在开始之前,先对IndexWriter的所需要考虑的问题有个大致的了解。IndexWriter主要负责索引数据写入,所以,增删改是主要需要考虑的问题;其次,由于写入的过程涉及成功失败的问题,所以,事务以及二阶段事务也是应该考虑到的;再来就是需要写入过程有最大的吞吐量,所以,还存在缓存以及刷新的问题;另外,如何让多线程高效并发访问索引也是要思考的;还有,通常查找内容的数量都非常庞大,如何管理索引过程中的内存以及磁盘消耗也是值得考虑的事情。接下来的文章,会对这些问题分别分析。
索引的增删改
增加,下面的api主要是加入一个或多个文档,以及对这篇文档使用的analyzer。实际上,增加文档在背后是调用了更新这一操作。它所提供的接口无非是单文档和多文档,有分析器和无分析器的区别。
- public void addDocument(IndexDocument doc) throws IOException
- public void addDocument(IndexDocument doc, Analyzer analyzer) throws IOException
- public void addDocuments(Iterable<? extends IndexDocument> docs) throws IOException
- public void addDocuments(Iterable<? extends IndexDocument> docs, Analyzer analyzer) throws IOException
更新,需要明白的是,更新并非像数据库一样,而是一个先删除后增加的过程
- public void updateDocuments(Term delTerm, Iterable<? extends IndexDocument> docs) throws IOException
- public void updateDocuments(Term delTerm, Iterable<? extends IndexDocument> docs, Analyzer analyzer) throws IOException
- public void updateDocument(Term term, IndexDocument doc) throws IOException
- public void updateDocument(Term term, IndexDocument doc, Analyzer analyzer)
- throws IOException
删除,第一种方式是删除所有包含这个词的文档,第二种方式是删除所有包含这几个词的文档,第三种方式是删除所有符合该查询的文档,第四种方式是删除所有符合这组查询的文档,第五种方式是直接删除所有文档
- public void deleteDocuments(Term term) throws IOException
- public void deleteDocuments(Term... terms) throws IOException
- public void deleteDocuments(Query query) throws IOException
- public void deleteDocuments(Query... queries) throws IOException
- public void deleteAll() throws IOException
在更深入的讨论前先理下索引的链式结构,因为这个神奇的结构经常把人搞得云里雾里。默认的索引链在DocumentsWriterPerThread中有初始化。代码如下:
- static final IndexingChain defaultIndexingChain = new IndexingChain() {
- @Override
- DocConsumer getChain(DocumentsWriterPerThread documentsWriterPerThread) {
- /*
- This is the current indexing chain:
- DocConsumer / DocConsumerPerThread
- --> code: DocFieldProcessor
- --> DocFieldConsumer / DocFieldConsumerPerField
- --> code: DocFieldConsumers / DocFieldConsumersPerField
- --> code: DocInverter / DocInverterPerField
- --> InvertedDocConsumer / InvertedDocConsumerPerField
- --> code: TermsHash / TermsHashPerField
- --> TermsHashConsumer / TermsHashConsumerPerField
- --> code: FreqProxTermsWriter / FreqProxTermsWriterPerField
- --> code: TermVectorsTermsWriter / TermVectorsTermsWriterPerField
- --> InvertedDocEndConsumer / InvertedDocConsumerPerField
- --> code: NormsConsumer / NormsConsumerPerField
- --> StoredFieldsConsumer
- --> TwoStoredFieldConsumers
- -> code: StoredFieldsProcessor
- -> code: DocValuesProcessor
- */
- // Build up indexing chain:
- final TermsHashConsumer termVectorsWriter = new TermVectorsConsumer(documentsWriterPerThread);
- final TermsHashConsumer freqProxWriter = new FreqProxTermsWriter();
- final InvertedDocConsumer termsHash = new TermsHash(documentsWriterPerThread, freqProxWriter, true,
- new TermsHash(documentsWriterPerThread, termVectorsWriter, false, null));
- final NormsConsumer normsWriter = new NormsConsumer();
- final DocInverter docInverter = new DocInverter(documentsWriterPerThread.docState, termsHash, normsWriter);
- final StoredFieldsConsumer storedFields = new TwoStoredFieldsConsumers(
- new StoredFieldsProcessor(documentsWriterPerThread),
- new DocValuesProcessor(documentsWriterPerThread.bytesUsed));
- return new DocFieldProcessor(documentsWriterPerThread, docInverter, storedFields);
- }
- };
之所以说它是一个索引链,因为它把整个请求层层向下链状传递(注意这不是真正的责任链模式,虽然非常像,因为它们并不是一个统一的接口)。最上层的领导发话要做什么,都经过层层传递,每层分解任务做一小部分,然后把剩余的向下传递,直到最下层最终执行完任务。而且这个责任链比较整齐的一点是,从触发点DocConsumer开始,都hold住两个对象(他们都是consumer),并且先后被调用。最下层的TeamVectorsWriter实际上已经是解码器的范畴了。lucene4比起lucene3做了一些改进,取缔了*PerThread的一堆类和结构,我猜测lucene3是一个更细粒度的线程同步,对下面的每个小组件都做了同步的选择(即PerThread),但是实际上发现,最后一般都使用粗粒度的同步,就是DocumentsWriterPerThread,从这里向下的方法都是同步的结果。
下图是PerField的索引链,add和update实际上就是通过这条链向下传递的。

这里用我的文章作为例子来讲解lucene是如何将这样的文档变为倒排索引结构的,假设有如下1篇文章,简化考虑,他们只有3个field:title和content和author

主要的执行过程在DocFieldProcessor的processDocument中,有这么几个主要步骤(只是为了说明主体,实际上还有很多细节):

可以看到这几个主要的组件的组织非常有逻辑,基本上保持着朴素的分治思想,他们的主要作用如下:
1. DocFieldProcessor: 主要是处理遇到的单个文档,也就是说每碰到一个文档就会有一个DocFieldProcessor来进行相应的处理。
2. DocFieldProcessorPerField: 主要是将文档按field来归类分好,以便将任务分解,经过DocFieldProcessorPerField,可以发现整个文档已经被归类为了许多fields,接下来可以分别对每个field的进行处理,如下图:
3. DocInverterPerField: 主要是对每个field中的fieldsData做语汇单元的分析处理,经过这步以后,每次处理的就只是一个term
4. TermHashPerField: 记录将上一步的term映射到缓冲区中后的各种信息,它会生成部分的postingsArray以及填充term的文本缓冲区。TermHashPerField中最重要的结构就是postingsArray,可以把它理解为二维数组,如图:termID其实就是获取每条记录的key,每条记录其实就是记录每个词的一些元信息。其中最重要的是textStarts,byteStarts,intStarts以及termFreqs,termFreqs很好理解,其实就是记录了词频,比如“的”字出现了3次,因此termFreqs为3.
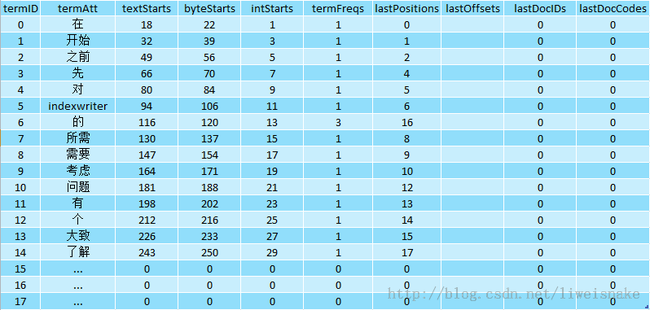
那么textStarts,byteStarts,intStarts分别是什么呢?
在lucene3中,有三个重要的结构作为索引在内存的缓冲,它们分别是IntBlockPool, ByteBlockPool和TextBlockPool,其中IntBlockPool存在的目的是指示docid(文档号),freq(词频)和prox(位置)在ByteBlockPool中的位置,而byteBlockPool专门存放docId,freq,prox,因为存放的字节可能不等,所以需要IntBlockPool的位置指示;而TextBlockPool则存放真正的term文本。而到了lucene4,这个结构有了稍微的改变,TextBlockPool合并到了ByteBlockPool。下面,我们对这两个重要的缓冲区和postingArray的关系展开说明,事实上,只需要了解这两个缓冲区的数据结构,便能清楚的知道这个整体的结构。

从之前的postingsArray来看,我们有textStarts,它主要作用是指示term文本内容的位置,这样,每个term都能根据textStarts迅速定位到term文本;从图中可以看出来,对应“的”的textStarts指示的位置就能够定位到ByteBlockPool中第116个字节,这里首先指示了接下来三个字节是我们的文本,于是,从117到119就可以确定是文本了。接下来byteStarts指示的是docid,freq和prox开始的位置,即ByteBlockPool的第120个位置;IntBlockPool紧邻的两个数值分别指示docid,freq与prox,intStarts指示13,于是位于IntBlockPool的第13个字节120就是docid,freq在ByteBlockPool中的位置,位于128的就是prox的下一个待写入位置。如此一来,我们就完成了从postingsArray到Pool的映射。
当然,这里远远没有了解所有问题。比如docid,freq和prox为什么都以16结尾,他们每块为什么都是5个字节?如果同一个term重复了多次,docid和prox会有多份,应当如何记录?为什么在这个例子中ByteBlockPool第一个term只有docid,freq而没有prox?
实际上,这部分问题是比较复杂的。这里尝试用一个简单的例子讲解。这次,我们向同一个文档中加了6个同样的词,如下

整个结构会变为

首先解释为什么每块5个字节,结束位置是16. 请看ByteBlockPool代码,每次空间不够时,会按照固定好的数组来分配空间。每次分配时按照层级,一共有9层,NEXT_LEVEL_ARRAY规定了这点,每层的byte数量在LEVEL_SIZE_ARRAY中规定,比如刚开始是第一层,会分配好5个bytes,(byte) (16|newLevel)便定义了第1层的结束标志为16,第2层(实际上newLevel为1)为17,以此类推……而这个结束标志16不仅表明该块结束,而且还能通过该数字反推出目前的块到底是第几层。
- public final static int[] NEXT_LEVEL_ARRAY = {1, 2, 3, 4, 5, 6, 7, 8, 9, 9};
- public final static int[] LEVEL_SIZE_ARRAY = {5, 14, 20, 30, 40, 40, 80, 80, 120, 200};
- public int allocSlice(final byte[] slice, final int upto) {
- final int level = slice[upto] & 15;
- final int newLevel = NEXT_LEVEL_ARRAY[level];
- final int newSize = LEVEL_SIZE_ARRAY[newLevel];
- // Maybe allocate another block
- if (byteUpto > BYTE_BLOCK_SIZE-newSize) {
- nextBuffer();
- }
- final int newUpto = byteUpto;
- final int offset = newUpto + byteOffset;
- byteUpto += newSize;
- // Copy forward the past 3 bytes (which we are about
- // to overwrite with the forwarding address):
- buffer[newUpto] = slice[upto-3];
- buffer[newUpto+1] = slice[upto-2];
- buffer[newUpto+2] = slice[upto-1];
- // Write forwarding address at end of last slice:
- slice[upto-3] = (byte) (offset >>> 24);
- slice[upto-2] = (byte) (offset >>> 16);
- slice[upto-1] = (byte) (offset >>> 8);
- slice[upto] = (byte) offset;
- // Write new level:
- buffer[byteUpto-1] = (byte) (16|newLevel);
- return newUpto+3;
- }
其次应当注意两个原则:差值原则和变长原则,请参见索引的文件格式一文。
接下来,基本上与上面一样,不同的是prox需要记录很多词的位置,是如何做呢,第一个term“索引”到来会在12处记录位置为0,第二个“索引”会在13处记录位置为4(增量),第三个会在14处记录4,第四个会在15处记录4,而第5个会发现已经没有空间了(16不能被占用),于是分配第二层块,插入到ByteBlockPool后面。查LEVEL_SIZE_ARRAY得知,块大小为14,块的结束符为17(例子中17-30就是第二层块),于是将16前面的3个字节向后移动到第二层块的起始位置,连同16共4个字节用于指向下一层的指针,指示下一个块的地址,在本例中将13-15中的4移动到17-19,将16指向了17,再将第5个4放到20,第6个4放到21。这个动态的过程如下,左边序号代表到来的term“索引”:

为什么需要4个字节的指针?本例中不是一个字节就搞定了吗?当然这是为了支持更大的Pool。那又为什么需要指针呢,从上面来看16就指向了17,完全没有必要,但是这只是一个特例,lucene采用的方法是非常高效的,为了避免在待扩展块后面直接插入扩展块(即在有序数组的中间来扩展),lucene会将扩展块放到ByteBlockPool的最后,这样一来,省去了每次扩展时对数组的一个大规模移动,只需要用指针来换取这种移动。
关于doc和freq也是类似的,这里就不再赘述。
最后,为什么在我们最初的例子中只有docid而没有prox,事实上,这与选择的Field有关系,对于author这个field,我选择了StringField,它的IndexOptions为DOCS_ONLY,意味着我们将只会记录docid,忽略了freq和prox
5. FreqProxTermsWriterPerField: 将最终分析的prox, offset以及lastDocIDs, lastDocCodes等信息记录下来。其实这部所做的事情已经在上面分析过了。
接下来的问题是,当添加或者更新完毕之后,这些数据会立即写入磁盘吗?答案是不会。lucene会在flush的时候将缓冲区的数据写入磁盘。FreqProxTermWriterPerField中的flush方法就负责这件事。关于缓存及刷新,请参考后续文章
参考文档:Lucene索引过程分析(2) http://www.cnblogs.com/forfuture1978/archive/2010/02/02/1661440.html
Lucene索引过程分析(3) http://www.cnblogs.com/forfuture1978/archive/2010/02/02/1661441.html
Annotated lucene
http://blog.csdn.net/liweisnake/article/details/11364597