用hadoop估算圆周率PI(3.1415926)的值
一、hadoop不适合计算密集型的工作
以前看过一个PPT: Hadoop In 45 Minutes or Less ,记得上面说hadoop不适合计算密集型的工作,比如计算PI后100000位小数。
但是,前几天,我却发现了在hadoop自带的examples里,竟然有PiEstimator这个例子!!它是怎么做到的??
二、通过扔飞镖也能得出PI的值?
百度一下,计算PI的方法还真不少。但在hadoop examples代码中的注释写的是:是采用 Quasi-Monte Carlo 算法来估算PI的值。
维基百科中对 Quasi-Monte Carlo的描述比较理论,好多难懂的公式。
好在google了一把,找到了斯坦福大学网站上的一篇文章: 《通过扔飞镖也能得出PI的值?》,文章很短,图文并茂,而且很好理解。
我这里将那篇文章的重要部分截了个图:
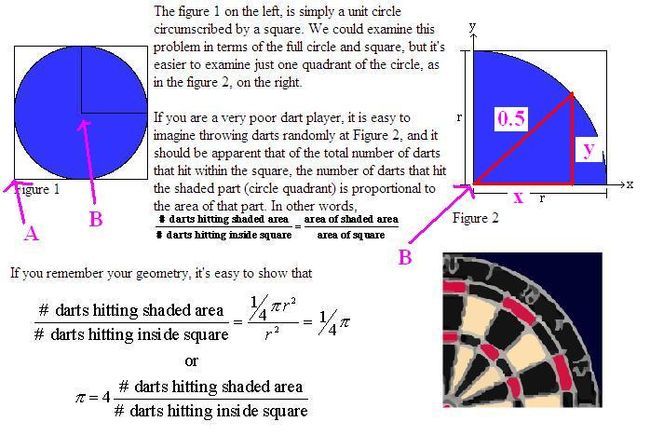
对上面的图再稍微解释一下:
1、Figure2是Figure1的右上角的部分。
2、向Figure2中投掷飞镖若干次(一个很大的数目),并且每次都仍在不同的点上。
3、如果投掷的次数非常多,Figure2将被刺得“千疮百孔”。
4、这时,“投掷在圆里的次数”除以“总投掷次数”,再乘以4,就是PI的值!(具体的推导过程参见原文)
这样也能算出PI的值?相当强悍吧,呵呵。
在这个算法中,很重要的一点是:如何做到“随机地向Figure2投掷”,就是说如何做到Figure2上的每个点被投中的概率相等。
hadoop examples代码中,使用了Halton sequence保证这一点,关于Halton sequence,大家可以参考 维基百科。
我这里再总结一下Halton sequence的作用:
在1乘1的正方形中,产生不重复,并且均匀的点。每个点的横坐标和纵坐标的值都在0和1之间。
正是这样,保证了能够做到“随机地向Figure2投掷”。
三、一定要用hadoop吗?
在《通过扔飞镖也能得出PI的值?》一文中,网页中自带了一个Flash,用ActionScript来计算PI的值。
用这种算法来估算PI值,其实是一个统计学的方法。如果要估算正确,首先要保证取样足够多(即投掷次数足够多)。但是如果是单机上运行程序,取太多的样,很容易crash your computer.
所以,这里用hadoop的原因可以在集群上并行运行多个map任务,同时集群上的节点又非常多,这样就能够保证取到足够多的样了!
四、hadoop examples代码解读
上代码:
还需要说明的是:
1、mapper的输出:
2、reducer,简单的对numInside进行sum操作。
3、最后,PI的值等于:
总共投掷的次数 = mapper的数目*每个mapper投掷的次数
PI = 4 * 投中的次数 / 总共投掷的次数
五、小结
hadoop(mapreduce)确实不适合做计算密集型的工作,尤其是下一步计算依赖于上一步的计算结果的时候。
但是hadoop的examples中的计算PI的方法并不属于这一类,而是采用大量采样的统计学方法,还是属于数据密集型的工作。
回到本文开头提到的PPT中,里面写的是“hadoop不适合计算PI小数点后1000000位小数”,而hadoop的example只是“估算PI的值”,二者并不是同一项任务。
附:运行hadoop估算PI的命令
后面2个数字参数的含义:
第1个100指的是要运行100次map任务
第2个数字指的是每个map任务,要投掷多少次
2个参数的乘积就是总的投掷次数。
我运行的结果:
Job Finished in 7492.442 seconds
Estimated value of Pi is 3.14159266720000000000
*** THE END ***
以前看过一个PPT: Hadoop In 45 Minutes or Less ,记得上面说hadoop不适合计算密集型的工作,比如计算PI后100000位小数。
但是,前几天,我却发现了在hadoop自带的examples里,竟然有PiEstimator这个例子!!它是怎么做到的??
二、通过扔飞镖也能得出PI的值?
百度一下,计算PI的方法还真不少。但在hadoop examples代码中的注释写的是:是采用 Quasi-Monte Carlo 算法来估算PI的值。
维基百科中对 Quasi-Monte Carlo的描述比较理论,好多难懂的公式。
好在google了一把,找到了斯坦福大学网站上的一篇文章: 《通过扔飞镖也能得出PI的值?》,文章很短,图文并茂,而且很好理解。
我这里将那篇文章的重要部分截了个图:
对上面的图再稍微解释一下:
1、Figure2是Figure1的右上角的部分。
2、向Figure2中投掷飞镖若干次(一个很大的数目),并且每次都仍在不同的点上。
3、如果投掷的次数非常多,Figure2将被刺得“千疮百孔”。
4、这时,“投掷在圆里的次数”除以“总投掷次数”,再乘以4,就是PI的值!(具体的推导过程参见原文)
这样也能算出PI的值?相当强悍吧,呵呵。
在这个算法中,很重要的一点是:如何做到“随机地向Figure2投掷”,就是说如何做到Figure2上的每个点被投中的概率相等。
hadoop examples代码中,使用了Halton sequence保证这一点,关于Halton sequence,大家可以参考 维基百科。
我这里再总结一下Halton sequence的作用:
在1乘1的正方形中,产生不重复,并且均匀的点。每个点的横坐标和纵坐标的值都在0和1之间。
正是这样,保证了能够做到“随机地向Figure2投掷”。
三、一定要用hadoop吗?
在《通过扔飞镖也能得出PI的值?》一文中,网页中自带了一个Flash,用ActionScript来计算PI的值。
用这种算法来估算PI值,其实是一个统计学的方法。如果要估算正确,首先要保证取样足够多(即投掷次数足够多)。但是如果是单机上运行程序,取太多的样,很容易crash your computer.
所以,这里用hadoop的原因可以在集群上并行运行多个map任务,同时集群上的节点又非常多,这样就能够保证取到足够多的样了!
四、hadoop examples代码解读
上代码:
public void map(LongWritable offset,
LongWritable size,
OutputCollector<BooleanWritable, LongWritable> out,
Reporter reporter) throws IOException {
final HaltonSequence haltonsequence = new HaltonSequence(offset.get());
long numInside = 0L;
long numOutside = 0L;
for(long i = 0; i < size.get(); ) {
//generate points in a unit square
final double[] point = haltonsequence.nextPoint();
// 1、point就是取样点,即飞镖投中的部位。这是一个x和y都是0到1的值(Halton sequence保证这一点)。此时的坐标原点在A(见Figure1)。
//count points inside/outside of the inscribed circle of the square
final double x = point[0] - 0.5;
final double y = point[1] - 0.5;
// 2、横纵坐标各减去0.5以后,我们就可以理解成:将坐标原点从A移到了B(见Figure1)。
if (x*x + y*y > 0.25) { // 3、根据勾股定理:x*x+y*y > 0.5*0.5(见Figure2),判断这个point是否在圆里。
numOutside++;
} else {
numInside++;
}
//report status
i++;
if (i % 1000 == 0) {
reporter.setStatus("Generated " + i + " samples.");
}
}
//output map results
out.collect(new BooleanWritable(true), new LongWritable(numInside));
out.collect(new BooleanWritable(false), new LongWritable(numOutside));
}
还需要说明的是:
1、mapper的输出:
//output map results
out.collect(new BooleanWritable(true), new LongWritable(numInside)); // 投中的次数
out.collect(new BooleanWritable(false), new LongWritable(numOutside));
2、reducer,简单的对numInside进行sum操作。
3、最后,PI的值等于:
//compute estimated value
return BigDecimal.valueOf(4) // 上面图中公式中的4
.setScale(20) //精度
.multiply(BigDecimal.valueOf(numInside.get())) // 投中的次数
.divide(BigDecimal.valueOf(numMaps)) // mapper的数量
.divide(BigDecimal.valueOf(numPoints)); // 每个mapper投掷多少次
总共投掷的次数 = mapper的数目*每个mapper投掷的次数
PI = 4 * 投中的次数 / 总共投掷的次数
五、小结
hadoop(mapreduce)确实不适合做计算密集型的工作,尤其是下一步计算依赖于上一步的计算结果的时候。
但是hadoop的examples中的计算PI的方法并不属于这一类,而是采用大量采样的统计学方法,还是属于数据密集型的工作。
回到本文开头提到的PPT中,里面写的是“hadoop不适合计算PI小数点后1000000位小数”,而hadoop的example只是“估算PI的值”,二者并不是同一项任务。
附:运行hadoop估算PI的命令
hadoop jar $HADOOP_HOME/hadoop-*-examples.jar pi 100 100000000
后面2个数字参数的含义:
第1个100指的是要运行100次map任务
第2个数字指的是每个map任务,要投掷多少次
2个参数的乘积就是总的投掷次数。
我运行的结果:
Job Finished in 7492.442 seconds
Estimated value of Pi is 3.14159266720000000000
*** THE END ***