如何将Lucene索引写入Hadoop2.x?
转载请务必注明,原创地址,谢谢配合!
http://qindongliang1922.iteye.com/blog/2090121
散仙,在上篇文章,已经写了如何将Lucene索引写入Hadoop1.x的HDFS系统,本篇散仙将介绍上将索引写在Hadoop2.x的HDFS上,写入2.x的Hadoop相对1.x的Hadoop来说要简单的说了,因为默认solr(4.4之后的版本)里面自带的HDFSDirectory就是支持2.x的而不支持1.x的,使用2.x的Hadoop平台,可以直接把solr的corejar包拷贝到工程里面,即可使用建索引,散仙,是在eclipse上使用eclipse插件来运行hadoop程序,具体要用到的jar包,除了需要用到hadoop2.2的所有jar包外,还需增加lucene和solr的部分jar包,截图如下,散仙本次使用的是Lucene4.8.1的版本:
具体的代码如下:
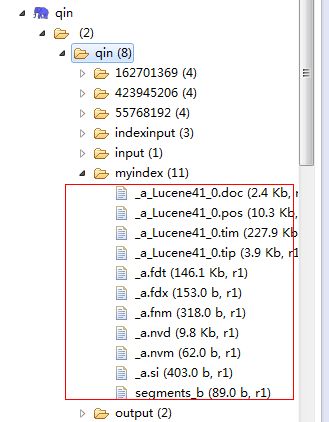
使用IK的分词器,建立索引完毕后,在HDFS上的索引如下截图:
检索数据时,第一次检索往往比较慢,第一次之后因为有了Block Cache,所以第二次,检索的速度非常快,当然这也跟你机器的配置有关系:
为什么要使用Hadoop建索引? 使用Hadoop建索引可以利用MapReduce分布式计算能力从而大大提升建索引的速度,这一点优势很明显,但美中不足的是在Hadoop上做检索,性能却不怎么好,虽然有了块缓存,但是如果索引被按64M的块被切分到不同的节点上,那么检索的时候,就需要跨机器从各个块上扫描,拉取命中数据,这一点是很耗时的,目前,据散仙所知,还没有比较好的部署在Hadoop上的分布式检索方案,但毫无疑问的是建索引的能力,确实很给力,后面散仙会写如何使用MapReduce来并行构建Lucene索引,其实既然单机版的都可以完成,那么稍微改造下变成MapReduce作业,也很简单,大家可以先尝试尝试,有什么问题,欢迎与散仙沟通和交流!
转载请务必注明,原创地址,谢谢配合!
http://qindongliang1922.iteye.com/blog/2090121
http://qindongliang1922.iteye.com/blog/2090121
散仙,在上篇文章,已经写了如何将Lucene索引写入Hadoop1.x的HDFS系统,本篇散仙将介绍上将索引写在Hadoop2.x的HDFS上,写入2.x的Hadoop相对1.x的Hadoop来说要简单的说了,因为默认solr(4.4之后的版本)里面自带的HDFSDirectory就是支持2.x的而不支持1.x的,使用2.x的Hadoop平台,可以直接把solr的corejar包拷贝到工程里面,即可使用建索引,散仙,是在eclipse上使用eclipse插件来运行hadoop程序,具体要用到的jar包,除了需要用到hadoop2.2的所有jar包外,还需增加lucene和solr的部分jar包,截图如下,散仙本次使用的是Lucene4.8.1的版本:
具体的代码如下:
package com.mapreduceindex;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.util.Version;
import org.apache.solr.store.hdfs.HdfsDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
*
* 将索引存储在Hadoop2.2的HDFS上
*
* @author qindongliang
* QQ技术交流群:
* 1号群: 324714439 如果满员了请加2号群
* 2号群: 206247899
*
*
* **/
public class MyIndex {
public static void createFile()throws Exception{
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path p =new Path("hdfs://192.168.46.32:9000/root/abc.txt");
fs.createNewFile(p);
//fs.create(p);
fs.close();//释放资源
System.out.println("创建文件成功.....");
}
public static void main(String[] args)throws Exception {
//createFile();
//long a=System.currentTimeMillis();
// add();
// long b=System.currentTimeMillis();
// System.out.println("耗时: "+(b-a)+"毫秒");
query("8");
//delete("3");//删除指定ID的数据
}
/***
* 得到HDFS的writer
*
* **/
public static IndexWriter getIndexWriter() throws Exception{
Analyzer analyzer=new IKAnalyzer(true);
IndexWriterConfig config=new IndexWriterConfig(Version.LUCENE_48, analyzer);
Configuration conf=new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.46.32:9000/");
//conf.set("mapreduce.framework.name", "yarn");
//conf.set("yarn.resourcemanager.address", "192.168.46.32:8032");
//Path p1 =new Path("hdfs://10.2.143.5:9090/root/myfile/my.txt");
//Path path=new Path("hdfs://10.2.143.5:9090/root/myfile");
Path path=new Path("hdfs://192.168.46.32:9000/qin/myindex");
//HdfsDirectory directory=new HdfsDirectory(path, conf);
HdfsDirectory directory=new HdfsDirectory(path, conf);
IndexWriter writer=new IndexWriter(directory, config);
return writer;
}
public static void add()throws Exception{
IndexWriter writer=getIndexWriter();
// Document doc=new Document();
// doc.add(new StringField("id", "3", Store.YES));
// doc.add(new StringField("name", "lucene是一款非常优秀的全文检索框架", Store.YES));
// doc.add(new TextField("content", "我们的工资都不高", Store.YES));
// Document doc2=new Document();
// doc2.add(new StringField("id", "4", Store.YES));
// doc2.add(new StringField("name", "今天天气不错呀", Store.YES));
// doc2.add(new TextField("content", "钱存储在银行靠谱吗", Store.YES));
//
// Document doc3=new Document();
// doc3.add(new StringField("id", "5", Store.YES));
// doc3.add(new StringField("name", "没有根的野草,飘忽的命途!", Store.YES));
// doc3.add(new TextField("content", "你工资多少呀!", Store.YES));
// writer.addDocument(doc);
// writer.addDocument(doc2);
// writer.addDocument(doc3);
for(int i=6;i<10000;i++){
Document doc=new Document();
doc.add(new StringField("id", i+"", Store.YES));
doc.add(new StringField("name", "lucene是一款非常优秀的全文检索框架"+i, Store.YES));
doc.add(new TextField("content", "今天发工资了吗"+i, Store.YES));
writer.addDocument(doc);
if(i%1000==0){
writer.commit();
}
}
//writer.forceMerge(1);
writer.commit();
System.out.println("索引3条数据添加成功!");
writer.close();
}
/***
* 添加索引
*
* **/
public static void add(Document d)throws Exception{
IndexWriter writer=getIndexWriter();
writer.addDocument(d);
writer.forceMerge(1);
writer.commit();
System.out.println("索引10000条数据添加成功!");
writer.close();
}
/**
* 根据指定ID
* 删除HDFS上的一些数据
*
*
* **/
public static void delete(String id)throws Exception{
IndexWriter writer=getIndexWriter();
writer.deleteDocuments(new Term("id", id));//删除指定ID的数据
writer.forceMerge(1);//清除已经删除的索引空间
writer.commit();//提交变化
System.out.println("id为"+id+"的数据已经删除成功.........");
}
public static void query(String queryTerm)throws Exception{
System.out.println("本次检索内容: "+queryTerm);
Configuration conf=new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.46.32:9000/");
//Path p1 =new Path("hdfs://10.2.143.5:9090/root/myfile/my.txt");
// Path path=new Path("hdfs://192.168.75.130:9000/root/index");
Path path=new Path("hdfs://192.168.46.32:9000/qin/myindex");
Directory directory=new HdfsDirectory(path, conf);
IndexReader reader=DirectoryReader.open(directory);
System.out.println("总数据量: "+reader.numDocs());
long a=System.currentTimeMillis();
IndexSearcher searcher=new IndexSearcher(reader);
QueryParser parse=new QueryParser(Version.LUCENE_48, "content", new IKAnalyzer(true));
Query query=parse.parse(queryTerm);
TopDocs docs=searcher.search(query, 100);
System.out.println("本次命中结果: "+docs.totalHits+" 条" );
for(ScoreDoc sc:docs.scoreDocs){
System.out.println("评分: "+sc.score+" id : "+searcher.doc(sc.doc).get("id")+" name: "+searcher.doc(sc.doc).get("name")+" 字段内容: "+searcher.doc(sc.doc).get("content"));
}
long b=System.currentTimeMillis();
System.out.println("第一次耗时:"+(b-a)+" 毫秒");
// System.out.println("============================================");
// long c=System.currentTimeMillis();
// query=parse.parse(queryTerm);
//
// docs=searcher.search(query, 100);
// System.out.println("本次命中结果: "+docs.totalHits+" 条" );
// for(ScoreDoc sc:docs.scoreDocs){
//
// System.out.println("评分: "+sc.score+" id : "+searcher.doc(sc.doc).get("id")+" name: "+searcher.doc(sc.doc).get("name")+" 字段内容: "+searcher.doc(sc.doc).get("content"));
//
// }
// long d=System.currentTimeMillis();
// System.out.println("第二次耗时:"+(d-c)+" 毫秒");
reader.close();
directory.close();
System.out.println("检索完毕...............");
}
}
使用IK的分词器,建立索引完毕后,在HDFS上的索引如下截图:
检索数据时,第一次检索往往比较慢,第一次之后因为有了Block Cache,所以第二次,检索的速度非常快,当然这也跟你机器的配置有关系:
本次检索内容: 8 WARN - NativeCodeLoader.<clinit>(62) | Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 总数据量: 9994 本次命中结果: 1 条 评分: 4.7582965 id : 8 name: lucene是一款非常优秀的全文检索框架8 字段内容: 今天发工资了吗8 第一次耗时:261 毫秒 ============================================ 本次命中结果: 1 条 评分: 4.7582965 id : 8 name: lucene是一款非常优秀的全文检索框架8 字段内容: 今天发工资了吗8 第二次耗时:6 毫秒 INFO - HdfsDirectory.close(97) | Closing hdfs directory hdfs://192.168.46.32:9000/qin/myindex 检索完毕...............
为什么要使用Hadoop建索引? 使用Hadoop建索引可以利用MapReduce分布式计算能力从而大大提升建索引的速度,这一点优势很明显,但美中不足的是在Hadoop上做检索,性能却不怎么好,虽然有了块缓存,但是如果索引被按64M的块被切分到不同的节点上,那么检索的时候,就需要跨机器从各个块上扫描,拉取命中数据,这一点是很耗时的,目前,据散仙所知,还没有比较好的部署在Hadoop上的分布式检索方案,但毫无疑问的是建索引的能力,确实很给力,后面散仙会写如何使用MapReduce来并行构建Lucene索引,其实既然单机版的都可以完成,那么稍微改造下变成MapReduce作业,也很简单,大家可以先尝试尝试,有什么问题,欢迎与散仙沟通和交流!
转载请务必注明,原创地址,谢谢配合!
http://qindongliang1922.iteye.com/blog/2090121