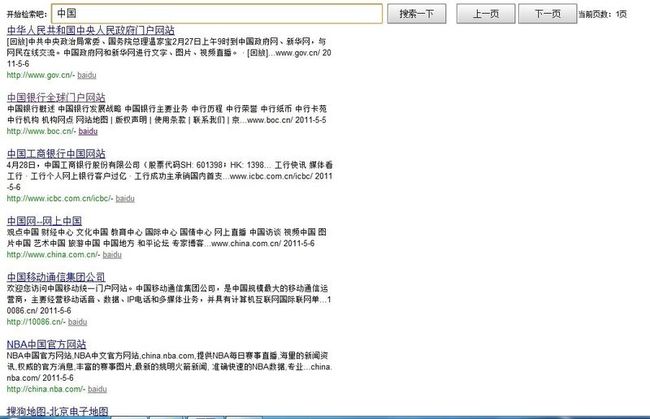
统一检索以实现资源整合的初步实践
这里所指的统一检索是指实现资源的整合。用户使用各种检索时由于存储方式,存储格式的不同,给用户造成诸多不便,这就需要一个统一的平台对资源进行整合。这里利用baidu和google的检索资源初步实现了一个资源整合的例子。运行环境需要浏览器支持html5的websocket。检索服务器采用jetty。使用方式可参考以前写的博文。
下边就粘贴写主要的代码:
TaskManager.java
package org.search.core.site;
import java.util.HashMap;
import java.util.Iterator;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import org.search.core.adapter.SiteAdapter;
import org.search.core.parser.ParserThread;
/**
* 任务派发的主要管理者
* @author yangzc
*
*/
public class TaskManager {
private SiteMap siteMap = null;
//线程池用
private ThreadPoolExecutor siteThreadPool;
private ArrayBlockingQueue<Runnable> threadQueue;
//返回结果队列
private ArrayBlockingQueue<DataMap> dataqueue;
public TaskManager(){
threadQueue = new ArrayBlockingQueue<Runnable>(10);
siteThreadPool = new ThreadPoolExecutor(5, 10, 0, TimeUnit.SECONDS, threadQueue);
dataqueue = new ArrayBlockingQueue<DataMap>(100);
}
public void setSiteMap(SiteMap siteMap){
this.siteMap = siteMap;
}
/**
* 开启单个任务
* @param siteId
* @param params
*/
public void startTask(String siteId, HashMap<String, String> params){
SiteAdapter site = siteMap.get(siteId);
siteThreadPool.execute(new ParserThread(site, params, dataqueue));
siteThreadPool.shutdown();
}
/**
* 开启所有任务
* @param params
*/
public void startAllTask(HashMap<String, String> params){
Iterator<String> keyIterator = siteMap.keySet().iterator();
while(keyIterator.hasNext()){
String siteId = keyIterator.next();
SiteAdapter site = siteMap.get(siteId);
siteThreadPool.execute(new ParserThread(site, params, dataqueue));
}
siteThreadPool.shutdown();
}
public boolean isShutDown(){
return siteThreadPool.isShutdown();
}
public DataMap getFirstData(){
try {
if(siteThreadPool.getActiveCount() != 0 || dataqueue.size()>0)
return dataqueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
}
}
ContextParser.java
package org.search.core.parser;
import java.util.ArrayList;
import java.util.List;
import org.htmlparser.Node;
import org.htmlparser.Parser;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
import org.search.core.adapter.ISiteCell;
import org.search.core.adapter.SiteAdapter;
import org.search.core.filter.MyNodeFilter;
/**
* html内容解析
* @author yangzc
*
*/
public class ContextParser {
private SiteAdapter site;
public ContextParser(SiteAdapter site){
this.site = site;
}
/**
* 取得每条记录
* @param context
* @return
*/
public List<String> getRecord(String context){
List<String> recordlst = new ArrayList<String>();
try {
Parser parser = new Parser(context);
NodeList nodeList =
parser.parse(new MyNodeFilter(site.getRecordCell().getLabel()));
if(nodeList != null && nodeList.size() >0){
for(int i=0; i< nodeList.size(); i++){
Node node = nodeList.elementAt(i);
recordlst.add(node.toHtml(true));
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return recordlst;
}
/**
* 取得标题
* @param record
* @return
*/
public String getTitle(String record){
return getHtml(record, site.getTitleCell());
}
/**
* 取得概述
* @param record
* @return
*/
public String getSummary(String record){
return getHtml(record, site.getSummaryCell());
}
/**
* 取得URL
* @param record
* @return
*/
public String getUrl(String record){
return getHtml(record, site.getUrlCell());
}
//========================================================
public String getHtml(String record, ISiteCell cell){
if(cell.getLabel() != null){//通过标签的方式取得内容
return getHtmlByNode(record, cell.getLabel());
}else{
return getHtmlByIndex(record, cell.getStartString(),
cell.getEndString());
}
}
/**
* 通过开始和结束位置取内容
* @param record
* @param startString
* @param endString
* @return
*/
public String getHtmlByIndex(String record, String startString, String endString){
String txt = record;
int startIndex = txt.indexOf(startString);
if(startIndex == -1)return "";
txt = txt.substring(startIndex+startString.length());
int endIndex = txt.indexOf(endString);
if(endIndex == -1)return "";
return "<html>"+txt.substring(0, endIndex)+"</html>";
}
/**
* 通过节点取内容(htmlclient的方式)
* @param record
* @param filter
* @return
*/
public String getHtmlByNode(String record, String filter){
try {
Parser parser = new Parser(record);
NodeList nodeList = parser.parse(new MyNodeFilter(filter));
if(nodeList != null && nodeList.size()>0){
Node node = nodeList.elementAt(0);
return node.toHtml(true);
}
} catch (ParserException e) {
e.printStackTrace();
}
return "";
}
}
效果如下: