26、JavaScript中的XML
只有IE秋Mozilla两个浏览器可以支持客户端的XML处理。
IE中的XML DOM支持
1、DOM创建
对每个新版本的MSXML,都会创建出不同的XML DOMain对象,而它们各自的名称也不相同。MSXML最新的版本是6.0,也就是说,存在以下XML DOM实现:
Micorsoft.XmlDom(最原始的)
MSXML2.DOMDocument
MSXML2.DOMDocument.3.0
MSXML2.DOMDocument.4.0
MSXML2.DOMDocument.5.0
MSXML2.DOMDocument.6.0
注:上面所有串使用时与大小写没有关系
为了确保使用了正确的XMLDOM版本,也为避免任何其他错误,我们可以创建一个函数测试每个XML DOM字符串,出现错误即捕获:
function createXMLDOM() {
var arrSignatures = ["MSXML2.DOMDocument.6.0","MSXML2.DOMDocument.5.0", "MSXML2.DOMDocument.4.0",
"MSXML2.DOMDocument.3.0", "MSXML2.DOMDocument",
"Microsoft.XmlDom"];
for (var i=0; i < arrSignatures.length; i++) {
try {
var oXmlDom = new ActiveXObject(arrSignatures[i]);
return oXmlDom;
} catch (oError) {
//ignore
}
}
throw new Error("MSXML not installed on your system.");
}
//
var oXmlDom = createXMLDOM();
执行代码后oXmlDom就和DOM Document对象行为一样了。
2、载入XML
通过XML DOM对象就可以载入一些XML了。微软的XML DOM有两种载入XML的方法:loadXML()与load()。
loadXML()方法可直接向XML DOM输入XML字符串:
oXmlDom.loadXML('<root><child/></root>');
load()方法用于从服务器上载入XML文件。不过,load()方法只可以载入包含JavaScript的页面存储于同一服务器上的文件 ,也就是说,不可以通过其他人的服务器载入XML文件。
还有两种载入文件的模式:同步与异步。以同步模式载入文件时,JavaScript代码会等待文件完全载入后才继续执行代码;而以异步模式载入时,不会等待,可以使用事件处理函数来判断文件是否完全载入了 。
默认情况下,文件是按照异步模式载入的,要进行同步载入,只需设置async属性为false :
oXmlDom.async = false;
然后使用load()方法,并给出要载入的文件名:
oXmlDom.load('test.xml');
执行这一行代码后,oXmlDom会包含能表示XML文件结构的一个DOM文档,这样就可以使用DOM所有的属性与方法了。
异步载入文件时,要使用readyState属性和onreadystatechange事件处理函数:
readyState属性有一种上可能的值:
- 0——DOM尚未初始化任何信息
- 1——DOM正在载入数据
- 2——DOM完成了数据载入
- 3——DOM已经可用,不过某些部分可能还不能用
- 4——DOM已经完全载入,可以使用了
一旦readyState属性的值发生变化,就会触发readystatechange事件,如果使用onreadystatechange事件处理函数,就可以在DOM完全载入时,发出通知,必须在调用load()方法前分配好onreadystatechange事件处理函数,如:
oXmlDom.onreadystatechange = function () {
if (oXmlDom.readyState == 4) {
alert('done');
}
};
oXmlDom.load("test.xml");
注:事件处理函数代码中要使用oXmlDom而不是this关键字。这是ActiveX对象特殊之处:使用this关键词可能会出现不可预测的错误。
无论是同步还是异步地载入文件,load()方法都可能接受部分的,相对的或者完整的XML文件路径,如下:
oXmlDom.load('test.xml');
oXmlDom.load('../test.xml');
oXmlDom.load('http://www.mydomanin.com/test.xml');
3、获取XML
把XML载入到DOM中后,还需将XML读取出来,微软为每个节点(包括文档节点)都添加了一个xml 属性,获取载入的XML十分的简单:
oXmlDom.load('test.xml');
alert(oXmldom.xml);
也可以仅获取某个特定节点的XML:
var oNode = oXmlDom.documentElement.childNodes[1]; alert(oNode.xml);
xml属性是只读的,如果尝试直接对其赋值会产生错误。
4、解释错误
在尝试将XML载入到XML DOM对象中时,无论是loadXML()方法还是load()方法,都有可能出现XML格式不正确的情况。微软的XML DOM的parseError的属性包含了关于解析XML代码时所遇到的问题的所有信息。
parseError属性实际上是包含以下属性的对象:
- errorCode——表示所发生的错误类型的数字代号(当没有错误时为0)
- filePos——错误发生在文件中的位置
- line——遇到错误的行号
- linepos——在遇到错误的那一行上的字符的位置
- reason——对错误的一个解释
- srcText——造成错误的代码
- url——造成错误的文件的URL(如果可用)
可以使用parseError对象来创建自己的错误对话框:
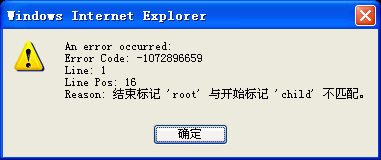
if (oXmlDom.parseError != 0) {
var oError = oXmlDom.parseError;
alert("An error occurred:\nError Code: "
+ oError.errorCode + "\n" + "Line: "
+ oError.line + "\n"
+ "Line Pos: " + oError.linepos + "\n"
+ "Reason: " + oError.reason);
}
检查时应该检查错误代码是否不等于0,因为错误代码可能为正也可能为负。
另一个选项是抛出自己的错误:
if (oXmlDom.parseError != 0) {
var oError = oXmlDom.parseError;
throw new Error(oError.reason
+ " (at line " + oError.line
+ ", position " + oError.linepos
+ ")");
}
不管最终如何显示错误,最好在XML DOM载入完毕后就立即检查错误。
注:MSXML ActiveX控件只能在windows上使用,因此,Macintosh上的IE不能利用这个功能。
Mozilla中XML DOM支持
Mozilla提供的XML DOM版本要比IE的更加标准。Mozilla中的XMLDOM实际上是它的JavaScript实现,也就是说它不仅与浏览器一起衍化。与不能在Macintosh上使用XML DOM的IE不同,Mozilla的支持跨越了平台的界限。别外,Mozilla的XML DOM实现了支持DOM Level2的功能,而微软的,仅支持DOM Level1。
1、创建DOM
DOM标准指出,document.implementation 对象有个可用的createDocument()方法。Mozilla严格遵循了这个标准,可以通过此标准创建XML DOM:
在Mozilla浏览器中创建XML文档对象的方法如下。
document.implementation.createDocument(namespaceURI , rootname , doctype )
其中namespaceURI参数代表XML文档的命名空间URI,rootname参数代表根节点名称,而doctype表示创建文档的类型,目前Mozilla并没有实现对doctype该参数的支持,因此在实际使用时doctype的赋值为null。
如果namespaceURI和rootname参数为空字符串,那么createDocument方法将创建一个空DOM对象 ,即:
var doc = document.implementation.createDocument("", "", null);
要创建包含一个文档元素(根节点)的XMLDOM,只需将标签名作为第二个参数:
var oXmlDom = document.implementation.createDocument('','root',null);
这行代码创建了代表XML代码<root/>的XML DOM。如果在第一个参数中指定了命令空间URL,可进一步定义文档元素:
var oXmlDom = document.implementation.createDocument('http://www.wrox.com','root',null);
这行代码创建了表示<a0:root xmlns:a0='http://www.wrox.com'/> 的XML DOM。Mozilla自动创建一个称为a0的命名空间来表示输入的命名空间URL。
2、载入XML
与微软的XML DOM不同,Mozilla只支持一个载入数据的方法:load()。Mozilla中的load()方法和IE中的load()工作方式一样,只要指定要载入的XML文件,以及同步还是异步(默认)载入。
如果同步载入XML文件,代码基本上与IE差不多:
oXmlDom.async = false;
oXmlDom.load('test.xml');
如果进行异步载入,情况就有些不同了。Mozilla的XML DOM并不支持微软的readyState属性(实际上,readyState并非Mozilla的实现所遵循的DOM Level3载入和保存规范的一部份)。相反,Mozilla的XML DOM会在文件全载入后触发load事件,也就是说不用使用onload事件处理函数来判断DOM何时可用 :
oXmlDom.onload = function(){
alert('Done');
}
oXmlDom.load('test.xml');
注:在1.4版之前,Mozilla支持外部文件的异步载入,在1.4中,Mozilla引用了async属性以及同步载入的能力。
不过,Mozilla的XML DOM并不支持loadXML()方法 ,要将XML字符器解析为DOM,必须使用DOMParser对象:
var oParser = new DOMParser();
var oXmlDom = oParser.parseFromString('<root/>','text/xml');
这段代码创建了代表<root/>的XML DOM。每一行创建DOMParser对象,第二行用它唯一方法parseFromString()来创建XML DOM。这个方法接受两个参数,要解析的XML字符串以及字符串的内容类型。要解析XML代码,内容类型可以是'text/xml'或者'application/xml';任何其他内容类型都被忽略。
因为XML DOM只是Mozilla的JavaScript实现的一部分,所以它可自己添加loadXML()方法。XML DOM实际的类称为Document,所以添加新方法同时使用prototype对象一样容易;
Document.prototype.loadXML = function (sXml) {
var oParser = new DOMParser();
var oXmlDom = oParser.parseFromString(sXml, "text/xml");
//原来的文档必须清空其内容,可用while循环来删除所有的文档子节点
while (this.firstChild) {
this.removeChild(this.firstChild);
}
//this指向XML DOM对象
for (var i=0; i < oXmlDom.childNodes.length; i++) {
//在删除所有子节点后,所有的oXmlDom的子节点必须导入到文档中
var oNewNode = this.importNode(oXmlDom.childNodes[i], true);
//最后添加到XML DOM
this.appendChild(oNewNode);
}
};
只需包含这段代码,在Mozill中就可以与在IE中一样地使用loadXML()方法了。
注:这段代码会在IE中造成错误,因为不存在Document对象,因此,在代码外要使用浏览器检测来避免这个问题。
3、获取XML
微软的XML DOM提供了xml属性,可以很方便地访问下面的XML代码。因为这个属性并非标准的一部分,Mozilla不支持它。但是,Mozilla提供了可以胜于同样的目的的XMLSerializer对象:
var oSerializer = new XMLSerializer(); var sXml = oSerializer.serializeToString(oXmlDom, "text/xml");
XMLSerializer唯一方法serializerToString()为oXmlDom生成了XML代码。第一个参数为要序列化的节点,第二个为内容类型。内容类型可以是'text/xml'或‘application/xml'。使用这个对象,就可以自己为Mozilla的XML DOM生成xml属性,只需使用一个鲜为人知的defineGetter()方法。
defineGetter()方法只存在于Mozilla中,用于为某个属性定义读取函数(get方法),在读取属性时,会调用这个函数并返回它的结果,例如:
var sValue = oXmlNode.nodeValue;//读属性 oXmlNode.nodeValue = 'New value';//写属性
第一行代码读取nodeValue属性值,即解释器读取属性的值,如果定义了获取函数,就会调用自定义属性读取函数将结果返回。第二行代码对nodeValue属性进行设置,此时如果定义了属性设置函数,则调用这个函数,并以 New value 作为参数值,创建写属性自定义函数的为 defineSetter() 方法,但在这里用不到。
方法 defineGetter() 是按照JavaScript对于私有属性和方法标准隐藏——在名字前后加上两个下划线。
因为文档中每种类型的节点都要有xml属性,所以最好将其添加到Node类型中(其他的节点类型都是继承Node的):
Node.prototype.__defineGetter__("xml", function () {
var oSerializer = new XMLSerializer();
return oSerializer.serializeToString(this, "text/xml");
});
为每个Node分配xml属性的读取函数十分简单,对前面的例子唯一改变是:this是serializeToString()方法的第一个参数(在此上下文中,this指向节点自身)。
经过以上处理,现可以与使用微软的xml属性方式一样地使用自定义的xml属性:
oXmlDom.load('test.xml');
alert(oXmldom.xml);
var oNode = oXmlDom.documentElement.childNodes[1];
alert(oNode.xml);
注:这段代码必须包含在浏览器检测中,因为它只能运行在Mozilla中。
4、解析错误
在XML文件的解析过程中发生错误时,XML DOM会创建文档来解释这个错误。假设运行以下代码:
Node.prototype.__defineGetter__("xml", function () {
var oSerializer = new XMLSerializer();
return oSerializer.serializeToString(this, "text/xml");
});
try{
var oParser = new DOMParser();
//var oXmlDom = oParser.parseFromString('<root><child></root>');源码有错,一定要带上类型参数
var oXmlDom = oParser.parseFromString('<root><child></root>','text/xml');
var x = oXmlDom.xml;
if (oXmlDom.documentElement.tagName == "parsererror") {
alert(x);
return;
}else{
//do something ...
}
}catch (e){
alert(e.name + '\n' + e.message);
}
上面代码中XML串不完整,但运行时也未抛出任何错误,此时错误信息会存储在oXmlDom中,我们打印oXmlDom的xml属性,显示的错误提示信息框如下:
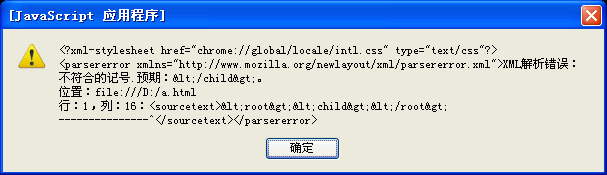
由提示信息可知,要判断是否在XML代码的解析过程中是否有错误,必须测试文档元素的标签名,然后还可通过正则式提取详细准确的错误信息(但要注意是中否还是英文的,至少在中英文浏览器上显示的信息是不一样的,这里我觉得不必要提取这些信息,直接弹出上面的框也可以,这里就不实现了)。
XML DOM与HTML DOM中文档对象的documentElement属性
var oParser = new DOMParser();
var oXmlDom = oParser.parseFromString('<root><child1>text1</child1><child2>text2</child2></root>','text/xml');
//oXmlDom的类型与HTML DOM中的document类型是一样的,都是文档对象
alert(oXmlDom.nodeType == Node.DOCUMENT_NODE); //true
alert(document.nodeType == Node.DOCUMENT_NODE); //true
//documentElement都是得到文档的根元素
alert(oXmlDom.documentElement.tagName);//root
alert(document.documentElement.tagName);//HTML
alert(oXmlDom.documentElement.childNodes[0].tagName);//child1
alert(document.documentElement.childNodes[0].tagName);//HEAD
通用接口
1、通用接口实现
由于IE与Mozilla上的XML DOM实现有很大的不同,为了使用时不用区分这两种浏览器,我们需要实现通用脚本。实现的思想是把Mozilla上的XML DOM适配成微软的XML DOM即可。但书上的源码有问题,一是在firefox不同的语言版本上有不同的解析错误(中英问题),所以这里就不用正则试提取错误信息,而是在使用时如果出现错误直接显示出来。二是在firefox上已有readyState属性,而且发现是只读的值 complete ,所有想适配成微软的readyState有难度,这里用添加一个读取它的方法。经过这样做以后,实质上在使用时又不是统一接口,还要根据不现的浏览器来显示不同的错误,唉~有点怪怪的,到目前还没有想出好的办法,后面也附上书的源码...
if (isMoz) {
//模拟微软异步加载XML时0,1,4状态,其他状态不好模拟,也不重要,所以就不必模式了
//0状态表示DOM尚未初始化任何信息,可以直接赋于Document原型中readyState为0,
//至于1状态,表示DOM正在载入数据,在加载XML前模拟设置即可;最后是4状态,表示
//DOM已经完全载入,可以使用了,因此可以在XML加载动作之后模拟设置即可
Document.prototype._readyState_ = 0;
//状态改变时要调用的事件处理函数
Document.prototype.onreadystatechange = null;
//加载XML状态改变时实现,私有的,由XMLDOM在加载XML文件动作前与后调用
Document.prototype.__changeReadyState__ = function (iReadyState) {
//此句在 firefox3.7上运行报错:setting a property that has only a getter,因为
//创建出的xml DOM对象就有readyState属性,且是只读的,所有以这把readyState改为
//_readyState_
this._readyState_ = iReadyState;
if (typeof this.onreadystatechange == "function") {
//onreadystatechange由用户自已实现,模式状态改变时调用
this.onreadystatechange();
}
};
//初始化parseError对象内部属性,在load、loadXML方法开头处调用
Document.prototype.__initError__ = function () {
//表示所发生的错误类型的数字代号(当没有错误时为0)
this.parseError.errorCode = 0;
};
//加载完(状态为4时)判断加载过程是否有错,如果出错,设置错误信息,在load、loadXML方法后处调用
Document.prototype.__checkForErrors__ = function () {
//如果加载完XML过程中出错时,提取详细错误信息
if (this.documentElement.tagName == "parsererror") {
this.parseError.errorCode = -999999;
}
};
//给Document对象添加loadXML方法,loadXML方法可以加载XML串,而不是XML文件
Document.prototype.loadXML = function (sXml) {
//初始化错误信息
this.__initError__();
//解析前修改状态为1
this.__changeReadyState__(1);
var oParser = new DOMParser();
var oXmlDom = oParser.parseFromString(sXml, "text/xml");
while (this.firstChild) {
this.removeChild(this.firstChild);
}
for (var i = 0; i < oXmlDom.childNodes.length; i++) {
var oNewNode = this.importNode(oXmlDom.childNodes[i], true);
this.appendChild(oNewNode);
}
//解析过程是否出错
this.__checkForErrors__();
//加载完成后修改状态
this.__changeReadyState__(4);
};
Document.prototype.__load__ = Document.prototype.load;
//为了模拟状态,需修改原load方法,此方法好比代理
Document.prototype.load = function (sURL) {
this.__initError__();
//首先将状态设置成1
this.__changeReadyState__(1);
//然后调用原来的load方法
this.__load__(sURL);
};
//在使用时调用此方法模拟获取readyState
Document.prototype.getReadyState = function () {
return this._readyState_;
};
//给每个节点增加xml属性
Node.prototype.__defineGetter__("xml", function () {
var oSerializer = new XMLSerializer();
return oSerializer.serializeToString(this, "text/xml");
});
}
function XmlDom() {
//如果是IE浏览器
if (window.ActiveXObject) {
var arrSignatures = ["MSXML2.DOMDocument.6.0","MSXML2.DOMDocument.5.0", "MSXML2.DOMDocument.4.0",
"MSXML2.DOMDocument.3.0", "MSXML2.DOMDocument", "Microsoft.XmlDom"];
//从最新版本开始尝试,这样可以确保使用最新 XMLDOM
for (var i = 0; i < arrSignatures.length; i++) {
try {
//创建XMLDOM对象
var oXmlDom = new ActiveXObject(arrSignatures[i]);
return oXmlDom;
}
catch (oError) {
//ignore
}
}
//否则未安装MSXML组件
throw new Error("MSXML is not installed on your system.");
} else {//否则是否为Mozilla浏览器
if (document.implementation && document.implementation.createDocument) {
//创建无命令空间,空的 XML DOM
var oXmlDom = document.implementation.createDocument("", "", null);
//为XMLDOM添加微软paseError对象
oXmlDom.parseError = {valueOf:function () {
return this.errorCode;
}, toString:function () {
return this.errorCode.toString();
}};
//初始化parseError对象里的内部信息
oXmlDom.__initError__();
//通过load事件模拟状态4
oXmlDom.addEventListener("load", function () {
this.__checkForErrors__();
this.__changeReadyState__(4);
}, false);
return oXmlDom;
} else {
throw new Error("Your browser doesn't support an XML DOM object.");
}
}
}
2、示例
<html>
<head>
<title>Cross-Browser XML DOM Example</title>
<script type="text/javascript" src="detect.js"></script>
<script type="text/javascript" src="xmldom.js"></script>
</head>
<body>
<script type="text/javascript">
var oXmlDom = new XmlDom();
oXmlDom.onreadystatechange = function () {
//如果oXmlDom.getReadyState存在则为Mozilla浏览器
if (oXmlDom.readyState == 4 || (oXmlDom.getReadyState
&& oXmlDom.getReadyState() == 4)) {
//如果解释XML出错
if (oXmlDom.parseError != 0) {
//Mozilla
if (oXmlDom.getReadyState) {
alert(oXmlDom.xml);
//IE
} else {
var oError = oXmlDom.parseError;
alert("An error occurred:\nError Code: "
+ oError.errorCode + "\n"
+ "Line: " + oError.line + "\n"
+ "Line Pos: " + oError.linepos + "\n"
+ "Reason: " + oError.reason);
}
} else {
//do somethins ...
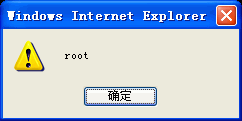
alert(oXmlDom.documentElement.tagName);
}
}
};
oXmlDom.loadXML("<root><child></root>");
oXmlDom.loadXML("<root><child/></root>");
</script>
</body>
</html>
以下是执行结果图:
firefox:
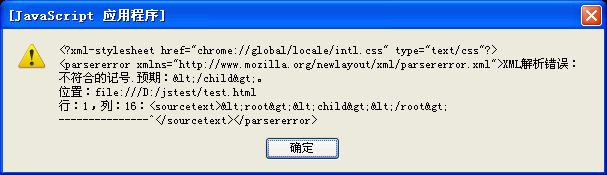
IE: