linkedIn开源搜索引擎IndexTank 安装
LinkedIn 收购了IndexTank,在收购的时候承诺开源IndexTank的技术,现在兑现了这个承诺,IndexTank引擎以Apache 2.0协议发布!IndexTank包含两部分:
indextank-engine: Indexing engine
indextank-service: API, BackOffice, Storefront, and Nebulizer
1. 什么是 IndexTank?
下面是网上的简介:
- IndexEngine: 一套基于Java的索引-搜索引擎实现,支持的特性包括:variables (boosts), categories (facets), faceted search, snippeting, 自定义打分功能, 搜索建议和自动完成。IndexTank的设计分离了相关性标记和文档内容,因为相关性标记的生命周期和文档本身是不一样的,特别是在用户创建的内容的情况下,例如 分享次数,Like按钮,+1按钮等等。
- API: 支持REST的接口,处理同IndexEngine的认证,验证,交互工作。它可以让IndexTank的用户用HTTP的方式访问不同技术平台的服务,例如Java,PHP,.NET等等。
- Nebulizer: 多宿主框架可以管理不限数量的索引。这个框架基于Infrastructure-as-a-Service,可以根据需要给不同的索引分配不同的资源。
2. Indexing engine简单安装过程
(其实就是readme.md)
从 https://github.com/linkedin/indextank-engine 使用git下载。 (得先安装git 和 maven)
在命令行下执行maven编译:
$ mvn package assembly:single
会在target目录下生成indextank-engine-1.0.0.jar 和 indextank-engine-1.0.0-jar-with-dependencies.jar
编译过程中会自动从网上下载依赖的包。
编译成功后,执行程序 (com.flaptor.indextank.api.Launcher是MainClass)
API server 会监听 20220端口. 启动时需要根目录下的sample-engine-config 文件,该文件可以修改端口。
$ java -cp target/indextank-engine-1.0.0-jar-with-dependencies.jar com.flaptor.indextank.api.Launcher
添加数据建立索引(使用curl发送了两条json数据)
$ curl -d "{\"docid\":\"post1\", \"fields\":{\"text\":\"I love Fallout\"}}" -v -X PUT http://localhost:20220/v1/indexes/idx/docs
$ curl -d "{\"docid\":\"post2\", \"fields\":{\"text\":\"I love Planescape\"}}" -v -X PUT http://localhost:20220/v1/indexes/idx/docs
检索关键词 love:
$ curl http://localhost:20220/v1/indexes/idx/search?q=love
可以看到结果:
{"matches":2,"results":[{"docid":"post2","query_relevance_score":-2350.0},{"docid":"post1","query_relevance_score":-2403.0}],"query":"love","facets":{},"search_time":"0.000"}
其它的它支持云搜索啥的,具体细节得慢慢研究了
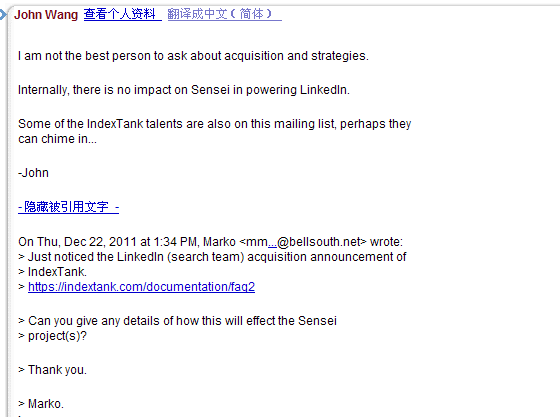
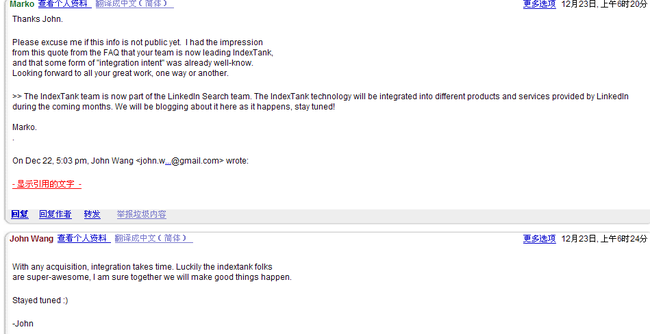
PS: 突然想到 这个开源了,对sensei有啥影响,John Wang 在群组里说的:
对sensei没啥影响,在集成,敬请期待。。。