在lucene4以前,一直都是使用经典的向量空间模型作为其检索模型,这种方式虽然统一了评分算法,简化了计算,但是带来的问题是很难去调整,一旦向量空间模型不适合,也很难去替换一种更好的算法。
而lucene4则将检索模型与事实上的搜索做了解耦和抽象,并且加入了另外几种检索模型的实现,其中就有经典的BM25。
经典的向量空间模型的理论基础及其在lucene中的应用
向量空间模型是信息检索领域中一种成熟和基础的检索模型。这种方法以3维空间中的向量作为类比,维度就是做好索引的term,比如这里以3个主要的关键词奥巴马,叙利亚和战争为三个维度,通过文档在各个维度上的权重,每个文档以及查询都会在空间中有一个向量,直观的看起来,两个向量越相似,则他们的夹角越小,所以,用起反比的cos,则可以得到,cos值越大,则两个向量越相似。同理便可以将3维空间推广到多维空间去。
用向量空间模型,便将相关性转化为相似性,根据点积和模的定义,可以得到下式:
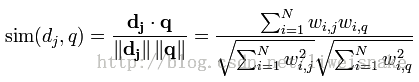
现在的问题就变成,如何求得每个维度上的term在文档中的权重,在向量空间模型中,特征权重的计算框架是TF*IDF框架,这里TF就是term在文档中的词频,TF值越大,说明该篇文档相对于这个term来说更加重要,因此,权重应该更高;而IDF则是term在整个文档集中占的比重,即n/N,其中n是含该term的文档数,N是总文档数,但是,实际使用中往往习惯用
即所包含的该term的文档数越少说明该term越重要。可以举个例子,有100篇文档,其中80篇都在说红楼梦,其中只有几篇讲到计算机,当你在这个文档集中搜索到计算机时,可以肯定这几篇讲计算机的比较重要,而搜索红楼梦时,则很难区分哪篇更加重要,换句话说,在这个文档集合中,计算机比红楼梦更有区分度,相对来说,计算机比红楼梦更有信息量,所以IDF就是评判所含信息量大小的一个值。
一般情况,使用TF*IDF作为这里的权重w,从而计算出dj,q的相似度sim(dj,q)。
那么,在lucene中,是如何应用这个模型的呢?根据向量空间模型的的数学推导(见参考文档3),可以看到,在lucene中实际上是将sim(dj,q)变形和调整后应用了如下一个打分公式
![]()
该公式各项参数解释如下,在DefaultSimilarity中都有每一项参数的基本定义:
coord(q,d): 协调因子,它的计算是基于文档d中所包含的所有可供查询的词条数量
queryNorm: 在给出每个查询条目的方差和后,计算某查询的标准化值,即(关于valueForNormalization,见后面分析第a步)
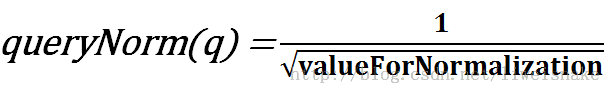
tf: 单词t在文档d中出现的词频,对词频开根号是希望对一篇出现太多相同关键词的文章进行相应的惩罚,即
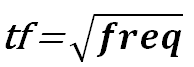
idf: 单词t在文档集中的比重。注意这个公式,首先为什么要加1,假设不加1,设想极端情况后面的log为0时(numDocs/docFreq+1 = 1), 带入打分公式,则该文档打分为0,也就是说该关键词分布得广反而一点分都没有了,事实上我们在这里只需要稍作惩罚,加1之后保证任何情况下这里都是有值的。其次,docFreq后为什么要加1呢,当然是为了防止docFreq为0作为除数的情况。所以原始的公式其实是idf(t) = log(numDocs/docFreq),与上面的分析一致
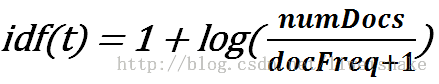
t.getBoost(): 在搜索过程中影响评分的参数
norm(t,d): 字段的标准化值,表明在字段中存储了多少词条,这个数值是在索引过程中计算出来的,并且也存储在索引中,可以在TFIDFSimScorer中的norms找到,其中一个参数LengthNorm是在DefaultSimilarity中定义的,另一个参数则是每次索引过程中每次处理一个field时累乘上去的。
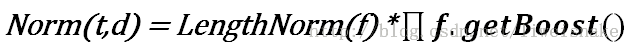
在3.0以前还有另一个参数用来提升Document的加权,可以在Document中找到setBoost,但是4.0以后取缔了,如需要模拟文档的加权,在IndexableField中建议应当自行加权多个Field。
lucene中如何组织这个公式呢?
在TFIDFSimScorer中,可以找到
- public float score(int doc, float freq) {
- final float raw = tf(freq) * weightValue; // compute tf(f)*weight
- return norms == null ? raw : raw * decodeNormValue(norms.get(doc)); // normalize for field
- }
注意到weightValue其实是stats.value,即IDFStats中的value,该value的计算其实是IndexSearcher中createNormalizedWeight产生的,如下
- float v = weight.getValueForNormalization(); a)
- float norm = getSimilarity().queryNorm(v); b)
- weight.normalize(norm, 1.0f); c)
其中,a)的计算其实就是![]()
b)的计算就是
通过这两步计算得出打分公式中的queryNorm。
c)步的计算可以得到,可以看出来,这是打分公式的一部分
![]()
从score()中可以看出来,score的结果其实是,其实已经基本是打分公式了。
到这里,已经基本上解释了打分公式在代码中的组织。接下来,我们最关心的就是。
打分公式能够如何去影响我们的文档打分和排序
下面是彩色的打分公式,接下来打分公式如何去影响文档的打分和排序时的文字色彩就对应了该彩色打分公式的色彩:
![]()
1. 搜索时加权,即上式中t.getBoost(),在搜索时加权,即在搜索关键字后带^和权值

2. 索引时加权,即上式中的norm(t, d)部分中的所有field的boost之积
如下例,将文档1的加权设置为2之后,同样的搜索条件,文档1的评分增加了
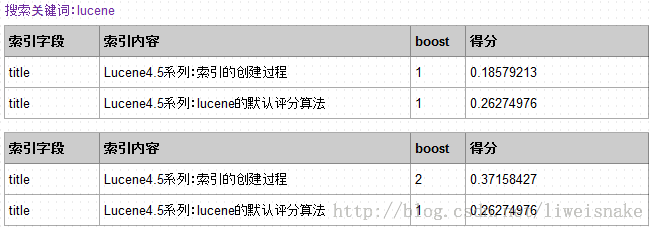
在索引过程中可以通过下面的语句设置字段加权,这也是影响评分最常见的方式
- Field.setBoost(boost)
3. 继承TFIDFSimilarity或DefaultSimilarity,对整个公式的控制。
coord:当你键入搜索关键词“奥巴马 叙利亚”的时候,你一定希望同时出现两个词的文档排在只出现"奥巴马"的文档之前,某种程度上讲,同时出现两个词意味着更加精确。请看例子,第1篇文档只命中一个词,而第二篇文档同时命中2个词,因而得分较高(此处还有tf的因素,即lucene出现了两次,但是在这里影响不大)

coord的计算是在DefaultSimilarity中定义的,因而可以修改它,maxOverlap其实就是搜索的总词数,而overlap则是该文档中实际出现了多少搜索词数
- public float coord(int overlap, int maxOverlap) {
- return overlap / (float)maxOverlap;
- }
queryNorm:queryNorm并不能影响不同文档的得分顺序,但是可以影响整体的评分大小,比如,可以修改实现,让其变为1/sumOfSquaredWeights以便减小所有文档的得分或者增大文档得分。
- public float queryNorm(float sumOfSquaredWeights) {
- return (float)(1.0 / Math.sqrt(sumOfSquaredWeights));
- }
tf:tf的在DefaultSimilarity中的定义不能影响文档得分排序,但是它的参数freq,即词频是会影响得分的,可以看以下例子

我们会发现它的得分提升并不是线性的,跟下式吻合
- public float tf(float freq) {
- return (float)Math.sqrt(freq);
- }
idf:idf主要跟单词在文档中的个数有关系,如下,同样搜索关键词“过程 算法”,第一个例子中由于第2篇文档长度较长,因而得分较低;但是如果加入一篇新的文档,由于第1,3篇文档都含有关键字"过程",因而增加了文档频率docFreq,故根据程序,评分会下降,而只含有"算法"的文档2评分就相对高了

- public float idf(long docFreq, long numDocs) {
- return (float)(Math.log(numDocs/(double)(docFreq+1)) + 1.0);
- }
lengthNorm: 同等的搜索条件下,文档长度较长者得分较低
请看如下文档长度对得分和顺序影响的例子,从中可以看出来,对“索引 算法”这组关键词,文档1中有前者,文档2中有后者 ,同样搜索这组关键词,当文档2长度较长时得分较低,而当文档2长度较短时得分较高

在DefaultSimilarity中程序如下
- public float lengthNorm(FieldInvertState state) {
- final int numTerms;
- if (discountOverlaps)
- numTerms = state.getLength() - state.getNumOverlap();
- else
- numTerms = state.getLength();
- return state.getBoost() * ((float) (1.0 / Math.sqrt(numTerms)));
- }
参考文档:wiki http://zh.wikipedia.org/wiki/%E5%90%91%E9%87%8F%E7%A9%BA%E9%96%93%E6%A8%A1%E5%9E%8B
TF-IDF http://zh.wikipedia.org/wiki/TF-IDF
向量空间模型 http://book.51cto.com/art/201008/219501.htm
向量空间模型到打分公式的数学推导 http://www.cnblogs.com/forfuture1978/archive/2010/03/07/1680007.html
http://blog.csdn.net/liweisnake/article/details/11229937