htmlparser使用指南
简介
htmlparser是一个纯的java写的html解析的库,它不依赖于其它的java库文件,主要用于改造或提取html,它能超高速解析html。
htmlparser基本功能
1. 信息提取
· 文本信息抽取,例如对HTML进行有效信息搜索
· 链接提取,用于自动给页面的链接文本加上链接的标签
· 资源提取,例如对一些图片、声音的资源的处理
· 链接检查,用于检查HTML中的链接是否有效
· 页面内容的监控
2. 信息转换
· 链接重写,用于修改页面中的所有超链接
· 网页内容拷贝,用于将网页内容保存到本地
· 内容检验,可以用来过滤网页上一些令人不愉快的字词
· HTML信息清洗,把本来乱七八糟的HTML信息格式化
· 转成XML格式数据
库说明
1、htmlparser对html页面处理的数据结构 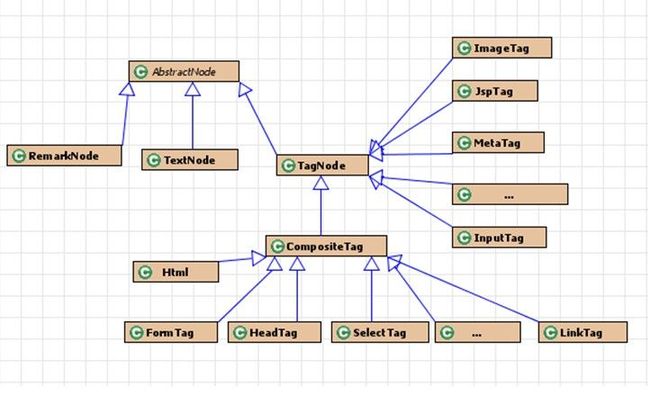
如图所示,HtmlParser采用了经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面各元素
1)、org.htmlparser.Node:Node接口定义了进行树形结构节点操作的各种典型操作方法
包括:
节点到html文本、text文本的方法:toPlainTextString、toHtml
典型树形结构遍历的方法:getParent、getChildren、getFirstChild、getLastChild、getPreviousSibling、getNextSibling、getText
获取节点对应的树形结构结构的顶级节点Page对象方法:getPage
获取节点起始位置的方法:getStartPosition、getEndPosition
Visitor方法遍历节点时候方法:accept (NodeVisitor visitor)
Filter方法:collectInto (NodeList list, NodeFilter filter)
Object方法:toString、clone
2)、org.htmlparser.nodes.AbstractNode:AbstractNode是形成HTML树形结构抽象基类,实现了Node接口。
在htmlparser中,Node分成三类:
RemarkNode:代表Html中的注释 TagNode:标签节点 TextNode:文本节点
这三类节点都继承AbstractNode。
org.htmlparser.nodes.TagNode:
TagNode包含了对HTML处理的核心的各个类,是所有TAG的基类,其中有分为包含其他TAG的复合节ComositeTag和不包含其他TAG的叶子节点Tag。
复合节点CompositeTag:
AppletTag,BodyTag,Bullet,BulletList,DefinitionList,DefinitionListBullet,Div,FormTag,FrameSetTag,HeadingTag,
HeadTag,Html,LabelTag,LinkTag,ObjectTag,ParagraphTag,ScriptTag,SelectTag,Span,StyleTag,TableColumn,
TableHeader,TableRow,TableTag,TextareaTag,TitleTag
叶子节点TAG:
BaseHrefTag,DoctypeTag,FrameTag,ImageTag,InputTag,JspTag,MetaTag,ProcessingInstructionTag,
2、htmlparser对html页面处理的算法
主要是如下几种方式
采用Visitor方式访问Html
try {
Parser parser = new Parser();
parser.setURL(”http://www.google.com”);
parser.setEncoding(parser.getEncoding());
NodeVisitor visitor = new NodeVisitor() {
public void visitTag(Tag tag) {
logger.fatal(”testVisitorAll() Tag name is :”
+ tag.getTagName() + ” \n Class is :”
+ tag.getClass());
}
};
parser.visitAllNodesWith(visitor);
} catch (ParserException e) {
e.printStackTrace();
}
采用Filter方式访问html
try {
NodeFilter filter = new NodeClassFilter(LinkTag.class);
Parser parser = new Parser();
parser.setURL(”http://www.google.com”);
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
LinkTag node = (LinkTag) list.elementAt(i);
logger.fatal(”testLinkTag() Link is :” + node.extractLink());
}
} catch (Exception e) {
e.printStackTrace();
}
采用org.htmlparser.beans方式
另外htmlparser 还在org.htmlparser.beans中对一些常用的方法进行了封装,以简化操作,例如:
Parser parser = new Parser();
LinkBean linkBean = new LinkBean();
linkBean.setURL(”http://www.google.com”);
URL[] urls = linkBean.getLinks();
for (int i = 0; i < urls.length; i++) {
URL url = urls[i];
logger.fatal(”testLinkBean() -url is :” + url);
}
3、htmlparser关键包结构说明
htmlparser其实核心代码并不多,好好研究一下其代码,弥补文档不足的问题。同时htmlparser的代码注释和单元测试用例还是很齐全的,也有助于了解htmlparser的用法。
3.1、org.htmlparser
定义了htmlparser的一些基础类。其中最为重要的是Parser类。
Parser是htmlparser的最核心的类,其构造函数提供了如下:Parser.createParser (String html, String charset)、 Parser ()、Parser (Lexer lexer, ParserFeedback fb)、Parser (URLConnection connection, ParserFeedback fb)、Parser (String resource, ParserFeedback feedback)、 Parser (String resource)
各构造函数的具体用法及含义可以查看其代码,很容易理解。
Parser常用的几个方法:
elements获取元素
Parser parser = new Parser (”http://www.google.com”);
for (NodeIterator i = parser.elements (); i.hasMoreElements (); )
processMyNodes (i.nextNode ());
parse (NodeFilter filter):通过NodeFilter方式获取
visitAllNodesWith (NodeVisitor visitor):通过Nodevisitor方式
extractAllNodesThatMatch (NodeFilter filter):通过NodeFilter方式
3.2、org.htmlparser.beans
对Visitor和Filter的方法进行了封装,定义了针对一些常用html元素操作的bean,简化对常用元素的提取操作。
包括:FilterBean、HTMLLinkBean、HTMLTextBean、LinkBean、StringBean、BeanyBaby等。
3.3、org.htmlparser.nodes
定义了基础的node,包括:AbstractNode、RemarkNode、TagNode、TextNode等。
3.4、org.htmlparser.tags
定义了htmlparser的各种tag。
3.5、org.htmlparser.filters
定义了htmlparser所提供的各种filter,主要通过extractAllNodesThatMatch (NodeFilter filter)来对html页面指定类型的元素进行过滤,包括:AndFilter、CssSelectorNodeFilter、 HasAttributeFilter、HasChildFilter、HasParentFilter、HasSiblingFilter、 IsEqualFilter、LinkRegexFilter、LinkStringFilter、NodeClassFilter、 NotFilter、OrFilter、RegexFilter、StringFilter、TagNameFilter、XorFilter
3.6、org.htmlparser.visitors
定义了htmlparser所提供的各种visitor,主要通过visitAllNodesWith (NodeVisitor visitor)来对html页面元素进行遍历,包括:HtmlPage、LinkFindingVisitor、NodeVisitor、 ObjectFindingVisitor、StringFindingVisitor、TagFindingVisitor、 TextExtractingVisitor、UrlModifyingVisitor
3.7、org.htmlparser.parserapplications
定义了一些实用的工具,包括LinkExtractor、SiteCapturer、StringExtractor、WikiCapturer,这几个类也可以作为htmlparser使用样例。
3.8、org.htmlparser.tests
对各种功能的单元测试用例,也可以作为htmlparser使用的样例。
4、htmlparser的使用样例
import java.net.URL;
import junit.framework.TestCase;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.Tag;
import org.htmlparser.beans.LinkBean;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.filters.TagNameFilter;
import org.htmlparser.tags.HeadTag;
import org.htmlparser.tags.ImageTag;
import org.htmlparser.tags.InputTag;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.tags.OptionTag;
import org.htmlparser.tags.SelectTag;
import org.htmlparser.tags.TableColumn;
import org.htmlparser.tags.TableRow;
import org.htmlparser.tags.TableTag;
import org.htmlparser.tags.TitleTag;
import org.htmlparser.util.NodeIterator;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
import org.htmlparser.visitors.HtmlPage;
import org.htmlparser.visitors.NodeVisitor;
import org.htmlparser.visitors.ObjectFindingVisitor;
public class ParserTestCase extends TestCase {
protected static Log logger = LogFactory.getLog(ParserTestCase.class);
public ParserTestCase(String name) {
super(name);
}
/*
* 测试ObjectFindVisitor的用法
*/
public void testImageVisitor() {
try {
ImageTag imgLink;
ObjectFindingVisitor visitor = new ObjectFindingVisitor(
ImageTag.class);
Parser parser = new Parser();
parser.setURL("http://www.google.com");
parser.setEncoding(parser.getEncoding());
parser.visitAllNodesWith(visitor);
Node[] nodes = visitor.getTags();
for (int i = 0; i < nodes.length; i++) {
imgLink = (ImageTag) nodes[i];
logger.fatal("testImageVisitor() ImageURL = "
+ imgLink.getImageURL());
logger.fatal("testImageVisitor() ImageLocation = "
+ imgLink.extractImageLocn());
logger.fatal("testImageVisitor() SRC = "
+ imgLink.getAttribute("SRC"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 测试TagNameFilter用法
*/
public void testNodeFilter() {
try {
NodeFilter filter = new TagNameFilter("IMG");
Parser parser = new Parser();
parser.setURL("http://www.google.com");
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
logger.fatal("testNodeFilter() " + list.elementAt(i).toHtml());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 测试NodeClassFilter用法
*/
public void testLinkTag() {
try {
NodeFilter filter = new NodeClassFilter(LinkTag.class);
Parser parser = new Parser();
parser.setURL("http://www.google.com");
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
LinkTag node = (LinkTag) list.elementAt(i);
logger.fatal("testLinkTag() Link is :" + node.extractLink());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 测试<link href=" text=’text/css’ rel=’stylesheet’ />用法
*/
public void testLinkCSS() {
try {
Parser parser = new Parser();
parser
.setInputHTML("<head><title>Link Test</title>"
+ "<link href='/test01/css.css' text='text/css' rel='stylesheet' />"
+ "<link href='/test02/css.css' text='text/css' rel='stylesheet' />"
+ "</head>" + "<body>");
parser.setEncoding(parser.getEncoding());
for (NodeIterator e = parser.elements(); e.hasMoreNodes();) {
Node node = e.nextNode();
logger
.fatal("testLinkCSS()" + node.getText()
+ node.getClass());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 测试OrFilter的用法
*/
public void testOrFilter() {
NodeFilter inputFilter = new NodeClassFilter(InputTag.class);
NodeFilter selectFilter = new NodeClassFilter(SelectTag.class);
NodeList nodeList = null;
try {
Parser parser = new Parser();
parser
.setInputHTML("<head><title>OrFilter Test</title>"
+ "<link href='/test01/css.css' text='text/css' rel='stylesheet' />"
+ "<link href='/test02/css.css' text='text/css' rel='stylesheet' />"
+ "</head>"
+ "<body>"
+ "<input type='text' value='text1′ name='text1′/>"
+ "<input type='text' value='text2′ name='text2′/>"
+ "<select><option id='1′>1</option><option id='2′>2</option><option id='3′></option></select>"
+ "<a href='http://www.yeeach.com'>yeeach.com</a>"
+ "</body>");
parser.setEncoding(parser.getEncoding());
OrFilter lastFilter = new OrFilter();
lastFilter.setPredicates(new NodeFilter[] { selectFilter,
inputFilter });
nodeList = parser.parse(lastFilter);
for (int i = 0; i <= nodeList.size(); i++) {
if (nodeList.elementAt(i) instanceof InputTag) {
InputTag tag = (InputTag) nodeList.elementAt(i);
logger.fatal("OrFilter tag name is :" + tag.getTagName()
+ " ,tag value is:" + tag.getAttribute("value"));
}
if (nodeList.elementAt(i) instanceof SelectTag) {
SelectTag tag = (SelectTag) nodeList.elementAt(i);
NodeList list = tag.getChildren();
for (int j = 0; j < list.size(); j++) {
OptionTag option = (OptionTag) list.elementAt(j);
logger
.fatal("OrFilter Option"
+ option.getOptionText());
}
}
}
} catch (ParserException e) {
e.printStackTrace();
}
}
/*
* 测试对<table><tr><td></td></tr></table>的解析
*/
public void testTable() {
Parser myParser;
NodeList nodeList = null;
myParser = Parser.createParser("<body> " + "<table id='table1′ >"
+ "<tr><td>1-11</td><td>1-12</td><td>1-13</td>"
+ "<tr><td>1-21</td><td>1-22</td><td>1-23</td>"
+ "<tr><td>1-31</td><td>1-32</td><td>1-33</td></table>"
+ "<table id='table2′ >"
+ "<tr><td>2-11</td><td>2-12</td><td>2-13</td>"
+ "<tr><td>2-21</td><td>2-22</td><td>2-23</td>"
+ "<tr><td>2-31</td><td>2-32</td><td>2-33</td></table>"
+ "</body>", "GBK");
NodeFilter tableFilter = new NodeClassFilter(TableTag.class);
OrFilter lastFilter = new OrFilter();
lastFilter.setPredicates(new NodeFilter[] { tableFilter });
try {
nodeList = myParser.parse(lastFilter);
for (int i = 0; i <= nodeList.size(); i++) {
if (nodeList.elementAt(i) instanceof TableTag) {
TableTag tag = (TableTag) nodeList.elementAt(i);
TableRow[] rows = tag.getRows();
for (int j = 0; j < rows.length; j++) {
TableRow tr = (TableRow) rows[j];
TableColumn[] td = tr.getColumns();
for (int k = 0; k < td.length; k++) {
logger.fatal("<td>" + td[k].toPlainTextString());
}
}
}
}
} catch (ParserException e) {
e.printStackTrace();
}
}
/*
* 测试NodeVisitor的用法,遍历所有节点
*/
public void testVisitorAll() {
try {
Parser parser = new Parser();
parser.setURL("http://www.google.com");
parser.setEncoding(parser.getEncoding());
NodeVisitor visitor = new NodeVisitor() {
public void visitTag(Tag tag) {
logger.fatal("testVisitorAll() Tag name is :"
+ tag.getTagName() + " \n Class is :"
+ tag.getClass());
}
};
parser.visitAllNodesWith(visitor);
} catch (ParserException e) {
e.printStackTrace();
}
}
/*
* 测试对指定Tag的NodeVisitor的用法
*/
public void testTagVisitor() {
try {
Parser parser = new Parser(
"<head><title>dddd</title>"
+ "<link href='/test01/css.css' text='text/css' rel='stylesheet' />"
+ "<link href='/test02/css.css' text='text/css' rel='stylesheet' />"
+ "</head>" + "<body>"
+ "<a href='http://www.yeeach.com'>yeeach.com</a>"
+ "</body>");
NodeVisitor visitor = new NodeVisitor() {
public void visitTag(Tag tag) {
if (tag instanceof HeadTag) {
logger.fatal("visitTag() HeadTag : Tag name is :"
+ tag.getTagName() + " \n Class is :"
+ tag.getClass() + "\n Text is :"
+ tag.getText());
} else if (tag instanceof TitleTag) {
logger.fatal("visitTag() TitleTag : Tag name is :"
+ tag.getTagName() + " \n Class is :"
+ tag.getClass() + "\n Text is :"
+ tag.getText());
} else if (tag instanceof LinkTag) {
logger.fatal("visitTag() LinkTag : Tag name is :"
+ tag.getTagName() + " \n Class is :"
+ tag.getClass() + "\n Text is :"
+ tag.getText() + " \n getAttribute is :"
+ tag.getAttribute("href"));
} else {
logger.fatal("visitTag() : Tag name is :"
+ tag.getTagName() + " \n Class is :"
+ tag.getClass() + "\n Text is :"
+ tag.getText());
}
}
};
parser.visitAllNodesWith(visitor);
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 测试HtmlPage的用法
*/
public void testHtmlPage() {
String inputHTML = "<html>" + "<head>"
+ "<title>Welcome to the HTMLParser website</title>"
+ "</head>" + "<body>" + "Welcome to HTMLParser"
+ "<table id='table1′ >"
+ "<tr><td>1-11</td><td>1-12</td><td>1-13</td>"
+ "<tr><td>1-21</td><td>1-22</td><td>1-23</td>"
+ "<tr><td>1-31</td><td>1-32</td><td>1-33</td></table>"
+ "<table id='table2′ >"
+ "<tr><td>2-11</td><td>2-12</td><td>2-13</td>"
+ "<tr><td>2-21</td><td>2-22</td><td>2-23</td>"
+ "<tr><td>2-31</td><td>2-32</td><td>2-33</td></table>"
+ "</body>" + "</html>";
Parser parser = new Parser();
try {
parser.setInputHTML(inputHTML);
parser.setEncoding(parser.getURL());
HtmlPage page = new HtmlPage(parser);
parser.visitAllNodesWith(page);
logger.fatal("testHtmlPage -title is :" + page.getTitle());
NodeList list = page.getBody();
for (NodeIterator iterator = list.elements(); iterator
.hasMoreNodes();) {
Node node = iterator.nextNode();
logger.fatal("testHtmlPage -node is :" + node.toHtml());
}
} catch (ParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
* 测试LinkBean的用法
*/
public void testLinkBean() {
LinkBean linkBean = new LinkBean();
linkBean.setURL("http://www.google.com");
URL[] urls = linkBean.getLinks();
for (int i = 0; i < urls.length; i++) {
URL url = urls[i];
logger.fatal("testLinkBean() -url is :" + url);
}
}
本文来自http://kdisk-sina-com.iteye.com/blog/549412
本人是边学习,边整理排版的