-
背景
如果你是一名SRE兄弟,收到告警短信,你是否还在疯狂的敲着ssh | grep | sed | awk 这些命令的组合排查问题呢?如果1台,2台,3台机器,ok;如果有n台机器,你会不会抓狂?
如果你是一名DEV兄弟,开发一套高性能的分布式数据处理平台,你是不是还在考虑数据如何传输,中间件如何配置,资源如何调度的问题,Oops ,你应该将重点放在业务逻辑的开发而不是外围框架的Integration上, 考虑的问题太多了,你会不会抓狂?
很不幸,我是名SRE,我们需要使用一套日志分析工具来帮助我们快速定位问题。
Ops makes No Ops.
-
系统设计
这是一张组件构建图
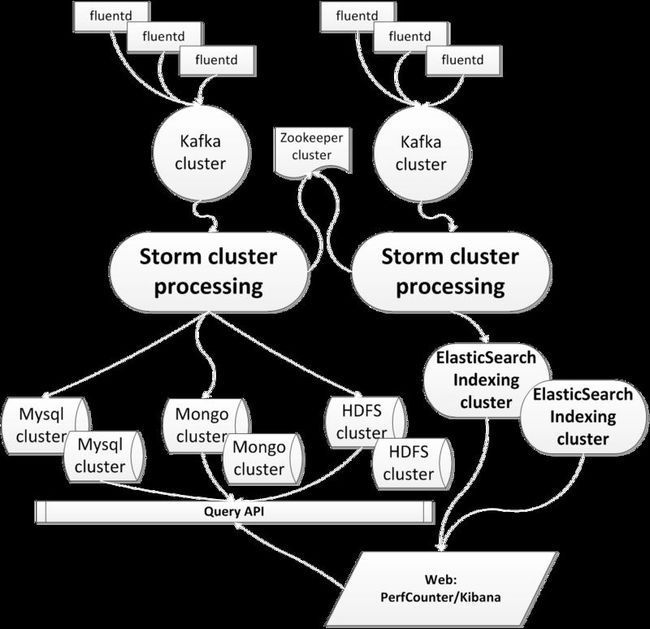
我们设想了2条数据流处理方式:
1,实时日志分析系统(Xlog):分为5层,数据采集层,数据持久化层,数据处理层,结果数据持久化层,数据展示层。
2,tracing系统:分为5层,数据采集层,数据持久化层,数据处理层,indexing层,数据检索展示层。
本文将重点介绍下“实时日志分析系统”的构建过程和一些内部实现细节,希望对读者有些帮助。
-
组件选型
作为一名SRE,Reuse Infrustracture的能力也是一种核心竞争力!
Xlog使用下列组件来构建分布式流式日志处理系统:
- Fluentd–日志采集处理Agent

- Kafka–消息持久化队列

- Storm–分布式HPC框架
![]()
http://storm.incubator.apache.org/
- Mongodb–结果缓存
{kind=link}
- Xperf–数据展示平台
Xlog组件选型简单说明
A. Agent选型
说到日志采集,无非三种模式
- 通过tail文件的方式采集滚动日志;
- 通过listen TCP/UDP端口进行收集;
- 通过request HTTP/HTTPS协议提供的URL进行采集;
说到组件选型,目前开源的收集组件
syslog/rsyslog/syslog-ng一般用于收集Linux系统日志,收集应用日志配置复杂且不利于二次开发;
scribe facebook开源的高性能日志收集组件,但是一年多无更新,bug fixing都成问题,c写的,不利于二次开发;
目前最火的三类Agent:logslash,fluentd,flume;分别用jruby,ruby,java实现,我个人觉得flume过于重了,先不考虑,logslash是 jruby实现的,二次开发不太熟悉,所以考虑fluentd
fluentd的优点:
- 结构化日志
- 支持插件的架构
- 消息可靠传输机制
通过使用,个人认为fluentd最方便的2点在于
a,配置十分便捷
配置一个souce用于日志的输入
配置一个match用于日志的输出
souce/match对的组合十分灵活,可以实现多对多,1对多,多对1的日志收集模式。
b,插件式架构,支持二次开发,满足不同组件系统的集成和私有化定制
比如我们需要开发一个non-buffered的out_plugin,只需要重写下列代码的method
你只需要在
B. 持久化组件
mongodb和kafka就不多说了,mongodb在这里主要利用其“Capped”的特性来缓存storm处理完毕的消息;kafka是目前当之无愧的最高性能分布式消息队列,我们在这里用kafka主要考虑到3点:
- 对数据源进行topic分流,实现Category;
- 作为一层buffer来适配输入输出的消息速率,解除系统耦合度;
- 考虑后期集群数据量规模和可扩展性;
C. 计算组件
Storm是twitter开源的分布式内存计算框架,目前已经作为apache的incubator项目,与之相提并论的有yahoo的S4,apache的spark,目前商用比较成熟的,Storm是其中之一,采用thrift c/s的框架,核心代码采用clojure编写,外围框架采用java编写,统一暴露java的api,同时还提供多语言的开发支持,同类产品还有一个twitter用ruby实现的storm,叫redstorm,国产的是淘宝用java实现的jstorm。
Hadoop的M/R这样的large-scale数据集处理大家并不陌生,但是,Hadoop的定位在于batch处理历史数据集,对于分钟级的实时不间断数据集处理并不擅长,所以,Storm是用来填补Hadoop的”空洞“的。
因此,还有一个开源项目,是twitter开源的summingbird,旨在综合了批处理和实时处理的2类需求。
选择Storm作为开发组件原因在于,Storm的支持下列特性:
- 提供丰富的应用case场景支持:比如流式处理,持续计算 , 分布式RPC,支持事务,数据聚合等;
- 集群易于扩展:根据数据量来控制集群规模非常容易,当计算能力不够时,只需要增加node节点动态扩容;
- 消息不丢,不重,和S4不同,Storm保证对每条消息进行处理,事务功能保证不重复处理消息,对于对精准性有要求的业务case,比如计费日志过滤,统计的需求是可以满足的;
- 高可靠:Storm中各个component通过zk进行交互,state信息都存在zk中,除了nimbus是一个SPOF外,其他组件都不是SPOF;其实nimbus也是个伪单点,只是在提交代码和UI展示时需要,对于已经提交集群running的代码不会有影响;
- 多语言支持:基于thrift的好处在于Storm允许你使用多语言进行编程,不仅仅说你是一个javaer才能搞定;
开发基于spout,bolt原语的程序就是这么简单!
比如我们想实现一个从kafka读取数据,然后在storm内存中对日志字段计算,最好push到mongodb中的这条业务功能只需要1个spout和2个bolt的组装即可
kafkaSpout对象实现了从Kafka中读取数据的功能;
accoutBolt对象实现了解析tuple数据,统计基数业务功能;
mongoInserter对象实现了对统计完毕数据push到Mongodb的功能;
上述不同对象组装成一个Topology即可完成一个streaming的功能。
今后我们不不同应用可以抽象出commons的需求算子,不同算子通过Topology组装成不同的服务完成各种业务功能,非常灵活。