经过前面的集群实施,已经将Nginx+Tomcat的集群环境给配置起来了,接着继续进行集群的故障转移实验.
这里的故障转移包括节点关闭情况和节点宕机情况的故障转移.
首先对于节点关闭或加入的情况,比如某一Tomcat节点关闭或重启的情况,在这种情况下,nginx可以快速识别到已停用或新加入的节点,基本上可以做到无延时的故障转移.所以这里主要实验的是tomcat宕机的情况,比如tomcat运行过程中出现内存溢出或长时间不响应的情况.
为了实验的需要,在tomcat7080的启动参数中增加内存的配置,设置其最大可用内存为64m:
JAVA_OPTS="-Xms32m -Xmx64m"
并在tomcat7080中,使用一段程序不断地往内存中写入数据,以使它出现内存溢出错误,不再处理新的访问请求.
<body>
<%!
static HashMap<String,String> map = new HashMap<String,String>();
public String generateStr(){
StringBuilder s = new StringBuilder();
while(s.length()<50){
s.append(new Random().nextInt());
}
return s.toString();
}
%>
<%
int c = 500000;
try {
c=Integer.parseInt(request.getParameter("c"));
} catch(Exception e){
c = 500000;
}
for(int i = 0; i < c ;i++){
map.put(String.valueOf(1000000+i),generateStr());
}
%>
</body>
在tomcat7080启动之后,访问这段程序所在的jsp文件,tomcat很快便出现内存溢出错误,成功宕机.
此时通过程序来模拟一个单并发,每秒发出一次请求的客户端:
public static void main(String[] args) {
for (int i = 0; i < 90; i++) {//测试90次
try {
doGet();
Thread.sleep(1000);
} catch (Exception e) {
// e.printStackTrace();
}
}
}
public static void doGet() throws Exception {
URL url = new URL("http://localhost/");
HttpURLConnection conn;
BufferedReader reader = null;
conn = (HttpURLConnection) url.openConnection();
String s;
int rc = conn.getResponseCode();
if (rc != 200) {
System.out.println("WARN: response code:" + rc);
}
reader = new BufferedReader(new InputStreamReader(
conn.getInputStream(), "UTF-8"), 512);
String line;
while ((line = reader.readLine()) != null) {
}
if (reader != null)
reader.close();
}
日志文件中的输出结果为:
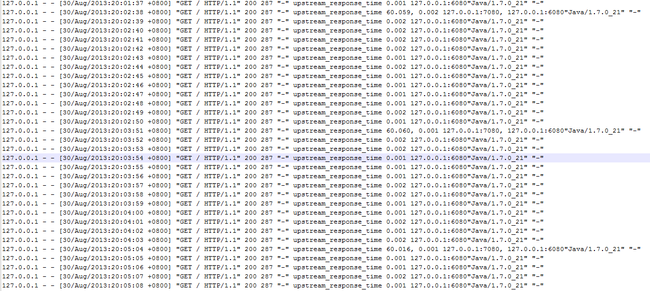
从日志输出中可以看到,nginx仍然会尝试去请求已经宕机的7080端口,但在等待60秒之后将请求转发给了6080,然后在大约13秒左右的时间内都只会请求6080端口,然后再去尝试请求7080端口,依次循环.
要解释出现这个现象的原因,需要来看一下集群中server的参数以及proxy_connect_timeout, proxy_read_timeout等参数的设置
在nginx中,upstream中的server语法如下:
(参考http://nginx.org/en/docs/http/ngx_http_upstream_module.html)
server address [weight=number] [max_fails=number] [fail_timeout=time] [slow_start=time] [backup] [down];
其中max_fails和fail_timeout的默认值分别为1和10s,这两个参数配置起来使用.含义是:在fail_timeout的时间内,nignx与upstream中某个server的连接尝试失败了max_fails次,则nginx会认为该server已经失效。在接下来的 fail_timeout时间内,nginx不再将请求分发给失效的server。所以在默认的情况下,nginx在前一次尝试连接7080端口失败后,在10秒之后才会再次去尝试(这里的实际是大约是13秒,考虑请求转发的原因,基本上可以认为是一个正常值).
然后是location中的proxy_connect_timeout和proxy_read_timeout设置.这两个参数的含义如下:
proxy_connect_timeout
后端服务器连接的超时时间_发起握手等候响应超时时间(默认为60s,不建议超过75s)
proxy_read_timeout
连接成功后_等候后端服务器响应时间_其实已经进入后端的排队之中等候处理(也可以说是后端服务器处理请求的时间)(默认为60s)
分析我们前面的实验,tomcat7080在内存溢出的情况下,仍然能够与nginx完成握手,但是却不能处理结果,所以等待的一分钟时间是耗费在proxy_read_timeout了.如果能设置一个合适的值,就可以在可接受的时间范围内,完成集群的故障迁移.
在测试过程中,最终的故障迁移时间配置如下:
upstream cluster {
server localhost:6080 weight=10 fail_timeout=1m;
server localhost:7080 weight=10 fail_timeout=1m;
}
location / {
proxy_pass http://cluster;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 2s;
proxy_read_timeout 5s;
proxy_send_timeout 5s;
}
即可承受的请求响应时间为5s,在故障被检测到之后,1m内不再向故障节点发起新请求.(实际生产环境中可按需要适当进行调整)