作者:Leslie Lamport. 1978
原文:http://www.stanford.edu/class/cs240/readings/lamport.pdf
译者:phylips@bmy 2012-10-13
译文:http://duanple.blog.163.com/blog/static/709717672012920101343237/
[
序: 时间是一个很抽象的概念,爱因斯坦说时间是幻觉,马赫(Ernst Mach)说:我们根本沒有能力以时间來测量事物的变化,相反的,我们是透过事物的变化因而产生时间流动的抽象概念。那么在分布式系统中是如何定义时序的 呢?这篇论文进行了讨论,该论文首先通过定义一整套逻辑时钟系统对所有事件进行ordering,然后通过解决一个资源互斥访问问题说明了如何将此应用到 分布式系统中,并引入了状态机复制的方法。之后又由逻辑时钟所存在的一个问题引出了物理时钟的使用,由于物理时钟本身会存在偏差,又给出了一个物理时钟同 步算法,并给出了一个关于物理时钟同步的定理。
该论文于 1978年7月发表在”Communication of ACM”上,并于2000年获得了首届PODC最具影响力论文奖,于2007年获得了ACM SIGOPS Hall of Fame Award 。关于该论文的贡献是这样描述的:本文包含了两个重要的想法,每个都成为了主导分布式计算领域研究十多年甚至更长时间的重要课题。
1. 关于分布式系统中事件发生的先后关系(又称为clock condition)的精确定义和用来对分布式系统中的事件时序进行定义和确定的框架。用于实现clock condition的最简单方式,就是由Lamport在本文中提出的”logical clocks”,这一概念在该领域产生了深远的影响,这也是该论文被引用地如此之多的原因。同时它也开启了人们关于vector 和 matrix clock ,consistent cuts概念(解决了如何定义分布式系统中的状态这一问题),stable and nonstable predicate detection,认识逻辑(比如用于描述分布式协议的一些知识,常识和定理)的语义基础等方面的研究。最后,最重要的是它非常早地指出了分布式系统与 其他系统的本质不同,同时它也是第一篇给出了可以用来描述这些不同的数学理论基础(“happen before”relation)。
2. 状态机方法作为n-模块冗余的一种通用化实现,无论是对于分布式计算的理论还是实践来说,其非凡的影响力都已经被证明了。该论文还给出了一个分布式互斥协 议,以保证对于互斥区的访问权限是按照请求的先后顺序获取的。更重要的是,该论文还解释了如何将该协议用来作为管理replication的通用方法。从 该方法还引出了如下问题:
a)Byzantine agreement,那些用来保证所有的状态机即使在出错情况下也能够得到相同输入的协议。很多工作都是源于这个问题,包括fast protocols, impossibility results, failure model hierarchies等等。
b)Byzantine clock synchronization 和ordered multicast protocols。这些协议是用来对并发请求进行排序并保证得到相同的排序结果,通过与agreement协议结合可以保证所有状态机都具有相同的状态。
关于这篇论文,作者Leslie Lamport自己有这样的描述:
“Jim Gray曾经告诉我他听到的关于该论文的两种观点,一种是觉得该论文太普通了,另一种则认为该论文太绝妙了。对此,我并不想争辩什么。
这 篇论文的灵感实际上是源自于Paul Johnson和Bob Thomas写的一篇名为”The Maintenance of Duplicate Databases”的文章。他们在这篇文章中提出了在分布式系统中为消息使用时间戳的想法。只是因为我本身恰巧对狭义相对论有比较深刻的理解,这使我敏 锐地察觉到他们所做的工作的本质。狭义相对论告诉我们时空中的事件并不存在一个始终如一的全序关系;不同的观察者对两个事件谁先发生可能具有不同的看法。 当且仅当事件e2是由事件e1引起的时候,事件e1和e2之间才存在一个先后关系。我意识到Paul Johnson和Bob Thomas采用的算法的本质是通过时间戳来提供一个事件的全序关系,而这本质上与事件间的因果关系是一致的。这个想法实在是太绝妙了,意识到这点后,其 他的都显得很简单了。由于Paul Johnson和Bob Thomas并没有理解他们真正所在做的事情,因此他们的算法并不完全正确,那个算法允许一些会打乱因果关系的异常行为的发生。我赶紧记录下了关于这个问 题的这些想法,并修正了他们的算法。
之后,我很快就意识到该定义事件全序关系的算法可以用 来实现任意的分布式系统。一个分布式系统可以描述为一个特殊的具有多个由网络互联的处理器的串行状态机。如果能够对输入请求进行全排序,就能够实现任何由 网络互联的处理器组成的状态机,因此也就可以实现任意的分布式系统。为了表明这一点,论文采用了一个我能想到的最简单的分布式系统实例—分布式互斥算法作 为例子。
该论文也是我的论文中被引用最多的。很多计算机科 学家都声称读过。但是我碰到的人中,很少有人意识到该论文在说状态机相关的东西。看起来他们认为该论文是在讲分布式系统中事件的时序关系,或者是分布式互 斥算法。有些人还坚持声称该论文根本跟状态机无关,搞得我甚至重新回头读下这篇文章来确定我确实记得我写了什么。
该论文中描述了逻辑时钟的同步方法。之后我又开始思考另一个问题,即真实时钟的同步问题,并由此引入了一个关于真实时钟同步的理论。同时我也惊奇地发现要提供证明太困难了,当然这也为后面的Byzantine clock synchronization{!即论文Byzantine clock synchronization}提供了一些基础,只是那已经是另一个故事了。”
另 外在一次采访中,当提问者问到“你认为你的哪个贡献对现代计算机科学与产业具有最大的影响力?”,Leslie Lamport是这样回答的“我的引用量最多的文章是“Time, Clock, and Ordering of Events in a Distributed System”,我不知道这和你说的影响是不是一回事,因为我并不能从该文章直接指导出许多工作,但可能它影响了人们思考分布式系统的方法。我认为我在工 业界还没有太多影响,虽然我期望Paxos 和状态机方法将在分布式系统设计上有重要影响。在微软内部已经可以看到这一点(Lamport 目前在微软研究院工作)”。这个回答还是很谦虚的,随着海量数据处理需求的增加, 在各种分布式系统大行其道的今天,Paxos及各种分布式算法已经发挥着越来越重要的作用,感觉也该给Lamport一个图灵奖了,只是不知道还要等几 年。
除了这篇,Leslie Lamport还发表了其他一些关于time,clock在分布式系统中应用的文章,”The Implementation of Reliable Distributed Multiprocess Systems”(1978),”Using Time Instead of Timeout for Fault-Tolerant Distributed Systems”(1984),“Byzantine clock synchronization”(1984), “Synchronizing Clocks in the Presence of Faults”(1985)等。
另 外看时钟同步这个问题,在该论文中也涉及了时钟同步技术的原理,方法及应用。在该论文发表后的1981年,人们提出了Internet Clock Protocol(RFC 778),这是最早提出的Internet时间同步协议;1983年提出了Time Protocol(RFC 868),该协议可以精确到1s;1988年提出了NTP协议(Network Time Protocol RFC 1059),在广域网内使用NTP协议进行同步,可以达到几十毫秒的精度,在局域网内精度可以达到0.1毫秒;1996年,又提出了NTP协议的简化版 SNTP(RFC 2030),它可以用于对时间精度要求比较低的场景。2000年11月,IEEE成立网络精密时钟同步委员会,2002年9月通过了IEEE 1588标准,IEEE 1588 PTP协议借鉴了NTP技术,具有容易配置·、快速收敛以及对网络带宽和资源消耗少等特点。IEEE1588标准的全称是“网络测量和控制系统的精密时钟 同步协议标准(IEEE 1588 Precision Clock Synchronization Protocol)”,简称PTP(Precision Timing Protocol),基本构思是通过硬件和软件将网络设备(客户机)的内时钟与主控机的主时钟实现同步,提供同步建立时间小于10μs的运用(应该是单链 路内的),与未执行IEEE1588协议的以太网延迟时间1000μs相比,整个网络的定时同步指标有显著的改善。
近 来Google发表的Spanner中提到的TrueTime API,这也是实现该系统各重要feature的基础。要真正理解TrueTime API在这篇论文中的重要意义,就得了解为何要得到事件的一个全序关系,得到这样的关系可以做什么,以及如何得到这样的一个关系。读完这篇论文,就能发现 其实早在30多年前Leslie Lamport就开始考虑这些问题,而且当时的思考已经非常深刻,即使是在今天看来,这些思考依然是如此深刻和富有远见。而关于时钟同步这个问题,实际上 历史要更为悠久,即使是在Leslie Lamport发表这篇论文时,人们已经进行了非常多的研究。
]
摘要
在 本文中我们审视了分布式系统中,某事件发生在另一事件之前这一概念,并展示了如何用它来定义事件间的偏序关系(partial order)。给出了一个可以对具有逻辑时钟的系统进行同步的算法,通过逻辑时钟可以得到事件的全序关系(total ordering)。通过作为解决同步(synchronizing)问题的一种方法,我们展示了total ordering的使用方法。进一步地,该算法还可以被特化用来解决物理时钟的同步问题,同时我们推导出了时钟可能达到的不同步的一个误差范围。
关键词:分布式系统 计算机网络 时钟同步 多进程系统
导引
对 于我们的思维来说,时间是一个非常基础的概念。它实际上源于更基础的概念--事件发生的顺序。如果某件事情在我们的时钟指示在3:15且还未指示3:16 之前,我们就是这件事发生在3:15。事件的时序概念遍布在我们对系统的思考中。比如,在一个航线预订系统中,我们会这样表述,如果预订请求是在该航线被 分配出去之前发出的,那么该请求应该得到授权。但是,我们将看到对于分布式系统中的事件来说,需要对这个概念重新仔细地进行审视。
一 个分布式系统由一系列在空间上分离的多个进程组成,这些进程相互之间通过交换消息进行通信。一个由互联的计算机组成的网络系统,比如APRA网,就是一个 分布式系统。单个计算机也可以看做是由中央处理单元,内存单元,IO通道这些独立处理单元组成的分布式系统。如果消息传输延迟与单个处理单元内部事件时间 间隔相比差别明显,那么该系统就可以认为是分布式的。
本文中我们主要关注由空间上分离的多个独立计算机组成的系统。但是,我们的很多观点都可以应用在更普遍的情况。特别地,一个单个计算机上的多进程系统所涉及的问题实际上也非常类似于分布式系统所涉及的那些,因为在这样的系统上某些事件也可能是以不可预测的顺序发生的。
在分布式系统中,有时候很难去说两个事件谁先发生。而”发生在前(happen before)”这一关系只是定义了分布式系统中的事件的一个偏序关系(partial ordering)。我们发现人们经常由于没有意识到这一点及其所代表的含义,而导致一些问题的发生。
在 本文中,我们讨论了由”发生在前(happen before)”这一关系所定义的事件的偏序关系(partial ordering),同时给出了一个分布式算法,该算法可以将其扩展以得到一个所有事件的全序关系。该算法提供了一个实现分布式系统的非常有用的机制。我 们通过使用它来实现一种解决同步问题的简单方法来展示它的使用方法。不幸的是,如果通过该算法得到的事件排序与用户感知到的不同,可能会发生一些异常行 为。该问题可以通过引入实际的物理时钟来避免。我们提出了一种对这些时钟进行同步的简单方法,同时推导出了时钟偏差可能达到的一个误差范围。
The Partial Ordering
绝 大多数人都会这样想,如果事件a发生的时间比b早就说事件a发生在事件b之前。同时他们可能还会声明这里的时间是指物理上的时间。但是如果要真的得到一个 正确的描述,还得加个限定,这里的事件是指在系统内所观察到的。如果描述中的时间是指物理时间,那么系统中还需要包含真实的时钟。即使系统中包含了真实的 时钟,仍然存在问题,因为这些时钟并不是完全精确的,也就无法保持精确的物理时间。因此我们会在不引入物理时钟的情况下定义”发生在前(happen before)”关系。
首先,我们把系统定义地更精确些。我们假设系统由一系列进程组成。每个进程包含一系列事件。事件的定义取决于应用程序,比如计算机上的一个子程序的执行可以看做是一个事件,而单个计算指令的执行也可以看做是一个事件。
我 们假设进程中的事件形成了一个序列,如果a ” happen before” b那么在序列中a就会出现在b之前。换句话说,在组成单个进程的事件集合是全序的,这也比较符合单个进程的实际情况。(注:关于事件组成的定义可能会影响 到进程内对事件的排序。比如消息的接收可能只是设置了计算机中的一个中断位,然后再由子程序处理这个中断,由于中断的处理并不一定按照它们产生的顺序,这 样这个设定就会影响到进程的消息接收事件的顺序)。当然我们也可以对我们的定义进行扩展,从而将单个进程划分为多个子程序,但是我们并没有必要搞这样麻 烦。
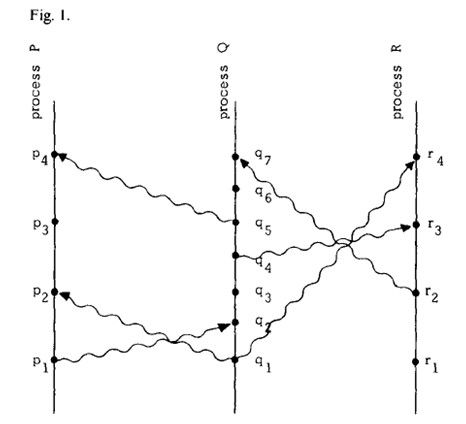
我们假设消息的发送和接收也是进程中的一个事件。下面我们就可以定义” happen before”关系,简写为”->”,如下所示:
Definition. 在系统中的事件集合上的”->”关系,是满足如下三个条件的最小关系:(1)如果a和b是同一个进程中的事件,并且a在b前面发生,那么 a->b。(2)如果a代表了某个进程的消息发送事件,b代表另一进程中针对这同一个消息的接收事件,那么a->b。(3)如何 a->b且b->c,那么a->c。{!这里的关系实际上就是离散数学中的关系,通常一个关系具有的性质有自反性,传递性,反自反性, 对称性,反对称性,(3)说明”->”关系具有传递性,此外下文还会指出该关系不具有自反性}。如果两个不同的事件a,b满足a(!->)b 且b(!->)a,我们就说a与b是并行发生(concurrent)的。
我们假设对于任意事件a,a(!->)a{!一个事件本身可以发生在其自身之前的系统本身也没有什么物理意义}。这意味着”->”是一个在系统的所有事件集合上的不具备自反性的偏序关系。
通 过在如图1那样的时空图上来理解下这个定义会比较有帮助。在图中,横轴代表了空间,纵轴代表了时间—坐标值越大时间越靠后。点代表了事件,垂直线代表了进 程,曲线代表了消息(注:从图中可以看出消息可能会被乱序地收到。虽然我们允许将多个消息的发送看做是一个事件,但是为了方便起见,我们还是假设单个消息 的接收不会与其他消息的接收和发送重合)。很容易看出,a->b意味着可以在图中沿着进程线和时间线从a到达b。比如,图1 中,p1->r4。
也可以换一种方式来理解该定义,比如可以认为a->b意味 着是事件a导致了事件b的发生。如果两个事件相互之间没有因果关系,我们就认为它们是并行发生 (concurrent)的。比如图1中的p3和q3就是concurrent的。尽管图画地让人觉得q3比p3发生的物理时间要早,但是进程P在p4那 一点收到消息之前是根本不知道进程Q何时执行了q3的。(在事件p4之前,P进程最多能知道计划要在q3做的事情)。
这 个定义对于那些熟悉狭义相对论时空观的人应该会显得比较自然。在相对论中,事件间的顺序是通过可能被发送的(could be sent)消息来定义的。但是,我们采用了更实用的方法,只考虑那些实际中真的被发送的(actually are sent)消息。{!在狭义相对论中,如果事件a是事件b的原因的话,那么在任何坐标系中,事件a都是b的原因,那么看到的都会是a先发生然后b发生。当 然事件间存在因果关系也是有条件的,需要事件间的时空距离,足以让光速可达,比如如果两个事件的空间距离非常大,而时间距离非常小,以至于光速无法在这个 时间内到达,那么这两个事件就不可能存在因果关系,参考狭义相对论基础教程}。当然如果知道了那些实际发生的事件,我们就可以判断系统是否工作正常,而不 需要知道那些可能会发生的事件。
Logical Clocks
现 在我们将clocks引入到系统中。首先我们从一个抽象的方式开始,只将clock作为为事件分配编号的方式,在这里编号就被看做是事件发生的时间。更准 确地说,我们将每个进程的clock Ci定义为一个为进程中的任意事件a分配编号Ci(a)的函数。那么整个时钟系统就可以通过一个为事件b分配编号C(b)的函数C来表示,如果b是进程 Pj中的一个事件,那么C(b)=Cj(b)。目前为止,我们没有因为编号方面的事情引入任何关于物理时钟的假设,因此时钟Ci可以看成是一个逻辑时钟而 不是物理时钟。它们可能是通过某些没有使用任何计时机制的计数器实现的。
我们现在来考虑对 于这样一个时钟系统的正确性的涵义。我们不能将定义的正确性基于物理时间之上,因为这需要引入持有物理时间的时钟。我们的定义必须基于事件发生的顺序。最 强的合理的条件是,如果事件a发生在另一个事件b之前,那么a发生的时间应该早于b。将该条件更形式化地表述如下:
Clock Condition.对于任意事件a,b:如果a->b,那么C(a) < C(b)。
需 要注意的是,我们不能期望该条件的逆命题{!即如果C(a) < C(b),那么a->b}也成立,因为这将意味着任意两个concurrent的事件必须发生在同一时间。比如在图1中,p2和p3都与q3是 concurrent的,如果逆命题也成立,那么这就意味着它们两个都与q3发生在同一个时间,而这将与Clock Condition矛盾,因为p2->p3。
通过定义可以很容易看出关系”->”定义如果要满足Clock Condition需要满足如下两个条件:
C1.如果a和b都是进程Pi里的事件,并且a在b之前,那么Ci(a)<Ci(b)
C2.如果a是进程Pi里关于某消息的发送事件,b是另一进程Pj里关于该消息的接收事件,那么Ci(a)<Cj(b)
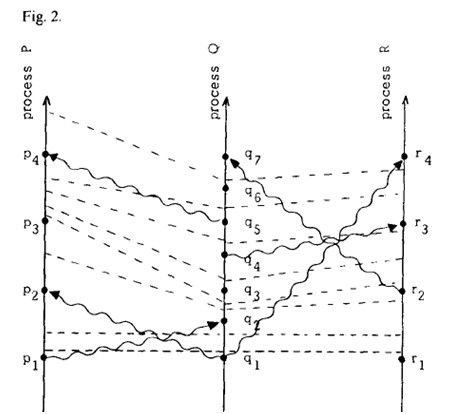
现 在我们再在时空图中考虑下该时钟。假设进程的时钟”ticks”(滴答)会穿过所有数字,同时滴答发生在进程的事件之间。比如,如果a和b是进程Pi中相 继发生的两个事件,同时Ci(a)=4且Ci(b)=7,那么在这两个事件之间时钟会滴答过5,6,7。如果我们划出一条滴答虚线使它可以连接所有进程滴 答发生的点,那么图1的时空图就会变成图2。条件C1意味着在同一进程线上任意两个事件之间都至少存在着一条滴答线,与此同时条件C2意味着每条消息线一 定会跨越至少一条滴答线,容易看出这两个条件意味着Clock Condition的成立。
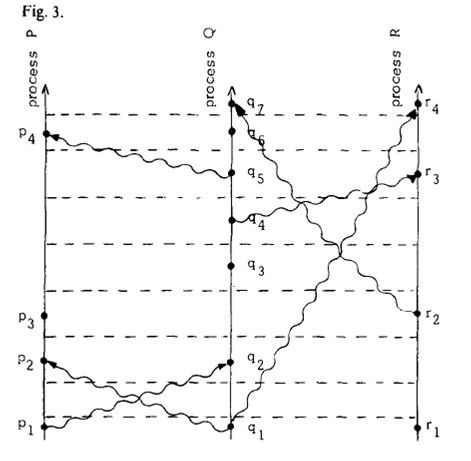
我 们可以将时钟滴答线作为在时空上的Cartesian坐标系的时间轴。这样我们就可以重绘图2中,将滴答线拉直就得到了图3。图3是对图2所描述事件的另 一种合法的描述方式。如果不把物理时间引入到系统中(这需要引入物理时钟),是没有办法去判断这些图中的哪个更好地表示了系统的情况。
读 者可能会发现如果将这些进程可视化为一个二维空间网络,这样呈现出来的就是一个三维的时空图。进程和消息仍然使用线来表示,那么滴答线就变成了一个二维平 面。{!可以这样理解,三维空间的三个坐标轴:x,y,z,xy代表了空间坐标,代表了进程所在的平面空间坐标位置,z轴代表了时间,进程线是一个垂直于 xy平面与z轴平行的直线,该线上的点代表了进程在该点对应的z轴坐标即时间点上的事件,消息线则是连接进程线上的事件点的直线,这些线上的点,代表了对 应时间,消息在平面空间上所处的位置。}
现在我们假设进程就是代表了它们执行过程中特定行 为的算法和事件。下面我们展示如何为进程引入满足Clock Condition的时钟。进程Pi的时钟是由一个寄存器Ci来表示,那么Ci(a)就代表了在事件a发生时所得到的Ci的值。Ci的值会在事件之间发生 变化,因此Ci的改变本身并不包含任何事件。
为保证系统时钟可以满足Clock Condition,我们需要确保它满足条件C1和C2。条件C1很简单,进程只需要遵守如下的实现规则即可:
IR1.每个进程Pi在任意连续的两个事件之间会增加Ci的值
为满足条件C2,我们要求每个消息m都包含一个时间戳Tm,Tm等于该消息发送时的时间。在接收到包含时间戳Tm的消息后,进程必须调整它的时钟使得它必须晚于Tm。更准确地说,我们需要如下规则:
IR2.(a)如果事件a代表了进程Pi发送消息m的事件,那么消息m包含的时间戳Tm=Ci(a).(b)在收到消息m后,进程Pj会设置Cj的值使得它大于等于它的当前值并大于Tm.
在 条件IR2(b)中,我们认为代表消息m被接收的事件发生在Cj被设置之后{!?原文是:“In IR2(b) we consider the event which represents the receipt of the message m to occur after the setting of C j. (This is just a notational nuisance, and is irrelevant in any actual implementation.”这一段如何理解,经whisper提醒,感觉这一段应该这样理解,消息m被接收与Cj被设置是两个独立的事件,这里只是 在概念上定义消息接收事件发生在进程设置Cj值之后,这样就肯定能保证消息接收事件的Cj(b)<Ci(a)即Tm}。很明显,IR2保证了条件C2的满足。因此,IR1和IR2保证了Clock Condition的满足,这样它们就保证了得到的是一个正确的逻辑时钟系统。
Ordering The Events Totally
我 们可以使用一个满足Clock Condition的时钟系统来获取系统中所有事件的一个全序关系。我们只是简单地根据事件发生的时间来对它们进行排序。为了打破平局的情况,我们使用了 进程间的任意的一个全序关系“<”。具体来说,我们定义一个新的关系“=>”如下:假设a是进程Pi中事件,b是进程Pj中的事件,那么当且 仅当满足如下条件之一时:(1)Ci(a)<Cj(b);(2)Ci(a)=Cj(b)且Pi<Pj,那么我们就认为“a=>b”。容 易看出这样就定义了一个全序关系,同时Clock Condition意味着:如果a->b那么a=>b。换句话说,关系“=>”是将”happen before”偏序关系扩展成全序关系的一种方式。
“=>”所依赖的时钟系统并不是 唯一的。不同的满足Clock Condition的时钟系统选择将会产生不同的关系“=>”。给定任意一个全序关系“=>”,都会有一个满足Clock Condition的时钟系统可以用来产生该关系。只有偏序关系“->”是由系统中的事件唯一确定的。
能 够对事件进行全排序在实现分布式系统时是非常有用的。实际上,实现一个正确的逻辑时钟系统的原因就是为了获取这样的一个全序关系。我们将会通过解决如下版 本的互斥问题来展示这个事件间全序关系的使用方法。考虑一个由固定进程集合组成的系统,这些进程需要共享一个资源。同时该资源一次只能由一个进程使用,因 此为避免冲突进程间必须进行同步。我们希望可以找到一个满足如下三个条件的算法:
(1)已经获得资源授权的进程,必须在资源分配给其他进程之前释放掉它;
(2)资源请求必须按照请求发生的顺序进行授权;
(3)在获得资源授权的所有进程最终释放资源后,所有的资源请求必须都已经被授权了。
我们假设初始时刻资源只授权给了一个进程。
这些都是非常自然的需求。它们准确地描述了正确的解所需要满足的条件。注意一下这些条件是如何与事件排序产生联系的。首先条件(2)并没有说明对于两个concurrently的事件应该首先为哪一个进行授权。
意 识到这个问题的不平凡性是非常重要的。除非进行一些额外的假设,否则使用一个中央调度进程按照资源请求被收到的顺序来为它们进行授权是不可行的。为了说明 这一点,令P0代表该调度进程。假设P1发送一个请求给P0,然后又发送了一个消息给P2。一旦收到后面的这个消息,P2就会发送一个请求给P0。P2的 请求有可能在P1的请求到达P0之前就到达了。这样就违背了条件(2),因为P2的请求会首先被授权。{!根据条件(2),应该按照请求发生的顺序进行, 很明显P1的请求发生在P2请求之前,简单的按照请求被接收的顺序进行授权是很难满足这个条件的}
为 解决该问题,我们实现一个满足了规则IR1和IR2的时钟系统,同时利用它们来定义一个所有事件的全序关系“=>”。这样就为所有的资源请求和释放 事件提供了一个全序关系。利用这种顺序关系,就可以比较容易地找到一个解。它只需要确保每个进程知道所有其他进程的操作。
为 简化这个问题,首先我们需要进行一些假设。这些假设不是必需的,但是引入它们有助于避免陷入细节的讨论中。首先我们假设,对于任意的两个进程Pi和Pj, 它们之间传递的消息是按照发送顺序被接收到的。此外,我们还假设所有的消息最终都会被接收到。(这些假设可以通过引入消息序号和确认机制来消除)。同时我 们假设每个进程都可以直接向其他进程发送消息。
每个进程会维护一个它自己的对其他所有进程都不可见的请求队列。我们假设该请求队列初始时刻只有一个消息T0:P0资源请求,P0代表初始时刻获得资源授权的那个进程,T0小于任意时钟初始值。
算法是由如下5个规则定义的。方便起见,每条规则定义的行为会被做为一个独立事件。
1. 为请求该项资源,进程Pi发送一个Tm:Pi资源请求消息给其他所有进程,并将该消息放入自己的请求队列,在这里Tm代表了消息的时间戳
2. 当进程Pj收到Tm:Pi资源请求消息后,将它放到自己的请求队列中,并发送一个带时间戳的确认消息给Pi。(注:如果Pj已经发送了一个时间戳大于Tm的消息,那就可以不发送)
3. 释放该项资源时,进程Pi从自己的消息队列中删除所有的Tm:Pi资源请求,同时给其他所有进程发送一个带有时间戳的Pi资源释放消息
4. 当进程Pj收到Pi资源释放消息后,它就从自己的消息队列中删除所有的Tm:Pi资源请求
5. 当同时满足如下两个条件时,就将资源分配给进程Pi:
a) 按照“=>”关系排序后,Tm:Pi资源请求排在它的请求队列的最前面
b) i已经从所有其他进程都收到了时间戳>Tm的消息(注:如果Pi<Pj,那么Pi只需要收到一个>=Tm的消息即可)
需要注意的是,规则5中的条件a),b)都只需要由进程Pi自己在本地进行判断。
可 以很容易地验证由这些规则所定义的该算法满足上面的条件(1)(2)(3)。首先,可以看到,规则5的条件b),加上消息按序接收的假设,就可以保证Pi 已经收到了所有排在它的当前请求之前的所有请求。因为只有规则3和4会从请求队列中删除消息,因此可以很容易看出条件(1)是满足的。条件(2)可以通过 如下事实得出:“=>”是对偏序关系“->”的扩展。规则2保证了在Pi发出资源请求后,规则5的条件b)最终一定会成立。规则3和4意味着 如果获取了资源授权的所有进程最终释放掉资源后,那么规则5的条件a)最终也一定会成立,这就证明了条件(3)。
{! 重新整理下上面的证明过程,规则5的条件b)+消息按序传输的假设,可以推出Pi已经接收了在它的资源请求之前的那些请求,因为Pi已经从其他所有进程都 收到了晚于Tm的消息,对于其他进程来说,根据消息按序传输的假设,那些早于Tm的消息肯定也已经被进程Pi接收到了。然后又由于规则3,4是唯一会从请 求队列中删除消息的地方,就可以得出条件(1)成立。
我们可以这样证明条件1的成立:假设 条件(1)不成立,则意味着在资源分配给某进程后,假设该进程为Pm,还有其他进程未释放该资源,假设为Pn,那么对于这个进程来说,意味着它还未释放资 源,根据规则3,4,也就意味着它还未将该请求从自己的队列中删除,其他进程也还未将其删除。而进程Pm之所以能获取资源,说明它满足了规则5的两个条 件,但是根据条件a)说明进程Pm的资源请求是最早的,但是实际上Pn的请求要更早,因为它比Pm更早获得授权,但是该请求还未从Pm的队列中删除,因此 规则5的条件a)就不可能满足,这样就找到了矛盾的地方。
规则5的条件a),b)保证了最 先发出的资源请求必然先获得授权,由此可以推出条件(2)成立。但是还需要证明的是,这两个条件最终一定会被满足。首先规则2保证了规则5的条件b)最终 会成立,因为其他进程一定会发出一个晚于Tm的消息,而根据假设消息最终会被收到,因此条件b)最终一定会成立。规则3,4意味着如果获取资源的进程最终 释放了资源,那么规则5的条件a)最终一定会满足,因为请求是按序被分配的,如果排在前面的资源请求在授权之后会再释放,那么后面的请求就能被授权,如此 循环,最终一定会轮到Tm:Pi资源请求。由于规则5的条件a),b)最终一定会被满足,因此对于每个进程来说,它们的资源请求最终一定会被授权,因此条 件(3)就满足了。}
这是一个分布式算法。每个进程各自独立地遵从这些规则,同时没有中央 同步进程或者是中央存储。该方法可以被通用化,来实现分布式的多进程系统所需要的任意同步机制。同步过程可以通过状态机来描述,该状态机包含一个命令集合 C,一个可能的状态集合S,以及一个函数e:C×S->S。关系e(C,S)=S’的含义是,在处于状态S的状态机执行命令C,将会使状态机转移到 状态S’。在我们的例子中,C包括所有的Pi资源请求和资源释放命令,状态包括一个处于等待状态的请求命令队列,同时处于队列顶端的那个请求就是要被授权 的那个。请求命令的执行将会将该请求添加到队列末尾,释放命令的执行将会从队列中删除一个命令。
每 个进程独立地通过使用所有进程产生的命令来驱动该状态机的执行。所有的进程通过根据时间戳来对命令进行排序来达到同步(使用关系“=>”),因此所 有进程将会使用相同的命令序列。当一个进程发现它已经收到了所有时间戳小于等于T的命令之后,它就可以执行时间戳为T的命令了。具体的算法已经很明了了, 因此我们不再进行描述。
该方法使得我们可以实现分布式系统中任何形式的进程同步需求。但是,该算法需要所有进程都必须参与其中,同时进程必须要了解所有其他进程产生的命令,因此只要有一个进程出错,都会使得其他进程无法执行状态机命令,从而导致系统运行停滞。
错 误处理是一个很困难的问题,同时对它进行细节性的讨论已经超出了本篇文章的范围。只是需要指出的是,failure这个概念只有在物理时间上下文中才有意 义。如果没有物理时间,就没有办法去区分进程是出错了还是只是处于事件之间的间歇。用户只能通过系统很长时间都没有响应来判断系统出了问题。在进程或通信 线路出错时也能正常工作的方法,我们将会在[3]中进行描述。
Anomalous Behavior
我 们的资源调度算法是根据全序关系“=>”来对请求进行排序的。这就允许下面这种异常行为(Anomalous Behavior)的发生。考虑一个由相互连接的计算机组成的全国性系统。假设某人在计算机A上产生了一个请求A,然后他打电话告诉住在另一个城市里的朋 友B,让它在计算机B上产生一个请求B。对于请求B来说很有可能会获得一个更小的时间戳然后被排在A前面。这是有可能发生的,因为系统没有办法知道A实际 上发生在B之前,因为该信息是基于位于系统外部的消息的。
让我们更深入地考察下该问题产生的根源。令∮代表所有系统事件组成的集合,然后我们再引入一个包含了∮中的事件以及所有其他外部事件(比如上面例子中的打电话)的集合∮’。令->{!注意这个是加粗的->,与前面的->不同}表示∮’中的happen before关系。在上面的例子中,有A->B,但是A!->B。很明显一个完全基于∮中的事件,而对的∮’中的其他事件没有任何联系的算法,是无法保证请求A会被排在请求B前面的。
有 两种可能的方式可以避免这种异常行为。第一种方式是将关于->顺序的必要信息显式地引入到系统中。比如在上面的例子中,该用户在产生请求A时可以获 取它在系统中的时间戳T,然后他可以在打电话通知他朋友的时候,告诉他这个时间戳,然后在他朋友产生请求B的时候,告知系统产生一个晚于T的时间戳。这样 就将这种异常行为交给用户自己来负责。
第二种方法就是构造一个满足如下条件的时钟系统:
Strong Clock Condition.对于∮’中的任意两个事件,如果a->b,那么c(a)<c(b)。
该条件要比之前的Clock Condition强,因为->比->要强。通常我们的逻辑时钟无法满足该条件。
如果我们令∮’表示物理时空中真实事件的集合,令->代 表由狭义相对论所定义的事件偏序关系。在我们所在的宇宙中,是有可能构造出一个由相互之间独立运行的多个物理时钟构成的满足Strong Clock Condition的时钟系统的。因此我们可以使用物理时钟来避免这种异常行为。下面我们就将注意力转移到这类时钟之上。
Physical Clocks
现 在我们将物理时间引入到我们的时空图中,令Ci(t)表示在物理时间t所读取到的时钟Ci的值(注:我们现在假设是在一个牛顿绝对时空中。如果时钟的相对 运动或者重力效应无法忽略,那么Ci(t)必须要把实际读取的时间转换成选定的时间坐标系中的时间)。为了方便数学表述,我们假设时钟是以连续而非离散的 滴答走动的。更准确地说,我们假设Ci(t)是一个在时间t上的连续的可微分函数,除了那些时钟被重置时的孤立突变点之外。dCi(t)/dt代表了时钟 在时间t时的速率。
如果将时钟Ci作为一个真实的物理时钟,那么它还必须以一个近似正确的速率来运行。也就是说,必须要保对于所有的t,dCi(t)/dt≈1。更准确地说,我们要保证满足如下条件:
PC1.存在一个常数k,对于所有的i:| dCi(t)/dt -1|<k
对于典型的由晶体控制的时钟来说,k<=10^-6.
如果时钟只是单单地以近似正确的速率运行是不够的。它们还必须是同步的,即对于所有的i,j,t来说,Ci(t)≈Cj(t)。更准确地说,必须存在一个足够小的常数e,满足如下条件:
PC2.对于所有的i,j:| Ci(t)-Cj(t)|<e.
如果我们让图2中的垂直距离来表示物理时间的话,那么PC2意味着单个滴答线上的高度差异要小于e。
由 于两个不同的时钟永远都不会以相同的速率走动,这意味着它们之间的偏差会越来越大。因此我们必须要设计一种算法来保证PC2总是成立。但是,首先我们来看 一下k和e要多小才能避免异常行为。我们必须要保证系统∮’中的所有相关事件都满足Strong Clock Condition。首先我们假设我们的时钟满足普通的Clock Condition,那么只需要保证∮’中那些不满足a->b的事件满足Strong Clock Condition。因此我们只需要考虑发生在不同进程中的事件。
令u表示满足如下条件的 值:如果事件a发生在物理时间t,同时b是发生在另一个进程中的满足a->b事件,那么b肯定发生在物理时间t+u之后。换句话说,u需要小于进程 间消息传输的最短时间。我们可以用进程间的距离除以光速的值作为u的值。当然,这取决于∮’中消息是如何传输的,u的值也可以很大。
为 避免异常行为,我们必须保证对于任意i,j,t:Ci(t+u)-Cj(t)>0,再结合PC1和PC2,我们就可以建立起所需要的最小的k和e值 与u之间的关系。同时我们假设时钟被重置时,它的时间只会超前而绝不会后退(后退会导致条件C1被违反)。PC1意味着 Ci(t+u)-Ci(t)>(1-k)u。再结合PC2,就可以很容易地得出如果如下不等式成立,那么Ci(t+u)-Cj(t)>0就成 立:e(1-k) <= u。该不等式再加上PC1和PC2就可以保证异常行为不会发生。
现 在我们来描述下用来保证PC2成立的算法。令m表示一个在物理时间t发送和时间t’被接收的消息。我们定义Vm=t’-t来表示消息m的总延迟。当然,接 收消息m的进程并不知道该延迟。但是我们假设接收进程知道某个最小延迟取值Um>=0,并且Um<=Vm。我们称Em=Vm-Um为消息的不 可预测的延迟部分。
现在我们将规则IR1和IR2针对物理时钟修改如下:
IR1’.对于每个i,如果Pi在物理时间t未收到消息,那么Ci是在时间t就是可微分的并且dCi(t)/dt>0.
IR2’. (a)如果Pi在物理时间t发送了一个消息m,那么m将包含一个时间戳Tm=Ci(t).(b)当在时间t’接收到消息m时,进程Pj将设置Cj(t’) 等于max(Cj(t’-0),Tm+Um).(注:Cj(t’-0)=[limCj(t’-|&|),&->0])
尽 管这些规则的描述使用的都是物理时间,进程只需要知道它自己的时钟值以及它接收到的消息中的时间戳即可。为了数学描述的方便,我们假设事件均发生在一个精 确的物理时间点上,同时相同进程的不同事件发生在不同的时间。这些规则仅仅是针对规则IR1和IR2的一个特化版本,因此我们的时钟系统是满足Clock Condition的。实际上,由于真实的事件都会持续一段有限的时间,这就使得该算法实现起来没有什么困难。实现唯一需要注意的是要确保离散的时钟滴答 是足够频繁的,可以保证满足C1。
现在我们来展示一下如何用该时钟同步算法来保证条件 PC2的满足。我们假设该系统可以用一个有向图来表示,图中从进程Pi到进程Pj的边表示一个通信线路,消息可以直接通过该线路从Pi发送到Pj。同时我 们假设每τ秒就会有一条消息通过该线路,这样对于任意的时间t,在物理时间t到t+τ之间,Pi至少发送了一条消息到Pj。有向图的直径是满足如下条件的 最小值d:对于任意的两个进程Pj,Pk,都存在一条从Pj到Pk的路径,该路径最多具有d条边。
除了建立起了PC2,下面的定理还给出了系统首次启动时令时钟达到同步状态所花时间的上界{!即下面的t> t0+τd ,在此之后系统时钟就是同步好的了}。
THEOREM. 假设一个半径为d的由多个进程组成的强连通图始终满足规则IR1’和IR2’。同时对于任意消息m,Um<=某常数U,以及任意时刻t& gt;=t0来说:(a)PC1成立.(b)存在常数τ和ε,每τ秒都会有一个消息在不可预测的延迟部分小于ε的情况下在每条边上传送。那么PC2就能被 满足,同时对于所有的t>t0+τd,e≈d(2kτ+ε),这里我们假设U+ε<<τ。
该 定理的证明令人吃惊地困难,详细证明过程见附录。目前针对物理时钟的同步问题人们已经进行了大量的研究。推荐读者阅读[4]了解下这个问题。该领域提出的 很多方法,都可以用来估计消息传输Um以及调整时钟频率dCi/dt(适用于那些允许进行调整的时钟)。但是,看起来时钟不能回退的这个要求使得我们的场 景与之前被研究的那些有所不同,同时我们相信该定理是一个全新的结论。
Conclusion
可 以看到”happen before”概念定义了分布式系统中事件的一个偏序关系。我们描述了一个可以将该偏序关系扩展为某种全序关系的算法,同时展示了这种全序可以用来解决一 个简单的同步问题。我们将会在未来的一篇paper里展示如何对这种方法进行扩展以用来解决任意的同步问题。
该算法定义的全序关系有些随意。当系统与用户所观察到的事件顺序不一致时会产生异常行为。该问题可以通过使用一个被正确同步的物理时钟系统来避免。我们的定理还展示了时钟可以被同步到怎样的程度。
在分布式系统中,认识到事件的发生仅仅是一种偏序关系是非常重要的。这个观点对于理解任意的多进程系统来说都是非常有用的。它可以帮助人们理解多进程系统中的基本问题,撇开那些用于解决这些问题的各种机制。
致谢
使用时间戳来为操作排序,以及异常行为的概念要归功于Paul Johnson和Robert Thomas。
参考文献
1. Schwartz, J.T. Relativity in lllustrations. New York U. Press, New York, 1962.
2. Taylor, E.F., and Wheeler, J.A. Space-Time Physics, W.H. Freeman, San Francisco, 1966.
3. Lamport, L. The implementation of reliable distributed multiprocess systems. To appear in Computer Networks.
4. Ellingson, C, and Kulpinski, R.J. Dissemination of system-time. 1EEE Trans. Comm. Com-23, 5 (May 1973), 605-624.
译考文献
Rethinking Time in Distributed Systems: Can We Build Complex Systems Simply?
Rethinking Time in Distributed Systems视频
White Paper Introduction to IEEE 1588 & Transparent Clocks
分布式系统时钟同步技术的研究与应用