot 使用 WCF (Web Component Framework) ,基于XML/XSLT来渲染Web UI组件。这使它显得十分另类。不过,OLAP报表这种非常复杂但又有规律可循的东西,最适合使用XSLT来渲染。
- jpivot完全基于JSP+TagLib:
JPivot另外一个可能使人不惯的地方是它完全基于taglib而不是大家熟悉的MVC模式。但它可以很方便的将多维数据展示给最终用户,如下表格:
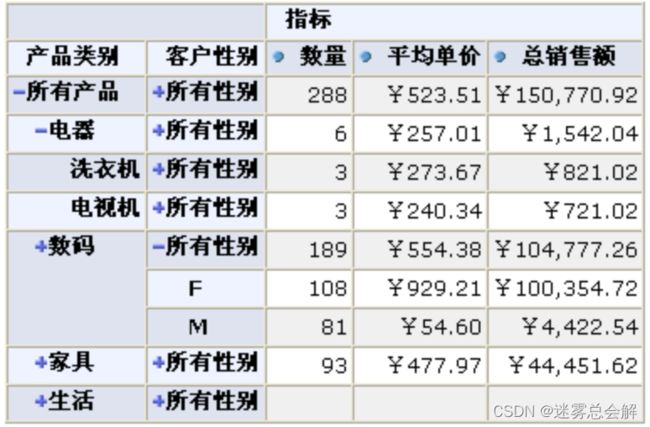
jpivot其实是一个自定义jsp的标签库。它基于XML/XSLT配置来生成相应的html。所幸的是,我们并不需要了解太多关于这方面的内容,我们只要掌握相应jsp标签的使用即可。
维度层(the dimensional layer)
维度层用来解析、验证和执行MDX查询要求。
一个MDX查询要通过几个阶段来完成:首先是计算坐标轴(axes),再者计算坐标轴axes 中cell的值。
为了提高效率,维度层把要求查询的单元成批发送到集合层,查询转换器接受操作现有查询的请求,而不是对每个请求都建立一个MDX 声明。
集合层(the star layer)
集合层负责维护和创建集合缓存,一个集合是在内存中缓存一组单元值, 这些单元值由一组维的值来确定。
维度层对这些单元发出查询请求,如果所查询的单元值不在缓存中,则集合管理器(aggregation manager)会向存储层发出查询请求。
存储层(the storage layer)
存储层是一个关系型数据库(RDBMS)。它负责创建集合的单元数据,和提供维表的成员。
更多参考
具体的可以参考:
- https://segmentfault.com/a/1190000007782683
- Mondrian 使用教程_evangel_z的博客-CSDN博客