TokenStream抽象类
TokenStream主要包含以下几个方法:
boolean incrementToken()用于得到下一个Token。
public void reset() 使得此TokenStrean可以重新开始返回各个分词。
和原来的TokenStream返回一个Token对象不同,Lucene 3.0的TokenStream已经不返回Token对象了,那么如何保存下一个Token的信息呢。
在Lucene 3.0中,TokenStream是继承于AttributeSource,其包含Map,保存从class到对象的映射,从而可以保存不同类型的对象的值。
在TokenStream中,经常用到的对象是TermAttributeImpl,用来保存Token字符串;PositionIncrementAttributeImpl用来保存位置信息;OffsetAttributeImpl用来保存偏移量信息。
所以当生成TokenStream的时候,往往调用AttributeImpl tokenAtt = (AttributeImpl) addAttribute(TermAttribute.class)将TermAttributeImpl添加到Map中,并保存一个成员变量。
在incrementToken()中,将下一个Token的信息写入当前的tokenAtt,然后使用TermAttributeImpl.term()得到Token的字符串。
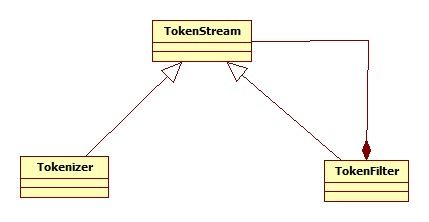
TokenStream有两个不同的子类:Tokenizer 和 TokenFilter。
Tokenizer : 用于处理单个字符(原始数据流),将Reader对象中的数据切分成语汇单元。
TokenFilter : 用于处理单词,允许多个TokenStream对象连在一起,这个强大机制使其成为名副其实的流过滤器。一个TokenStream对象传递到TokenFilter中,并在传递过程中,由于过滤器对其进行添加、删除、或更改操作等。
分词功能
将文档分成一个一个单词,去除标点符号,去除停止词(一些修饰词,例如and ,to,for等等),去除过滤词,经过分词处理后即得到token。
lucene自带的分词机制
StopAnalyzer分词:利用空格和各种符号进行单词切分,同时会去除停止词。停止词包括 is,are,in,on,the等无实际意义的词。
StandardAnalyzer分词:混合切分,包括去除停止词,并且可以支持中文,对于中文支持的效果很差。
WhitespaceAnalyzer分词:利用空格进行单词切分。
SimpleAnalyzer分词:利用空格以及各种符号进行单词切分。
KeyWordAnalyzer分词:主要用于处理类似身份证,邮编,产品编码,订单编码等关键信息。
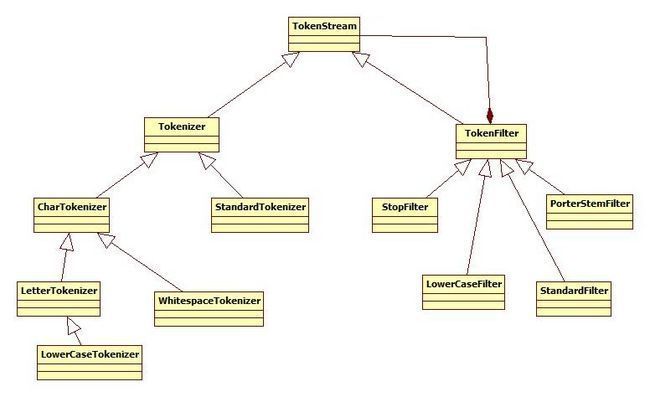
StopAnalyzer,StandardAnalyze,WhitespaceAnalyzer,SimpleAnalyzer,KeyWordAnalyzer都继承自父类Analyzer。
因此只要实现父类的虚方法tokenStream 就可以实现分析。
分词的切分算法由继承自父类Tokenizer的方法
public final boolean incrementToken() throws IOException 来实现。
因此自定义继承类Tokenizer并实现其incrementToken算法就可以实现自定义的分词。