hadoop的基础知识我就不在这里介绍了,任何有关hadoop书籍中都有非常详细的原理以及其开源框架(HDFS、Mapreduce、combiner、Partitioner等)、子项目(Hive、Hbase等)的介绍以及讲解,而这些方面的知识也不是在短期内能够了解和深入的,有一个循序渐进的过程,我这里只是针对其集群结合介绍其原理介绍,让大家更快速的对hadoop有一个了解,但也请大家意识到,会搭建集群并不代表掌握了hadoop,集群的搭建之后,会涉及到集群的深度优化、多集群、性能调优等,除了hadoop集群之外还要深入的了解他的子项目以及框架才能更好的利用Hadoop来达到最佳效果
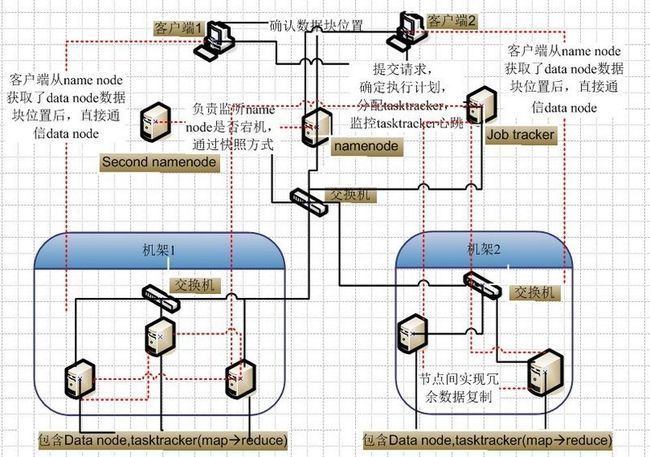
集群网络图
文件写入:
1. Client向NameNode发起文件写入的请求。
2. NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
3. Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取:
1. Client向NameNode发起文件读取的请求。
2. NameNode返回文件存储的DataNode的信息。
3. Client读取文件信息。
文件Block复制:
1. NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。
2. 通知DataNode相互复制Block。
3. DataNode开始直接相互复制。
图:
Hadoop集群流程
流程如下:
1. 分布式环境中客户端创建任务并提交。
2. InputFormat做Map前的预处理,主要负责以下工作:
a) 验证输入的格式是否符合JobConfig的输入定义,这个在实现Map和构建Conf的时候就会知道,不定义可以是Writable的任意子类。
b) 将input的文件split为逻辑上的输入InputSplit,其实这就是在上面提到的在分布式文件系统中blocksize是有大小限制的,因此大文件会被划分为多个block。
c) 通过RecordReader来再次处理inputsplit为一组records,输出给Map。(inputsplit只是逻辑切分的第一步,但是如何根据文件中的信息来切分还需要 RecordReader来实现,例如最简单的默认方式就是回车换行的切分)
3. RecordReader处理后的结果作为Map的输入,Map执行定义的Map逻辑,输出处理后的key,value对到临时中间文件。
4. Combiner可选择配置,主要作用是在每一个Map执行完分析以后,在本地优先作Reduce的工作,减少在Reduce过程中的数据传输量。
5. Partitioner可选择配置,主要作用是在多个Reduce的情况下,指定Map的结果由某一个Reduce处理,每一个Reduce都会有单独的输出文件。
6. Reduce执行具体的业务逻辑,并且将处理结果输出给OutputFormat。
7. OutputFormat的职责是,验证输出目录是否已经存在,同时验证输出结果类型是否如Config中配置,最后输出Reduce汇总后的结果。
Hadoop相关配置
下载hadoop后(我使用的是1.1.2版本),jdk(这里我就不讲解jdk的配置了)
配置环境变量(在/home/hadoop/.bashrc 中追加, 每台机器都需要配置)
export JAVA_HOME=/usr/java/jdk1.6.0_23
export PATH=/usr/java/hadoopcluster1.1.2/hadoop-1.1.2/bin:$JAVA_HOME/bin:$PATH
在hadoop-1.1.2/conf/hadoop-evn.sh中追加
export JAVA_HOME=/usr/java/jdk1.6.0_23
export HADOOP_LOG_DIR=/tmp/log
重新登录使其生效: ssh localhost
查看配置结果:which hadoop
配置HADOOP运行参数
vi conf/masters
把localhost替换为:oraclerac1
vi conf/slaves
删除localhost,加入两行:
oraclerac1
oraclerac2
下述3个文件的配置远远不只这些,配置的属性非常多,我们这里的配置只是一个基础
vi conf/core-site.xml
<property> <name>fs.default.name</name> <value>hdfs://oraclerac1:9000</value> </property>
vi conf/hdfs-site.xml
标准的副本是3,在写入一个块时默认放置策略是:如果执行写操作的客户端是hadoop集群的一部分,第一个副本应放在客户端所在DataNode中,第二个副本随机放置在与第一个副本不同的机架上,第三个副本放在与第二个副本相同机架上的不同节点上
<property> <name>dfs.name.dir</name> <value>/home/hadoop/dfs/filesystem/name</value> </property> <property> <name>dfs.data.dir</name> <value>/home/hadoop/dfs/filesystem/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property>
vi conf/mapred-site.xml
<property> <name>mapred.job.tracker</name> <value>oraclerac1:9001</value> </property> <property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>4</value> </property> <property> <name>mapred.tasktracker.reduce.tasks.maximum</name> <value>4</value> </property> <property> <name>mapred.system.dir</name> <value>/home/hadoop/mapreduce/system</value> </property> <property> <name>mapred.local.dir</name> <value>/home/hadoop/mapreduce/local</value> </property>
复制HADOOP文件到其他节点
scp -r /usr/java/hadoopcluster1.1.2/hadoop1.1.2 hadoop@oraclerac2: /usr/java/hadoopcluster1.1.2/hadoop-1.1.2
格式格式化HDFS
hadoop namenode –format
每次namenode format会重新创建一个namenodeId,而dfs.data.dir参数配置的目录中包含的是上次format创建的id,和dfs.name.dir参数配置的目录中的id不一致。namenode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空所有节点的dfs.data.dir参数配置的目录,如果还无法正常启动,删除掉所有节点的/tmp目录下内容,在针对各个进程日志进行排错
启动(因为配置了ssh ,只需要在oraclerac1机器上启动,看看启动了哪些机器的哪些进程,是否和当初自己所想一致)
start-all.sh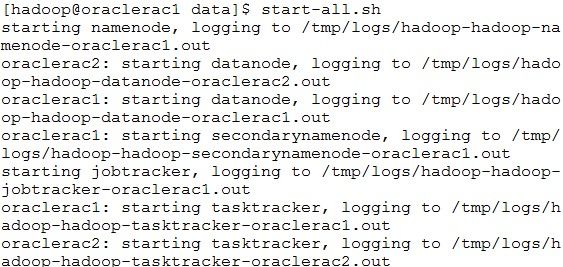
查看集群各机器进程是否正常启动,通过jdk的jps(如此处相关进程没有正确启动,需要查看hadoop集群中各个节点的相关进程日志进行排错至正常启动)
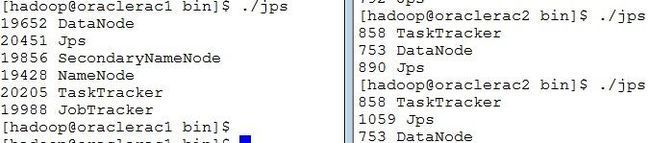
执行hadoop自带例子
创建一个文件yale.txt,存放在hadoop目录下,添加一些内容
执行:hadoop fs -put yale.txt input/yale.txt
查看:hadoop fs -cat input/yale.txt
执行:hadoop jar hadoop-examples -1.1.2.jar wordcount input output
执行完成后,我们可以通过hadoop fs –ls 查看生成了什么
具体查看:
hadoop fs –ls output
hadoop fs -cat output/p*
小提醒:当需要删除input、output上面的内容时,可以通过hadoop fs –rmr的方式进行删除,如还需了解更多参数命令,可以直接hadoop一下,进行查看
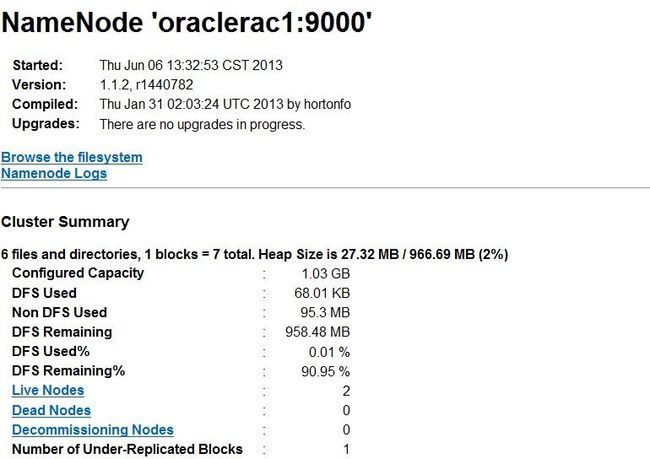
查看WEB管理界面
访问主节点IP+50030端口:http://192.168.2.11:50030/:可以查看 JobTracker 的运行状态
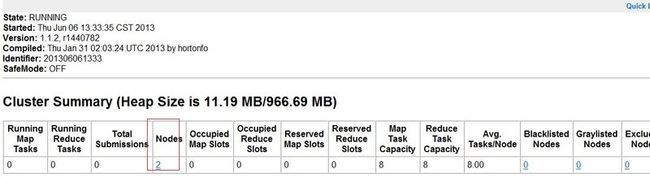
访问主节点IP+50060端口:http://192.168.2.11:50060可以查看 TaskTracker 的运行状态
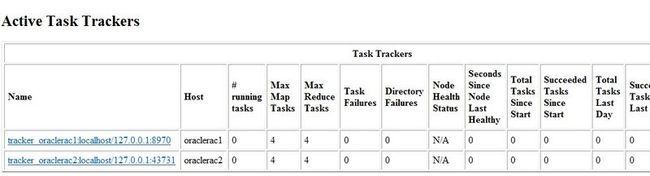
访问主节点IP+50070端口:http://192.168.2.11:50070,可以查看 NameNode 以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及 log 等,在这里我们可以通过Browse the filesystem进行刚才input、output的查看