使用Tika进行非结构化内容的读写-2
前面说了一个tika的大概处理流程,现在可以通过一个它自带的parserTest来看一下具体的走向。以下这段代码,读取某一个pdf文件的内容:
File file = getResourceAsFile("/test-documents/testPDF.pdf");
String s1 = ParseUtils.getStringContent(file, tc);//方法1
直接使用ParseUtils.getStringContent来获取它里面的内容信息。直接进入到此方法:
String mime = config.getMimeRepository().getMimeType(documentFile).getName();
return getStringContent(documentFile, config, mime);//方法2
第一句话,包含几个信息,首先从config中取得所有的mimeType注册器(1),再将待解析的文件传入以取得相应的 mimeType(2),最后取得mimeType的名称(3)。
1:config参数是传递过来的,即在parserTest中进行了声明,见原文,是通过TikaConfig.getDefaultConfig()方法读取了默认的mimeConfig信息。在这个方法中,会返回一个默认的TikaConfig对象(即new TikaConfig())。进入构造函数:
ParseContext context = new ParseContext();
Iterator<Parser> iterator =
ServiceRegistry.lookupProviders(Parser.class, loader);
while (iterator.hasNext()) {
Parser parser = iterator.next();
for (MediaType type : parser.getSupportedTypes(context)) {
parsers.put(type, parser);
}
}
mimeTypes = MimeTypesFactory.create("tika-mimetypes.xml");
此代码主要做两件事情,第一个是读取在services中注册的parse的所有实现类,即读取在WETA-INF/services目录下的org.apache.tika.parser.Parser文件。此文件中以列表的方法列出了parser的实现类,即服务提供者。如下所示:
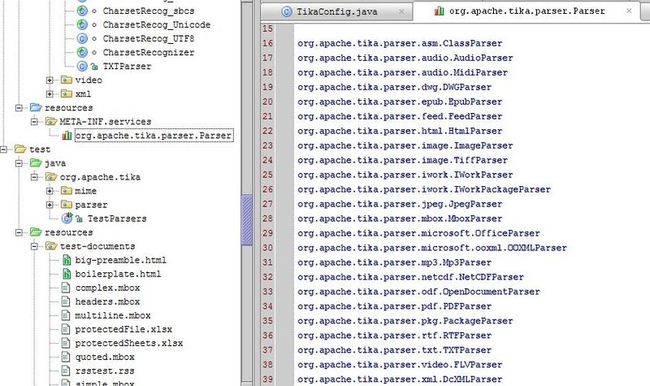
在上图中,列出了所有已经注册的Parser实现类,tika即加载这些类以用作具体的解析。
第二件事即是读取所有的mimeType信息,通过读取resource下的tika-mimeTypes.xml来解析其中每个mimeType以及对于每个mimeType中它应该拥有的信息格式,即根据一定的规则定义一个mimeType与匹配这个mimeType的规则。具体的实现可参考MimeTypesReader的readMimeType(Element element)类(此处略)。
2:第二个方法根据文件取得具体的mimeType,在这里的简单实现是根据文件的名称来取得mimeType(在实际中对于某些文件后缀名不正确的文件,应该根据文件中的数据来确定mimeType,此处简单用file.getName来进行判断)。
在做完以上工作之后,进入到下个方法:
InputStream stream = new BufferedInputStream(new FileInputStream(documentFile));
return getStringContent(stream, config, mimeType);
再进入到以下方法:
Parser parser = config.getParser(MediaType.parse(mimeType));
ContentHandler handler = new BodyContentHandler();//最初的handler
parser.parse(stream, handler, new Metadata());
return handler.toString();
这里最终会调用到具体处理各个文件的parser,这里处理pdf的类为pdfParser,进入到它的parse方法:
PDDocument pdfDocument = PDDocument.load(stream);
metadata.set(Metadata.CONTENT_TYPE, "application/pdf");
extractMetadata(pdfDocument, metadata);
PDF2XHTML.process(pdfDocument, handler, metadata);
这里通过apache的pdfbox类来加载文件流,并设置相应的contentType,接下来将读取相应的元数据并保存在metaData中。最后调用pdf2xhtml的静态方法来处理这个pdf文档。
在extractMetadata中,tika通过PDDocumentInformation类将以下信息读取到metadata中:title,author,CREATOR,KEYWORDS,producer,SUBJECT,trapped,created,CREATION_DATE,LAST_MODIFIED以及其他通过getDictionary方法中未加入的其他信息。
PDF2XHTML类通过继承PDFTextStripper类来重写相应的方法以达到读取信息的目的,它通过调用getText(document)方法,并重写相应的扩展方法将处理的信息交由handler来处理,最终实现由handler来处理最终的信息。如下个方法所示:
protected void writeString(String text) throws IOException {
handler.characters(text);
}
这里的handler即是最开始传入的bodyContentHandler,其默认不带参数的handler即this(new WriteOutContentHandler()[A]),最终将会调用到MatchingContentHandler[B]来处理,handler[B]处理完自己需要处理的信息(即过滤其中的某些信息)之后,将其他处理部分交由handler[A]来处理,如在characters中,writeOutContentHandler中的调用代码为:
writer.write(ch, start, length);
writeCount += length;
即将其写入输出流中。
最后,调用handler的toString方法,输出相应信息,即调用writer.toString()返回输出的信息。
至此,程序主要调用逻辑完成。当然,在具体处理中,还会涉及到其他处理,如startElement,endElement等事件的处理,这里未主要涉及,待下来再研究。