转载请注明出处
项目代码https://github.com/zuoshu/android-voicesearch-opensource.git
调用google手机版语音识别云服务,3g网络下速度快,流量小,识别准,无弹出框。
由于项目需要用到语音识别,选用google的语音识别服务,现在一般的做法是将语音通过post发到http://www.google.com/speech-api/v1/recognize?lang=en-us,再从返回里面取识别结果。在wifi的情况下速度还可以接受,但是在3g的情况下速度很慢。和Android上的VoiceSearch比起来慢很多。看了下VoiceSearch的log,发现voicesearch连接的其实是www.google.com/m/voice-search。一般的做法最初是从chrome开源代码里面找到的,而VoiceSearch属于android平台,在google内部这两个产品分属两个不同的团队,猜测后台的语音识别服务其实实现了两套?总而言之,android/ios和chrome使用的语音识别是不一样的,并且android/ios的速度要快很多。
但是,VoiceSearch不开源,没办法,只能从反编译apk入手,有些地方反编译也没办法,过程比较费劲,直接上结果。
这个是使用www.google.com/speech-api/v1/recognize作为语音识别服务的结果,3g网络下用时2878ms
这个是使用www.google.com/m/voice-search作为语音识别服务的结果,3g网络下用时828ms
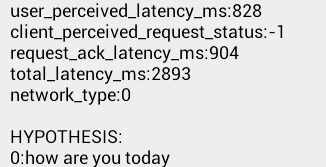
速度相差3倍左右,多次测试发现,后一种基本上会在2秒内返回结果,前一种长的时候会要10多秒。
VoiceSearch具体的工作原理如何?稍后上分析过程,这里直接上工作原理。
VoiceSearch采用protobuf作为数据传输协议。发送语音的过程使用protobuf包装数据,然后通过http或tcp发送。
协议大致包括Alternates,ClientParametersProto,ClientReportProto,GoogleSearchRequest,IntentApi,PartialResult,RecognitionContextProto,RecognitionResultSet,SpeechService,VoiceSearch
具体流程如下
1.建立session
客户端先手机手机上的一些信息,比如地区,系统等,然后生成一个SpeechService.CreateSessionRequest的协议包,通过post发送到www.google.com/m/voice-search,将返回的结果以SpeechService.CreateSessionResponse来解析,结果里面包含ip,port,stunid三个重要的信息。用这个ip和port建立socket连接,在识别结束之前,socket一直不关闭。用stunId生成一个StunPacket(这里用的不是protobuf)
private static byte[] createStunBindingRequest(String stunId)
throws UnsupportedEncodingException {
StunPacket packet = new StunPacket(
StunMessageType.STUN_BINDING_REQUEST);
StunAttribute stunAttribute = new StunAttribute(
StunAttributeType.STUN_ATTR_USERNAME);
stunAttribute.setData(new StunAttribute.Username(stunId));
packet.addAttribute(stunAttribute);
return packet.asByteArray();
}
将StunPacket发送给服务器,服务器会有一个返回。这时,session就建立了。
2.录音
录音编码这部分也有特殊处理。先通过AudioRecord录制原始数据
mAudioRecord = new AudioRecord(6, sampleRateInHz, 16, 2, Math.max( AudioRecord.getMinBufferSize(sampleRateInHz, 16, 2), bufferSizeInBytes));
packetSize为320。再通过AMR_NB压缩
3.发送数据
一个320byte的原始数据被压缩为32byte的AMR_NB数据,每448的AMR_NB数据发送一次,用448byte的AMR_NB数据生成一个SpeechService.MediaData,通过socket发送到服务器。
4.获取结果
建立连接后,发送语音数据的时候,服务器会不定时返回一个SpeechService.RecognizeAck数据包,不管就可以。录音结束时,发送一个空数据的SpeechService.MediaData数据包。服务器会返回一个SpeechService.RecognizeResponse数据包。识别结果都包含在里面。结束之后,客户端发送一个DestroySession的数据包关闭session。
5.其他参数
在建立session的时候,可以通过一个参数setEnablePartialResults来设置是否返回partial result,如果设置true,则可以一边说,一边有识别结果返回。
可以通过setLanguage来设置语言,"en-US"为英文,"zh-CN"为中文。
先放apk和协议,项目稍后放出,见附件apk_and_protos.rar,其中voice1.apk为使用速度快的语音识别,voice2.apk为使用速度慢的语音识别