Hadoop The Definitive Guide 2nd Edition 读书笔记2
第三章介绍的是Hadoop的分布式文件系统HDFS相关的内容。主要介绍HDFS组成部分和操作接口。
HDFS的架构:
HDFS采用成熟的Master/Slaves架构,其中Master称为Namenode,Slave称为Datanode。Namenode存储文件系统的元数据信息,它维护者整个文件的系统的目录树和所有文件的文件和索引目录,他们以命名空间镜像(fsimage)和编辑日志(edit log)的形式存贮在namdnode本地文件系统中。Datanode存储实际的数据。
HDFS的设计目标:
HDFS是为了存储超大文件而设计的文件系统,文件的访问特点是一次写入多次读取,每次操作都是读取大数据块并进行各种分析操作。
HDFS并不适用存储大量的小文件,因为整个文件系统的元数据信息都存储在NamoNode中,因此文件数量的饿先知也是有namenode的内存容量决定的。如果小文件过多,每个文件的元数据信息都会占用一定的内存,那么很快这些信息就会超出namenode的内存范围,从而降低了整个系统的性能。最近开源的TFS声称能够使用与海量小文件存储,据说原理是将小文件合并成大文件,然后加上索引,查找的时候直接定位,不知道真假,不过作为自主开发的文件系统,我们还是要支持一下的。
HDFS默认块大小是64MB,可见比传统的文件系统的块大很多。这样做的目的是减少寻址的开销,前面说过HDFS是为了大块数据的操作设计的,如果块足够大,就可以减少寻址的次数。并且MapReduce过程中的map任务通常是在一个时间内对一个块进行操作,因此如果任务数过少(少于集群节点数量),作业的运行速度显然比预期的慢。
HDFS命令行接口:
我们可以通过命令行与HDFS进行交互,比如上传本地的1.txt文件到HDFS中,可以用:
hadoop fs -copyFromLocal 1.txt hdfs://localhost/user/hadoop/1.txt
可以用hadoop fs -ls查看文件系统中的文件列表。
HDFS文件接口:
HDFS中提供类似与POSIX的文件访问接口,客户端程序要通过FilsSystem对象与HDFS进行交互。
具体的操作主要seek,create,append等
下面举一个拷贝一个文件到HDFS中的例子:
运行结果如下:
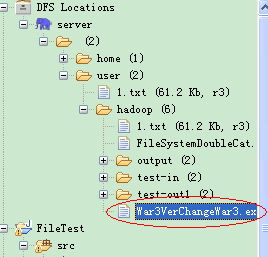
查询文件系统:
FileStatus类封装了文件系统中文件和目录的元数据,包括文件长度、块大小、符文、修改时间、所有者等信息。
用listStatus系列函数列出目录的内容,这些函数中允许我们使用PathFilter来限制匹配的文件和目录。
下面例子列出test-in目录和output目录中的文件:
执行结果:

在一部操作中处理批量文件的要求很常见,比如我们要处理一个月的日志,这些文件被包含在大量目录中。Hadoop中有一个通配的操作,globStatus,可以方便的使用通配符在一个表达式中核对多个文件,不需要类聚每个文件和目录,也可以配合PathFilter排除一些路径。
下面我们举一个例子,列出所有文件,但是排除以1结尾的目录:
在目录中有如下文件:
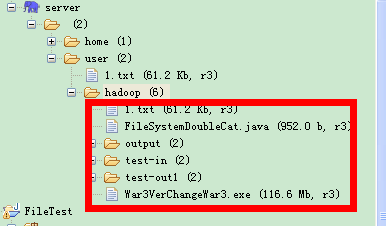
我们排除以1结尾的文件,就是排除test-out1,运行结果如下:

文件读取过程剖析:

客户端要读取一个文件,首先跟namenode通信确定要读取的块的位置,DistributedFileSystem返回一个FSDataInputStream对象,FSDataInputStream是对DFSInputStream的包装,他会跟相应的datanode通信读取数据,当到达一个块的末尾后,会找到下一个块的最佳节点,继续读取。
文件写入过程剖析:

客户端跟namenode发送一个rpc调用在文件系统的命名空间中创建一个文件,这时并没有块与之联系。结果一系列检查后,DistributedFileSystem返回一个FSDataOutputStream对象,这个对象是对DFSOutputStream的封装。客户端写入数据时,DFSOutputStream将数据分为一个一个包,写入数据队列。写入过程是以一个数据流管道的形式写的,在HDFS中一个块有三个副本,数据流先写入第一个节点,第一个节点会将接受的包写入第二个节点,第二个节点会写入第三个节点,这就形成了一个数据管道。DFSOutputStream用一个数据节点确认队列来存储报的确认状态,一个包只有在管道中三个节点都确认无误后才被移除确认队列。
一致性模型:
HDFS用out.sync()来刷新缓冲区,从而保证读取这读取的数据时一致的。
这一章剩下的内容是介绍并行复制,归档文件的,这部分看书就可以,就不细说了。
HDFS的架构:
HDFS采用成熟的Master/Slaves架构,其中Master称为Namenode,Slave称为Datanode。Namenode存储文件系统的元数据信息,它维护者整个文件的系统的目录树和所有文件的文件和索引目录,他们以命名空间镜像(fsimage)和编辑日志(edit log)的形式存贮在namdnode本地文件系统中。Datanode存储实际的数据。
HDFS的设计目标:
HDFS是为了存储超大文件而设计的文件系统,文件的访问特点是一次写入多次读取,每次操作都是读取大数据块并进行各种分析操作。
HDFS并不适用存储大量的小文件,因为整个文件系统的元数据信息都存储在NamoNode中,因此文件数量的饿先知也是有namenode的内存容量决定的。如果小文件过多,每个文件的元数据信息都会占用一定的内存,那么很快这些信息就会超出namenode的内存范围,从而降低了整个系统的性能。最近开源的TFS声称能够使用与海量小文件存储,据说原理是将小文件合并成大文件,然后加上索引,查找的时候直接定位,不知道真假,不过作为自主开发的文件系统,我们还是要支持一下的。
HDFS默认块大小是64MB,可见比传统的文件系统的块大很多。这样做的目的是减少寻址的开销,前面说过HDFS是为了大块数据的操作设计的,如果块足够大,就可以减少寻址的次数。并且MapReduce过程中的map任务通常是在一个时间内对一个块进行操作,因此如果任务数过少(少于集群节点数量),作业的运行速度显然比预期的慢。
HDFS命令行接口:
我们可以通过命令行与HDFS进行交互,比如上传本地的1.txt文件到HDFS中,可以用:
hadoop fs -copyFromLocal 1.txt hdfs://localhost/user/hadoop/1.txt
可以用hadoop fs -ls查看文件系统中的文件列表。
HDFS文件接口:
HDFS中提供类似与POSIX的文件访问接口,客户端程序要通过FilsSystem对象与HDFS进行交互。
具体的操作主要seek,create,append等
下面举一个拷贝一个文件到HDFS中的例子:
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.util.Progressable;
import org.apache.hadoop.io.IOUtils;
public class FileCopyWithProcess {
public static void main(String[] args) {
String localSrc = "F:/War3VerChangeWar3.exe";
String dst = "hdfs://59.72.109.206:9000/user/hadoop/War3VerChangeWar3.exe";
InputStream in = null;
OutputStream out = null;
FileSystem fs = null;
try {
in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
fs = FileSystem.get(URI.create(dst), conf);
out = fs.create(new Path(dst),
new Progressable() {
@Override
public void progress() {
System.out.print(".");
}
}
);
IOUtils.copyBytes(in, out, 4096, true);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
in.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
IOUtils.closeStream(out);
}
}
}
运行结果如下:
查询文件系统:
FileStatus类封装了文件系统中文件和目录的元数据,包括文件长度、块大小、符文、修改时间、所有者等信息。
用listStatus系列函数列出目录的内容,这些函数中允许我们使用PathFilter来限制匹配的文件和目录。
下面例子列出test-in目录和output目录中的文件:
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
public class ListStatus {
public static void main(String[] args) {
String[] uri = {"test-in", "output" };
Configuration conf = new Configuration();
try {
FileSystem fs = FileSystem.get(URI.create(uri[0]), conf);
Path[] paths = new Path[2];
for (int i = 0; i < paths.length; i++) {
paths[i] = new Path(uri[i]);
}
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path path : listedPaths) {
System.out.println(path);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
执行结果:
在一部操作中处理批量文件的要求很常见,比如我们要处理一个月的日志,这些文件被包含在大量目录中。Hadoop中有一个通配的操作,globStatus,可以方便的使用通配符在一个表达式中核对多个文件,不需要类聚每个文件和目录,也可以配合PathFilter排除一些路径。
下面我们举一个例子,列出所有文件,但是排除以1结尾的目录:
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
public class GlobStatusWithPathFilter {
private static class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
@Override
public boolean accept(Path path) {
return !path.toString().matches(regex);
}
}
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
FileSystem fs = FileSystem.get(conf);
FileStatus[] status = fs.globStatus(new Path("test-*"), new RegexExcludePathFilter(".*1$"));
Path[] paths = FileUtil.stat2Paths(status);
for (Path path : paths) {
System.out.println(path);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
在目录中有如下文件:
我们排除以1结尾的文件,就是排除test-out1,运行结果如下:
文件读取过程剖析:
客户端要读取一个文件,首先跟namenode通信确定要读取的块的位置,DistributedFileSystem返回一个FSDataInputStream对象,FSDataInputStream是对DFSInputStream的包装,他会跟相应的datanode通信读取数据,当到达一个块的末尾后,会找到下一个块的最佳节点,继续读取。
文件写入过程剖析:
客户端跟namenode发送一个rpc调用在文件系统的命名空间中创建一个文件,这时并没有块与之联系。结果一系列检查后,DistributedFileSystem返回一个FSDataOutputStream对象,这个对象是对DFSOutputStream的封装。客户端写入数据时,DFSOutputStream将数据分为一个一个包,写入数据队列。写入过程是以一个数据流管道的形式写的,在HDFS中一个块有三个副本,数据流先写入第一个节点,第一个节点会将接受的包写入第二个节点,第二个节点会写入第三个节点,这就形成了一个数据管道。DFSOutputStream用一个数据节点确认队列来存储报的确认状态,一个包只有在管道中三个节点都确认无误后才被移除确认队列。
一致性模型:
HDFS用out.sync()来刷新缓冲区,从而保证读取这读取的数据时一致的。
这一章剩下的内容是介绍并行复制,归档文件的,这部分看书就可以,就不细说了。