MemCached的分布式算法
在MemCached的基础里面,我们讲到MemCached是一个重要特征是它是利用客户端的计算来达到分布式效果的。
1.Cache的分类
根据缓存与应用的耦合程度将其划分为local cache和remote cache(来自于ahuaxuan的分类方式)。
local cache表示缓存的数据和应用程序在同一个JVM内,remote cache表示缓存数据在远程server上,由于local cache与应用程序的实例绑定在一起,因此,当cache更新时,涉及到Cache的同步问题,也就是说,Cache的数据在用户访问不同的应用程序实例时,应该得到同样的结果,一般的Cache server之间的Cache同步采用的是多播的方式广播给集群中的每个节点,或者只是选择其中的某些节点进行Cache的同步,但是当集群中的应用程序实例或者节点较多时,这种Cache的数据同步方案代价是巨大了,在大并发的情况下,很容易成为性能上的瓶颈。
remote Cache,表示Cache的数据在远程的server,应用程序实例通过tcp或者udp协议通过socket到远程server上获取。MemCached是属于remote cache,MemCached本身并没有分布式的能力,但是可以通过客户端的分布式算法,达到分布式的能力。
2.MemCached的客户端分布式算法
我们知道,MemCached 提供了以key,value存储的方式,以存储key=1,value=user1和key=2,value=user2两个数据的cache存储和获取为例,来看看MemCached是如何达到分布式效果的:
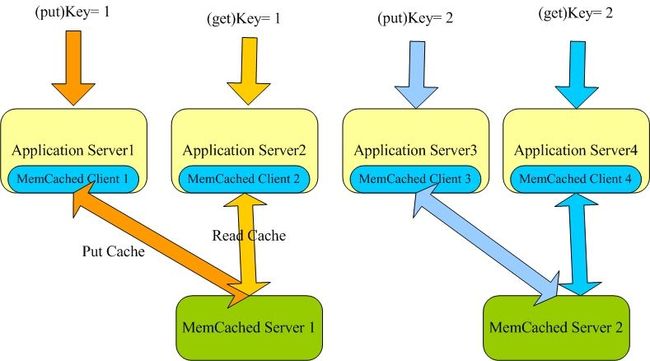
由上图可以看到,两个不同的key,存储的时候,存储在不同的MemCached Server上,当在任意一个application server分别获取这个key对应的value时,总是能正确在定位在key对象的cache server上,由此可见,通过客户端某种分布式方法,可以让数据分布在不同的cache server上,而且这种机制,只要key相同,client总是在同一个server上进行各种如put ,get,replace等操作,这种方式显然Memcached server之间的数据不需要同步。
那么客户端,如何做到把数据分散存储到不同的MemCached Server上的呢?
目前有两种非常流行的算法:
2.1求余分散(或者求余Hash)
此算法讲Key的hash值除以MemCached server的数量所得到的余数,而决定讲Cache的数据存储到哪一个MemCached Server上,仍然以刚才key=1,value=user1和key=2,value=user2两个数据为例:
对于key=1, hash值%MemCached server数量=(1%2)=1,存储到MemCached Server2上
对于key=2, hash值%MemCached server数量=(2%2)=0,存储到MemCached Server1上
显然通过这种方式,Cache的数据就会分布在不同的MemCached Server上了
对于获取Cache时,采用的是同样的算法可以定位同样的server上去获取数据
2.2 Consistent Hashing
首先求出memcached服务器(节点)的哈希值,并将其配置到0~232 的圆(continuum)上。然后用同样的方法求出 存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232 仍 然找不到服务器,就会保存到第一台memcached服务器上。

2.3 两种分布式算法的优缺点
当增加MemCache server时:
求余Hash分布式算法 回导致Cache命中率降低,例如对key=8,和9的数据,计算过程如下:
当群中只有两台MemCached server时:
8%2=0
9%2=1
三台:
8%3=2
9%3=0
由上面的计算可以看出,当cache群中加入新的server时,key对应的server几乎完全变了,这样无疑大大影响了它的缓存命中率。
使用consistent hash 的方法,影响的只是新加入server逆时针方向的server节点的命中率。