《高性能MySQL》读书笔记(二)------ 索引
索引是一种有效的查询加速策略。索引可以在以下情况下加速:
1、索引可以有效地避免全表扫描。
2、非聚集索引在某些情况甚至可以不访问数据表。(聚集索引索引和数据表混生)。
3、聚集索引可以有效地避免所有的插入都发生在数据表的尾部。
4、部分查询可以有效地利用B-Tree索引的有序性,避免排序操作。
索引是如何组织的?如何在查询中有效利用索引?
数据库的索引可分为聚集索引与非聚集索引。聚集索引将数据存储与索引组织统一,索引的叶子节点即是数据存储页。非聚集疏索引的叶子节点存储的是数据存储位置的指针。
聚集索引的存储形式如下:
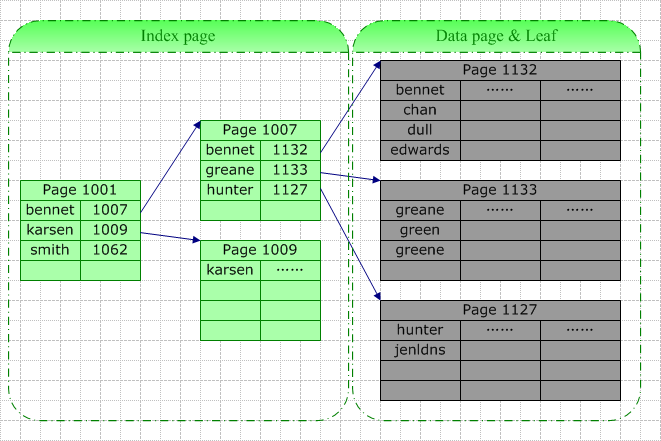
在查找greene时,先比较索引页1001中,在bennet与karsen之间,到bennet的指向的索引页中1007,在索引页1007中查得greene的的位置为索引页(也是数据 页)1133,再去1133去比对查询。在查找的过程中,因为记录的是数据的页而不是准确存储位置,发生了两次页内的扫描。
在插入新数据greens时,索引需要先查找出对应的页为1133,然后在相应页进行添加。如若数据页的过大,即,可能会造成页内的扫描成本过高,需要对数据页进行分割。分割的过程需要对父辈的索引进行调整,需要对同辈的数据进行挪动,成本较高,且数据插入的过程,需要先查找判定合适插入位置。所以,使用聚集索引的表,在发生数据页分页时,插入操作可能是一个消耗比较大的操作。
在删除数据greene时,在判定位置页1133后,直接删除对应的数据即可,然后调整页1007索引位置,维护索引的代价较低。
非聚集索引的存储形式如下:
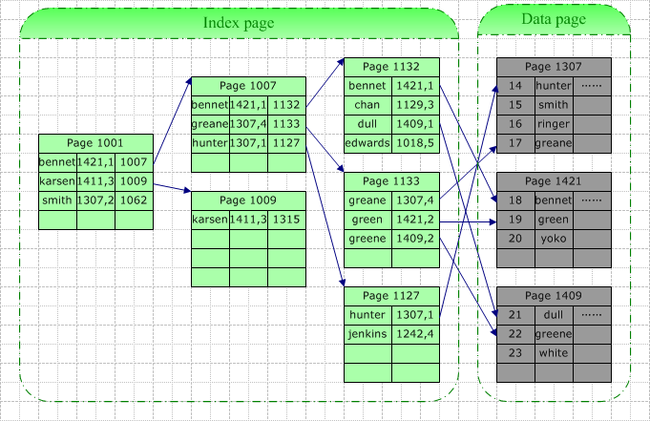
在查找greene是,在索引页查找greene的位置在bennet后,bennet指向的下一个索引页为1007,在页1007中扫描,得到在地址为数据页1307,偏移位置为4的位置出现了一次,但是继续扫描索引(在为主键或者Unique时可以停止),其指向的下一个索引页为1133,扫描索引,得到位置为数据页1307偏移2的位置和数据页1409偏移2的位置。
在插入新数据greens时,直接在最后数据页1409插入新数据(在数据页达到指定大小的时候创建新页)。然后调整索引,修正索引页1133。
在删除数据greene时,在查找判定位置删除后,维护索引需要对页1007和1133进行修正,代价较大(依旧是很小的代价)。
在上述过程中,聚集索引和非聚集索引的可能会带来的性能差别主要在插入时。但是不可忽视的一个重大区别是:聚集索引的“数据页”是有序的,而非聚集索引的索引页有序而数据页无序!这意味着在查找的时候,聚集索引可以高效地地预读,可以有效地减少磁盘IO。而且,聚集索引将数据的有序组织可以避免新插入数据聚集在最末尾的情况?(有何好处?不同位置并发插入不是有磁盘IO的限制,还是一起插入在最末尾速度比较快吧?)
使用聚集索引建表,如果要在非主键列建立索引,称为第二索引,其组织形式为非聚集索引。
因为索引包含了一部分数据信息,并且是有序的,所以索引在部分情况下可以避免对数据库表的访问和避免排序。如查找以g开头的人名并排序这个需求就可以直接利用索引完成。
除利用B-Tree的索引之外,还可以利用哈希表可构造索引。哈希索引的一个优点是只保留了简短的哈希值,所以索引特别紧凑。本质上,B-tree支持使用前缀的查询,索引里依旧存储了被建立索引的值。哈希索引,因为哈希计算的单向性,且计算结果顺序不可控,不支持需要顺序支持的一些操作。支持哈希索引的引擎有:Memory和NDB Cluster。InnoDB在索引被频繁访问的时候,会在B-Tree的顶端为索引建立在内存中的哈希索引,这个过程由引擎自动完成,不可控。可以使用Hash计算实现一个伪哈希索引,使用触发器对伪哈希索引列进行维护。 查询时使用哈希值和原值。这样做,可以减小索引的大小。
有效地利用索引。有效地利用索引可以在查询时减少大量的表扫描。如select × from table where name like 'g*' and sex = 'female' 如果调整为 select × from table where sex = 'female' and name like g* 。因为SQL是自右向左进行解析,可以先利用索引筛选掉大批数据,而不是直接进行表扫描筛选性别,而且性别的选择性比较差。