我想了想,还是决定将那篇讲ZAB协议的文章转载过来,ZK中提交事务采用的就是ZAB协议。
转自:http://blog.csdn.net/m_vptr/article/details/9325405
建议还是看原文,我转载到这里利于我查看。向原作者致敬。
ps:个人感觉原博客的一张图画错了,就是那张Leader和Follower的通信图。个人感觉Commit应该是从Leader指向Follower的。
******************************原文如下************************************
ZooKeeper内部有一个in-memory DB,表示为一个树形结构。每个树节点称为Znode(相关的代码在DataTree.java和DataNode.java中)
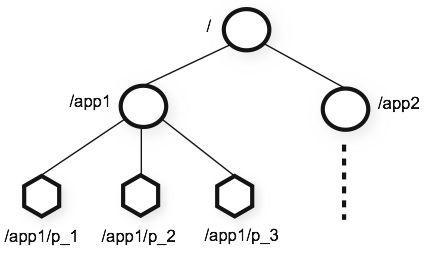
客户端可以连接到zookeeper集群中的任意一台。
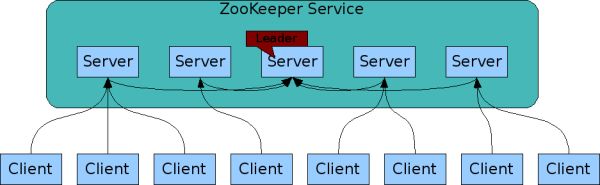
对于读请求,直接返回本地znode数据。写操作则转换为一个事务,并转发到集群的Leader处理。Zookeeper提交事务保证写操作(更新)对于zookeeper集群所有机器都是一致的。
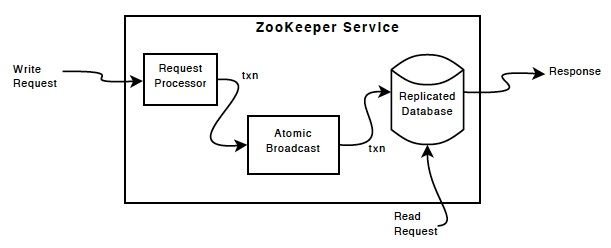
ZooKeeper中提交事务的协议并不是Paxos,而是由二阶段提交协议改编的ZAB协议。
Zab可以满足以下特性
Reliable delivery:如果消息m被一个server递交(commit)了,那么m也将最终被所有server递交。
Total order:如果server在递交b之前递交了a,那么所有递交了a、b的server也会在递交b之前递交a。
Casual order:对于两个递交了的消息a、b,如果a因果关系优先于(causally precedes)b,那么a将在b之前递交。
第三条的因果优先指的是同一个发送者发送的两个消息a先于b发送,或者上一个leader发送的消息a先于当前leader发送的消息。
Zab协议中Server有两个模式:broadcast模式、recovery模式(Leader宕机或follower不构成quorum)
Leader在开始broadcast之前,必须有一个同步更新过的follower的quorum(多数派)。
Server在Leader服务期间恢复在线时,将进入recovery模式,与Leader进行同步。
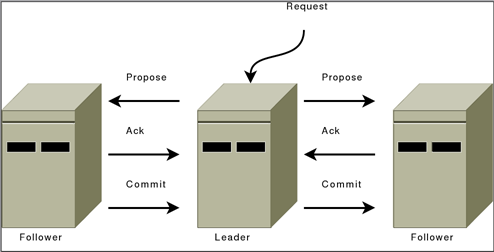
Follower收到proposal后,写到磁盘(尽可能批处理),返回ACK。
Leader收到大多数ACK后,广播COMMIT消息,自己也deliver该消息。
Follower收到COMMIT之后,deliver该消息。
然而,这个简化的二阶段提交不能处理Leader失效的情况,所以增加了recovery模式。切换Leader时,需要解决下面两个问题。
Never forget delivered messages
Leader在COMMIT投递到任何一台follower之前宕机,只有它自己commit了。新Leader必须保证这个事务也必须commit。
Let go of messages that are skipped
Leader产生某个proposal,但是在宕机之前,没有follower看到这个proposal。该server恢复时,必须丢弃这个proposal。
新Leader在propose新消息之前,必须保证事务日志中的所有消息都proposed并且committed。
为了保证follower看到有proposal,以及递交的消息,Leader向follower发送follower没有见过的PROPOSAL,以及最后提交的消息的编号之前的COMMIT。
因为Proposal是保存在follower的事务日志中,并且顺序有保证,因此COMMIT的顺序也是确定的。解决的第一个问题。
上个没有把proposal发送出去的Leader重启后,新Leader将告诉它截断事务日志,一直截断到follower的epoch对应的最后一个commit位置。
关于ZAB的详细证明可以参考Zab - High-performance broadcast for primary-backup systems