ZooKeeper学习
1. 什么是ZooKeeper?
ZooKeeper是一组工具,用来配置和支持分布式调度。以我的理解,就是一个网管软件和库,一个重要功能就是对所有节点进行配置的同步。
它能处理分布式应用的“部分失败”问题。
什么是部分失败?
部分失败是分布式处理系统的固有特征,即发送者无法知道接收者是否收到消息,它出现的可能性有 网络传输出现问题、接收进程已经死掉等。
ZooKeeper是Hadoop的分布式协调服务,ZooKeeper是Hadoop生态系统的一部分,但又远不止如此,它能支持更多类似的分布式平台和系统,如Jubatus,Cassender等等。
而且HBase明确指出至少需要一个ZooKeeper实例的支持。
2. ZooKeeper有什么特征?
其核心是一个精简的文件系统;
其原语是一组丰富的“构件”,可用于实现很多数据结构和协议,如分布式队列,分布式锁,同一级中的领导者选举;能避免单点故障,高可用性;松耦合交互方式:各进程间不必相互了解,同步等;是一个资源库,对通用协议提供一个开源的共享存储库。
3. ZooKeeper有哪些需要配置的属性?
tickTime: ZooKeeper运行的基本时间单元
dataDir: 存储持久数据的本地文件系统位置
clientPort: 监听客户端连接的端口(常用的端口是2181)
4. ZooKeeper的结构,及其相关的一些基本操作
ZooKeeper需要一组服务器来部署,为客户端提供服务。每个客户端会找到其中的一台服务器。问题:如何维护这组服务器?
首先,需要高可靠性。不能使用一个单节点来维护这个服务器列表,这是因为这个节点坏了,整个系统就坏了,可靠性差;而且故障的服务器自身无法将其从列表中删除。
所以,ZooKeeper需要一个具有主动修改能力的、高可靠性的服务来维护这个列表。
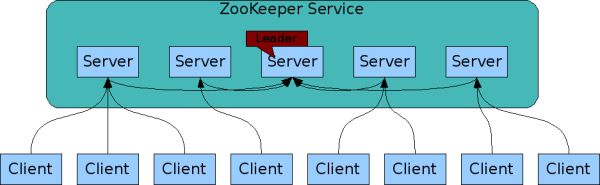
ZooKeeper是一个层次结构。类似一个文件系统的结构,有目录和文件的包含关系。有一个父节点,包含一系列子节点。父节点的命名是组名,子节点的命名就是组成员名了。树形结构:树中的节点被称为znode,znode
ZooKeeper的操作,提供的方法、接口:
create():创建一个znode节点,其必须要有父节点,加入一个组:只需要指定/+groupname + / + membername,然后创建即可
delete():删除一个znode,其必须无子节点。需要提供路径和版本号参数。
exists():测试一个znode是否存在
sync():将客户端的znode视图与ZooKeeper同步
getACL, setACL: ACL:access control list
getChild(): 获取一个znode的子节点列表,如:zk.getChildren(path, false)
getData, setData:获取或者设置一个znode的数据
其中更改操作,需要更新znode的版本号才能完成。
5. 有哪些客户端可用的 ZooKeeper的API?
针对以上ZooKeeper的操作,Zookeeper也为客户端提供了对应的API。有两种绑定的语言Java和C,并提供同步和异步两种方式,功能都相同。
并且,Shell提供了一系列命令,可直接执行,如下
[zkshell: 0] help
ZooKeeper host:port cmd args
get path [watch]
ls path [watch]
set path data [version]
delquota [-n|-b] path
quit
printwatches on|off
createpath data acl
stat path [watch]
listquota path
history
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
deleteall path
setquota -n|-b val path
6. ZooKeeper的数据模型
1) 树形结构、每个znode节点可以存储数据、并有一个关联的ACL。但znode存储的数据被限制在1MB内。
2)数据访问具有原子性,要么成功,要么全部失败。
3)znode通过路径被引用。类似于linux的文件路径。
4)znode有两种,短暂性的和持久性的。短暂性的会在客户端结束后删除
5)顺序号:命名时,zookeeper在名字中指定了顺序号,这个在创建znode时,设置顺序标识就会产生,顺序号,可用于全局排序
6)观察:是一种机制,znode发生变化时,观察机制可以通知客户端(类似于观察者模式),观察注册后只触发一次
一般在读操作exists、getChildren和getData上设置观察,然后这些观察在create、delete、setData时触发。
7)ACL
每个znode被创建都会带有一个ACL列表,用于检验权限:谁,可以对它自己执行,何种操作ACL依赖于ZooKeeper的身份依赖机制。
digest : 利用用户名和密码来识别客户端
host: 通过主机名 hostname 来识别客户端
ip : 利用ip来识别客户端
7. ZooKeeper的实现方式
两种模式:
独立模式:适用于测试环境,甚至单元测试。只有一个ZooKeeper服务器,但是不保证高可用性和恢复性。
复制模式:适用于生产环境,通过复制来保证高可用性和恢复性,保证半数以上的机器处于可用状态。
其实现使用Zab协议,包括两个阶段:
阶段一:领导者选举: 一台机器选为leader,其他为follower,一旦半数以上的机器与leader的同步状态相同,此阶段完成。
阶段二:原子广播:所有写请求给leader,然后再由leader广播给follower,且当半数以上follower完成同步后,leader才提交这个更新,然后客户端才收到完成的响应。若领导者故障,则由follower中选出新的leader。
以上两个过程可以无限循环执行。
8. ZooKeeper如何提供一致性保证?
问题:一个跟随者可能滞后领导者几个更新。
若一个修改/更新需要提交,那么就需要半数以上的机器已将其持久化。每一个对znode树的更新,都会有个全局唯一ID号:zxid,这个ID号用于查询更新的位置。因为ZooKeeper会对所有更新进行排序。
ZooKeeper的更新具有原子性,要么成功,要么失败,不存在部分成功。一旦成功,更新便具有持久性。
但是不同的客户端在读取数据时,由于ZooKeeper外部通信机制的原因,其客户端的ZooKeeper状态可能是不一致的,但这种现象与ZooKeeper的一致性是兼容的。
9. 什么是会话?
一个客户端与一台ZooKeeper服务器建立一个连接,就是会话,每个会话就有一个时间限制,超时就需要重新连接。
客户端尝试链接ZooKeeper服务器失败时,会依次尝试其他服务器,直到成功或者全部失败。
心跳(ping请求):会话空闲时,发送心跳来保证会话不过期,并能检测出服务器故障。
自动故障切换:客户端在连接的服务器发生故障后,能自动切换到另外一台服务器,并且会话继续有效。
10. ZooKeeper有哪些状态?
ZooKeeper对象在一个生命周期内,有好几个状态。
getStates()方法能查询出ZooKeeper的状态。
Connecting : 新建ZooKeeper实例时
Connected : 建立连接后
SyncConnected: 使用“观察”机制,状态转换时
Disconnected: 断开后,状态。一般连接丢失后,它会自动尝试重新连接。
Closed : ZooKeeper被认为不是活跃的,不可用了。
以上这些概念仅仅是ZooKeeper学习的基本东西,还需要构建真正的应用、编写程序去实践。
使用ZooKeeper可以实现很多分布式的数据结构和协议,如barrier, 队列,和两阶段交换协议。
ZooKeeper是一组工具,用来配置和支持分布式调度。以我的理解,就是一个网管软件和库,一个重要功能就是对所有节点进行配置的同步。
它能处理分布式应用的“部分失败”问题。
什么是部分失败?
部分失败是分布式处理系统的固有特征,即发送者无法知道接收者是否收到消息,它出现的可能性有 网络传输出现问题、接收进程已经死掉等。
ZooKeeper是Hadoop的分布式协调服务,ZooKeeper是Hadoop生态系统的一部分,但又远不止如此,它能支持更多类似的分布式平台和系统,如Jubatus,Cassender等等。
而且HBase明确指出至少需要一个ZooKeeper实例的支持。
2. ZooKeeper有什么特征?
其核心是一个精简的文件系统;
其原语是一组丰富的“构件”,可用于实现很多数据结构和协议,如分布式队列,分布式锁,同一级中的领导者选举;能避免单点故障,高可用性;松耦合交互方式:各进程间不必相互了解,同步等;是一个资源库,对通用协议提供一个开源的共享存储库。
3. ZooKeeper有哪些需要配置的属性?
tickTime: ZooKeeper运行的基本时间单元
dataDir: 存储持久数据的本地文件系统位置
clientPort: 监听客户端连接的端口(常用的端口是2181)
4. ZooKeeper的结构,及其相关的一些基本操作
ZooKeeper需要一组服务器来部署,为客户端提供服务。每个客户端会找到其中的一台服务器。问题:如何维护这组服务器?
首先,需要高可靠性。不能使用一个单节点来维护这个服务器列表,这是因为这个节点坏了,整个系统就坏了,可靠性差;而且故障的服务器自身无法将其从列表中删除。
所以,ZooKeeper需要一个具有主动修改能力的、高可靠性的服务来维护这个列表。
ZooKeeper是一个层次结构。类似一个文件系统的结构,有目录和文件的包含关系。有一个父节点,包含一系列子节点。父节点的命名是组名,子节点的命名就是组成员名了。树形结构:树中的节点被称为znode,znode
ZooKeeper的操作,提供的方法、接口:
create():创建一个znode节点,其必须要有父节点,加入一个组:只需要指定/+groupname + / + membername,然后创建即可
delete():删除一个znode,其必须无子节点。需要提供路径和版本号参数。
exists():测试一个znode是否存在
sync():将客户端的znode视图与ZooKeeper同步
getACL, setACL: ACL:access control list
getChild(): 获取一个znode的子节点列表,如:zk.getChildren(path, false)
getData, setData:获取或者设置一个znode的数据
其中更改操作,需要更新znode的版本号才能完成。
5. 有哪些客户端可用的 ZooKeeper的API?
针对以上ZooKeeper的操作,Zookeeper也为客户端提供了对应的API。有两种绑定的语言Java和C,并提供同步和异步两种方式,功能都相同。
并且,Shell提供了一系列命令,可直接执行,如下
[zkshell: 0] help
ZooKeeper host:port cmd args
get path [watch]
ls path [watch]
set path data [version]
delquota [-n|-b] path
quit
printwatches on|off
createpath data acl
stat path [watch]
listquota path
history
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
deleteall path
setquota -n|-b val path
6. ZooKeeper的数据模型
1) 树形结构、每个znode节点可以存储数据、并有一个关联的ACL。但znode存储的数据被限制在1MB内。
2)数据访问具有原子性,要么成功,要么全部失败。
3)znode通过路径被引用。类似于linux的文件路径。
4)znode有两种,短暂性的和持久性的。短暂性的会在客户端结束后删除
5)顺序号:命名时,zookeeper在名字中指定了顺序号,这个在创建znode时,设置顺序标识就会产生,顺序号,可用于全局排序
6)观察:是一种机制,znode发生变化时,观察机制可以通知客户端(类似于观察者模式),观察注册后只触发一次
一般在读操作exists、getChildren和getData上设置观察,然后这些观察在create、delete、setData时触发。
7)ACL
每个znode被创建都会带有一个ACL列表,用于检验权限:谁,可以对它自己执行,何种操作ACL依赖于ZooKeeper的身份依赖机制。
digest : 利用用户名和密码来识别客户端
host: 通过主机名 hostname 来识别客户端
ip : 利用ip来识别客户端
7. ZooKeeper的实现方式
两种模式:
独立模式:适用于测试环境,甚至单元测试。只有一个ZooKeeper服务器,但是不保证高可用性和恢复性。
复制模式:适用于生产环境,通过复制来保证高可用性和恢复性,保证半数以上的机器处于可用状态。
其实现使用Zab协议,包括两个阶段:
阶段一:领导者选举: 一台机器选为leader,其他为follower,一旦半数以上的机器与leader的同步状态相同,此阶段完成。
阶段二:原子广播:所有写请求给leader,然后再由leader广播给follower,且当半数以上follower完成同步后,leader才提交这个更新,然后客户端才收到完成的响应。若领导者故障,则由follower中选出新的leader。
以上两个过程可以无限循环执行。
8. ZooKeeper如何提供一致性保证?
问题:一个跟随者可能滞后领导者几个更新。
若一个修改/更新需要提交,那么就需要半数以上的机器已将其持久化。每一个对znode树的更新,都会有个全局唯一ID号:zxid,这个ID号用于查询更新的位置。因为ZooKeeper会对所有更新进行排序。
ZooKeeper的更新具有原子性,要么成功,要么失败,不存在部分成功。一旦成功,更新便具有持久性。
但是不同的客户端在读取数据时,由于ZooKeeper外部通信机制的原因,其客户端的ZooKeeper状态可能是不一致的,但这种现象与ZooKeeper的一致性是兼容的。
9. 什么是会话?
一个客户端与一台ZooKeeper服务器建立一个连接,就是会话,每个会话就有一个时间限制,超时就需要重新连接。
客户端尝试链接ZooKeeper服务器失败时,会依次尝试其他服务器,直到成功或者全部失败。
心跳(ping请求):会话空闲时,发送心跳来保证会话不过期,并能检测出服务器故障。
自动故障切换:客户端在连接的服务器发生故障后,能自动切换到另外一台服务器,并且会话继续有效。
10. ZooKeeper有哪些状态?
ZooKeeper对象在一个生命周期内,有好几个状态。
getStates()方法能查询出ZooKeeper的状态。
Connecting : 新建ZooKeeper实例时
Connected : 建立连接后
SyncConnected: 使用“观察”机制,状态转换时
Disconnected: 断开后,状态。一般连接丢失后,它会自动尝试重新连接。
Closed : ZooKeeper被认为不是活跃的,不可用了。
以上这些概念仅仅是ZooKeeper学习的基本东西,还需要构建真正的应用、编写程序去实践。
使用ZooKeeper可以实现很多分布式的数据结构和协议,如barrier, 队列,和两阶段交换协议。