时至今日,zookeeper在分布式的应用场景已经多越来越多了, 比如解决hbase的hmaster单点问题,分布式锁,分布式队列,集群机器监控等等。zookeeper提供的功能包括:配置维护、名字服务、分布式 同步、组服务等。而在引擎后台数据处理系统里怎么使用zookeeper的呢?以及在使用过程中遇到那些问题呢? 首先,介绍一下zookeeper
-
zookeeper简介
1)Why zookeeper?
2)What Is Zookeeper ?
它是ApacheHadoop的一个子项目,它主要用来解决分布式集群中应用系统的一致性问题,提供基于类似于文件系统的目录节点树方式的数据存储。除了数据存储,它还可以用来维护和监控你存储的数据的状态变化。从设计模式角度来它能看,Zookeeper是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知那些已经注册的观察者做出相应的反应。
3)What zk looks like?
上面说过,类似于文件系统, 是文件系统模型。 如图:
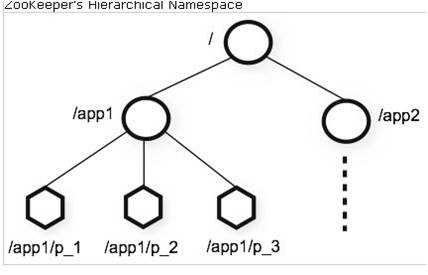
注:目录节点可以存少量数据(<1M)。
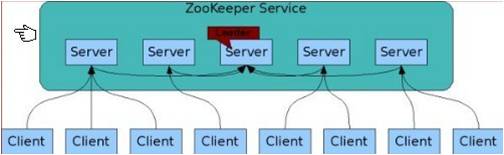
4) How ZK Work?
zookeeper如何解决工作,如何解决一致性问题的呢?zookeeper集群启动时,会选举出一个leader server, 其他server基本就是follower了。 所有的server都保存完整一份数据, 所有的server(含leader)都能对外服务。 当有写请求时,通过选举算法获得leader的同意才能生效; 当有读请求时,处理该请求的server直接获取本地数据返回给client端。
-
zookeeper在离线数据处理的使用
虽然zookeeper能解决很多分布式上的问题,离线数据处理在使用上还是遇到一些zookeeper不满足系统需求的地方:
1) zookeeper给用户提供给用户使用工具有:java/c/python的等客户端,后台命令行工具有zkCli.sh,zkServer.sh等, 还有四字命令(有ruok,stat,mntr,conf,cons等,这些命令对于运维十分重要,关于四字使用参考 http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_zkCommands) 等。 但是并没有提供web页面方便供用户查看zookeeper上的节点数据。如果每次都使用命令行工具去查看节点数据,工作效率低下。
2)当多个用户共同使用一个zookeeper集群,并且每天新增一些新的zookeeper节点和数据时,时间长了就要解决一个问题:Zookeeper上过期不用的节点和数据需要回收。
3)zookeeper上节点是不分数据节点和目录节点的。这点跟传统的linux文件系统不同。如果应用场景对节点需要分类时,应用程序自行解决。
针 对以上3点的不便, 离线处理系统对zookeeper client做了一层封装,封装后的zookeeper client叫做resource zookeeper,简称reskeeper。reskeeper分别实现了对zookeeper的 java,c,python的封装。现在拿reskeeper的java client说明reskeeper的架构。
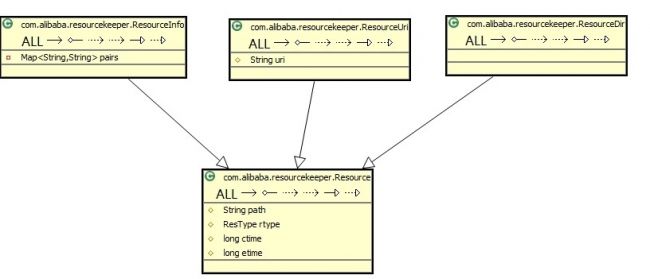
在reskeeper里,zookeeper每一个node就是一个Resource,被分为3个类型:
1)info, 用来存储重要信息的,其node可存储的data是Map结构的。
2)uri,专门用来存url的
3)dir,与linux系统的目录是一个概念。
其中Resource有个重要属性etime,表示这个node的过期时间,类似于hbase的ttl,有其他程序专门删除zookeeper上过期的node。为了方便在web上实现,这些Resource所对应data存入是json格式的。
对应的web是页面的样子为:

总体上讲,离线数据处理系统对zookeeper的应用的场景有:
1)离线数据处理系统全量和增量的协调是通过zookeeper来实现的。例如当全量的job起来时,更新zk上…/status的数据为 suspend。 增量的job是24小时开启的,但每次增量的job启动时,会去检测…/status的数据,如果发现全量job正在运行,就退出来。
2)与引擎离线build模块数据交互的工作也是通过zookeeper来协调的。比如今天的全量xml文件生成好了,会在zk生 成…/product/20130910_233949,该节点为uri类型, 值为:hdfs://namenode:9000…/product_20130910_233949
3)重要信息存入zookeeper,这类信息的特点是存储的内容比较少。例如,每天精卫任务解析数据库的binlog的时间戳会保存在zookeeper上,以供引擎作回溯用。
4)分布锁。多个mapreduce的task共用竞争锁,获得锁后可以处理某一特定的任务。
-
遇到的问题,踩过的坑
自从2011年使用zookeeper以来,线上也遇到一些问题:
一) zookeeper与hbase的region server进程共同使用一台机器。这是在刚使用zookeeper时容易发生的问题,以为zookeeper占用资源少,可以和其他程序一起运行在同一台机器上。这里我们出现过严重的问题,hbase集群的region server挂了一大片,集群基本不可用。 当hbase集群有较大压力时,RS连接zookeeper超时,认为自己是无效的RS了。 这个算是常见的问题了,看一般zookeeper使用经验,都建议独立的zk server,哪怕机器差一点。
二)关于zookeeper初始连接的问题。链接zookeeper失败,错误信息如下:
13/04/08 10:41:40 INFO zookeeper.ClientCnxn: Opening socket connection to server dump002010.cm6.tbsite.net/10.246.2.10:2181
13/04/08 10:41:41 WARN zookeeper.ClientCnxn: Session 0×0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
错误代码如下:
try {
zk = new ZooKeeper(ParseArgs.fullScanConf.hc.HbaseQuorum, 10000000, new NullWatcher());
zdata = zk.getData(ParseArgs.fullScanConf.hc.HbaseZKNode+ParseArgs.HTABLE, false, null); ……
new Zookeeper对象后就立刻使用zk对象去读取数据,这里zk对象连接server是异步的,也没有去检查zk对象的状态正常否(可以通过 getState方法获取),就立刻调用getData,报错ConnectException而退出的可能性非常大。我们的两个解决方案时是:
1)通过zk对象的getState方法,看Status是否为’CONNECTED‘,如果不是循环等待直到status变为’CONNECTED‘。
2)在new Zookeeper对象时传入参数Watcher对象,可以通过Watcher对象查看Watcher类的process函数有被正确执行过么?正常情况 下,连接zk server后Watcher的process函数会被执行一次的。
三) Out of memory问题。 现象是zk的进程都在, 就是不接受新的请求,查看log报错如下:
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.PlainSocketImpl.doConnect(PlainSocketImpl.java:333)
at java.net.PlainSocketImpl.connectToAddress(PlainSocketImpl.java:195)
当时看zk server的进程的gc情况如下 :
明显是由于zk node和data的增加,占用太多的zk server进程的内存,导致OOM。怎么解决这个问题?不可能把zk node清理一些的,这可是线上的应用,有太多的重要信息。只能增加zk server进程jvm的内存大小。 具体做法可以参照:http://blog.csdn.net/yioadgjn/article/details/8209154。 同时督促应用把不 需要的过期的zk node删除掉。
四)too open files问题。 现象是跟上面的情况差不多,log里报错是说too open files。为什么会报这个错呢?原因是客户端越来越多,socket也不够用了。用ulimit -a一看,open files为10240, 没有调到最大值65535。通过修改linux系统参数,重启zk 进程解决了 。
总之,zookeeper相对hadoop和hbase来说,是更稳定的系统。zookeeper代码比较简洁易懂,适合对分布式感兴趣的初学者研读。
参考文献:
http://zookeeper.apache.org/doc/trunk/
https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
转自淘宝:http://www.searchtb.com/2014/03/zookeeper-in-offline-computing.html