Solr研究
一,概述
17173搜索是一套对站内各个系统的信息组织和处理后,为用户提供检索服务,将用户检索的相关信息展示给用户的系统,因为遇到性能问题,故对基于Lucene的搜索框架Solr进行研究,看能否找到相应的解决方案。
二,测试说明
1, BBS总共有七千万条数据(40G左右)。
2, 在对BBS论坛进行搜索查询时,查询时间久,每次搜索都占用较大的CPU与内存,性能比较低。
3, 综之前研究,因业务需求,改为单字切分,使倒排链表算法在搜索时,浪费很多性能。
4, 在对时间进行过滤查询时,查询时间缓慢。
因上述原因,故对Solr进行测试,是否在单字切分时,能否解决这一类型的问题,以便引用
三,性能测试内容
测试分析
1, 在对BBS进行测试一千万条时,查询时间较快,不会发生性能问题,故产生思路对七千万条数据进行切分成六个索引,进行搜索。
2, Solr中提供了切分索引的分布式搜索,对其性能进行测试,如图:
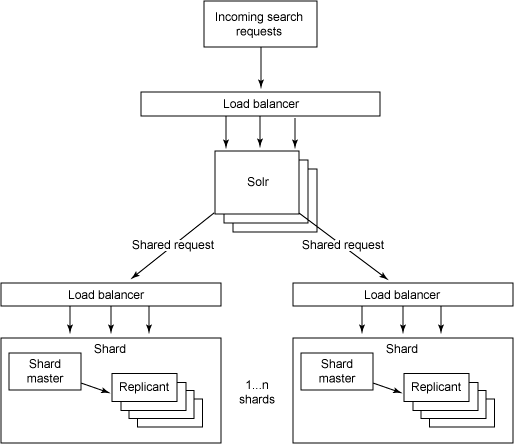
测试结论
1, 搭建三台(solr1,solr2,solr3)服务器,solr1用于对其他两台solr2,solr3进行分发请求及计算。
2, 在发出请求时,查询单字切分的两千万条数据时,使用时间过滤时,查询性能也比较慢。
3, 查看其源码实现方式,solr1会第一次发出请求到solr2,solr3中获取符合条件的文档数,并返回其id与相应的得分数。第二次根据得分数向各服务器发出请求,得到得分较高的文档数后返回,请求查询数为(2*n+1),使性能更低于我们本身的17173站内搜索。
查询性能(17173,solr)比较:
| 框架 |
查询数据 |
时间(ms) |
数据量 |
| 17173(Lucimint) |
“魔”(半年) |
63 |
一千万条 |
| Solr |
“魔”(半年) |
1847 |
一千万条 |
| 17173(Lucimint) |
“剑灵”(半年) |
1023 |
三千万条 |
| Solr |
“剑灵”(半年) |
3000 |
三千万条 |
| 17173(Lucimint) |
侠骨柔情剑气扬,唯我枫月武林狂(半年) |
1937 |
三千万条 |
| Solr |
侠骨柔情剑气扬,唯我枫月武林狂(半年) |
24115 |
三千万条 |
故这种查询分发,对于我们这种类型的查询并没有相应的性能提高。
四,遗留问题分析
Solr还提供了复制模式,用于满足高并发时架构集群,高并发时分发到不同的服务器,达到负载均衡。但是这并不符合,我们少数请求时引起的性能问题。
可对于在用户搜索时,对搜索字进行切分,没有语义的予以去掉,来提高一部分性能。