函数regexp_substr()&wm_concat()
1.需求:一个字段里存放了a,b,c,d,e这5个,但最终显示的时候我要计算他们出现的次数
regexp_substr函数,将一列转换成多行.
REGEXP_SUBSTR函数格式如下:
function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
__srcstr :需要进行正则处理的字符串
__pattern :进行匹配的正则表达式
__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
__occurrence :标识第几个匹配组,默认为1
__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)
2.将分组内子元素统计到一个字段中,串联子项
--把列值以","号分隔起来,并显示成一行

用replace()即可替换为其他分割:

扩展用法:
案例:我要写一个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 应用wm_concat来让这个需求变简单。将字段名称存入
user_tab_columns 表中,然后执行如下即可:
regexp_substr函数,将一列转换成多行.
REGEXP_SUBSTR函数格式如下:
function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
__srcstr :需要进行正则处理的字符串
__pattern :进行匹配的正则表达式
__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
__occurrence :标识第几个匹配组,默认为1
__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)
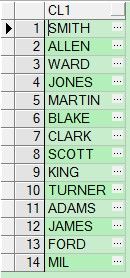
select regexp_substr('SMITH,ALLEN,WARD,JONES,MARTIN,BLAKE,CLARK,SCOTT,KING,TURNER,ADAMS,JAMES,FORD,MIL','[^,]+',1,level)
as cl1
from dual
connect by
level<=length('SMITH,ALLEN,WARD,JONES,MARTIN,BLAKE,CLARK,SCOTT,KING,TURNER,ADAMS,JAMES,FORD,MIL')-
length(replace('SMITH,ALLEN,WARD,JONES,MARTIN,BLAKE,CLARK,SCOTT,KING,TURNER,ADAMS,JAMES,FORD,MIL',',',''))+1;
2.将分组内子元素统计到一个字段中,串联子项
--把列值以","号分隔起来,并显示成一行
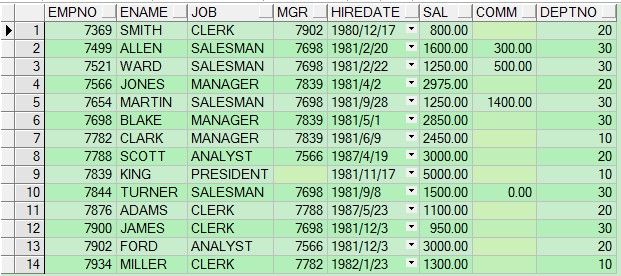
select * from scott.emp;
--串联子项 select tt.deptno,tt.allchild from(select d.deptno,WMSYS.WM_CONCAT(D.ENAME) OVER (partition by d.deptno order by d.ENAME) as allchild, row_number() over(partition by d.deptno order by d.ENAME) as rn, count(*) over(partition by d.deptno) as cn from scott.emp d) tt where tt.rn=tt.cn;
用replace()即可替换为其他分割:
select tt.deptno,tt.allchild from(select d.deptno,replace(WMSYS.WM_CONCAT(D.ENAME)OVER (partition by d.deptno order by d.ENAME),',','|') as allchild, row_number() over(partition by d.deptno order by d.ENAME) as rn, count(*) over(partition by d.deptno) as cn from scott.emp d) tt where tt.rn=tt.cn;
扩展用法:
案例:我要写一个视图,类似"create or replace view as select 字段1,...字段50 from tablename" ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法? 应用wm_concat来让这个需求变简单。将字段名称存入
user_tab_columns 表中,然后执行如下即可:
select 'create or replace view as select '|| wm_concat(column_name) || ' from dept'from user_tab_columns where table_name='DEPT';