EOS5 之 内存溢出问题的解决
不知道普元的EOS属于哪个分类,直接放在综合类里面了。
有个项目,使用EOS5.x开发的,部署在互联网上,每年都会周期性的接受大批量人访问。
今年只是做了一些不大的调整,结果往年没有出错的应用,今年过不了多久就会报内存溢出错误。
严重的时候,几分钟就要重启一下应用服务器,否则大家都没法访问。
刚开始的时候,认为改动的部分是引起错误的主因。查看EOS的日志,观察其可用内存大幅下降
的地方,有很多业务逻辑都在这个时候调用,并没有发现很有价值的内容。但是其中一个有大量的
文档生成并提供下载的地方,引起了我们的注意,认为可能是这些文档一直在内存当中,只有等用
户下载完之后才会释放。后来将这部分代码改成生成临时文件提供下载,问题依然没有得到解决。
于是还是决定冷静下来,使用 EOS5 提供的性能分析工具,将 userAccessMonitor.log 下载下来,
使用分析工具,查看最近一次刚内存溢出期间的状况,首先看一下内存变化情况:

在 17:23之前,一直很平稳,系统分配的内存一直是512M,可用内存也没有
明显变化。但是在17:24左右,突然开始有个占用内存陡升的过程,然后在 17:34,
终于由于内存溢出无法工作而被重启了。
从这个过程可以看出,应该是某一个请求,导致内存的持续增长,直至没有可用内存
可供分配,那么这个请求动作,一定是未完成的动作。因此,通过未执行完的请求,可以看出如下
这两个动作:
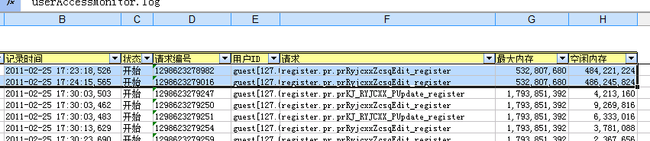
这两个请求发生时,可用内存还有480多M,属于正常范围。这两个请求发生之后,其他的未完成请求,都属于
由于强行中断应用服务器导致的,可以忽略。因此,重点就放在这两个请求上。
查看代码后发现,这两个请求,都会去查询数据库的某一张表。通常这个查询都是带查询条件和范围限制的,
但是在某个非常特定的情况下,会导致查询条件和范围都没有传递进去,因此程序会试图将整个数据库装载
进内存,从而导致内存溢出。
找到问题原因,再解决就非常容易,找到相应的代码,如果没有传入条件和范围就抛错,done.