LZW数据压缩算法的原理分析
1.LZW的全称是什么?
[url=]Lempel-Ziv-Welch (LZW)[/url].
2. LZW的简介和压缩原理是什么?
LZW压缩算法是一种新颖的压缩方法,由Lemple-Ziv-Welch 三人共同创造,用他们的名字命名。它采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表中,用一个数字来表示串,压缩文件只存贮数字,则不存贮串,从而使图象文件的压缩效率得到较大的提高。奇妙的是,不管是在压缩还是在解压缩的过程中都能正确的建立这个串表,压缩或解压缩完成后,这个串表又被丢弃。
LZW算法中,首先建立一个字符串表,把每一个第一次出现的字符串放入串表中,并用一个数字来表示,这个数字与此字符串在串表中的位置有关,并将这个数字存入压缩文件中,如果这个字符串再次出现时,即可用表示它的数字来代替,并将这个数字存入文件中。压缩完成后将串表丢弃。如"print" 字符串,如果在压缩时用266表示,只要再次出现,均用266表示,并将"print"字符串存入串表中,在图象解码时遇到数字266,即可从串表中查出266所代表的字符串"print",在解压缩时,串表可以根据压缩数据重新生成。
3.在详细介绍算法之前,先列出一些与该算法相关的概念和词汇
1)'Character': 字符,一种基础数据元素,在普通文本文件中,它占用1个单独的byte,而在图像中,它却是 一种代表给定像素颜色的索引值。
2)'CharStream':数据文件中的字符流。
3)'Prefix':前缀。如这个单词的含义一样,代表着在一个字符最直接的前一个字符。一个前缀字符长度可以为0,一个prefix和一个character可以组成一个字符串(string),
4)'Suffix': 后缀,是一个字符,一个字符串可以由(A,B)来组成,A是前缀,B是后缀,当A长度为0的时候,代表Root,根
5)'Code:码,用于代表一个字符串的位置编码
6)'Entry',一个Code和它所代表的字符串(string)
4.压缩算法的简单示例,不是完全实现LZW算法,只是从最直观的角度看lzw算法的思想
对原始数据ABCCAABCDDAACCDB进行LZW压缩
原始数据中,只包括4个字符(Character),A,B,C,D,四个字符可以用一个2bit的数表示,0-A,1-B,2-C,3-D,从最直观的角度看,原始字符串存在重复字符:ABCCAABCDDAACCDB,用4代表AB,5代表CC,上面的字符串可以替代表示为:45A4CDDAA5DB,这样是不是就比原数据短了一些呢!
5.LZW算法的适用范围
为了区别代表串的值(Code)和原来的单个的数据值(String),需要使它们的数值域不重合,上面用0-3来代表A-D,那么AB就必须用大于3的数值来代替,再举另外一个例子,原来的数值范围可以用8bit来表示,那么就认为原始的数的范围是0~255,压缩程序生成的标号的范围就不能为0~255(如果是0-255,就重复了)。只能从256开始,但是这样一来就超过了8位的表示范围了,所以必须要扩展数据的位数,至少扩展一位,但是这样不是增加了1个字符占用的空间了么?但是却可以用一个字符代表几个字符,比如原来255是8bit,但是现在用256来表示254,255两个数,还是划得来的。从这个原理可以看出LZW算法的适用范围是原始数据串最好是有大量的子串多次重复出现,重复的越多,压缩效果越好。反之则越差,可能真的不减反增了。
6.LZW算法中特殊标记
随着新的串(string)不断被发现,标号也会不断地增长,如果原数据过大,生成的标号集(string table)会越来越大,这时候操作这个集合就会产生效率问题。如何避免这个问题呢?Gif在采用lzw算法的做法是当标号集足够大的时候,就不能增大了,干脆从头开始再来,在这个位置要插入一个标号,就是清除标志CLEAR,表示从这里我重新开始构造字典,以前的所有标记作废,开始使用新的标记。
这时候又有一个问题出现,足够大是多大?这个标号集的大小为比较合适呢?理论上是标号集大小越大,则压缩比率就越高,但开销也越高。 一般根据处理速度和内存空间连个因素来选定。GIF规范规定的是12位,超过12位的表达范围就推倒重来,并且GIF为了提高压缩率,采用的是变长的字长。比如说原始数据是8位,那么一开始,先加上一位再说,开始的字长就成了9位,然后开始加标号,当标号加到512时,也就是超过9为所能表达的最大数据时,也就意味着后面的标号要用10位字长才能表示了,那么从这里开始,后面的字长就是10位了。依此类推,到了2^12也就是4096时,在这里插一个清除标志,从后面开始,从9位再来。
GIF规定的清除标志CLEAR的数值是原始数据字长表示的最大值加1,如果原始数据字长是8,那么清除标志就是256,如果原始数据字长为4那么就是16。另外GIF还规定了一个结束标志END,它的值是清除标志CLEAR再加1。由于GIF规定的位数有1位(单色图),4位(16色)和8位(256色),而1位的情况下如果只扩展1位,只能表示4种状态,那么加上一个清除标志和结束标志就用完了,所以1位的情况下就必须扩充到3位。其它两种情况初始的字长就为5位和9位。此处参照了http://blog.csdn.net/whycadi/
7.用lzw算法压缩原始数据的示例分析
输入流,也就是原始的数据为:255,24,54,255,24,255,255,24,5,123,45,255,24,5,24,54..................
这个正好可以看到是gif文件中像素数组的一部分,如何对它进行压缩
因为原始数据可以用8bit来表示,故清除标志Clear=255+1 =256,结束标志为End=256+1=257,目前标号集为
0 1 2 3 .................................................................................255 CLEAR END
第一步,读取第一个字符为255,在标记表里面查找,255已经存在,我们已经认识255了,不做处理
第二步,取第二个字符,此时前缀为A,形成当前的Entry为(255,24),在标记集合不存在,我们并不认识255,24好,这次你小子来了,我就记住你,把它在标记集合中标记为258,然后输出前缀A,保留后缀24,并作为下一次的前缀(后缀变前缀)
第三步,取第三个字符为54,当前Entry(24,54),不认识,记录(24,54)为标号259,并输出24,后缀变前缀
第四部:取第四个字符255,Entry=(54,255),不认识,记录(54,255)为标号260,输出54,后缀变前缀
第五步 取第5个字符24,entry=(255,24),啊,认识你,这不是老258么,于是把字符串规约为258,并作为前缀
第六步 取第六个字符255,entry=(258,255),不认识,记录(258,255)为261,输出258,后缀变前缀
.......
一直处理到最后一个字符,
用一个表记录处理过程
CLEAR=256,END=257
第几步 前缀 后缀 Entry 认识(Y/N) 输出 标号
1
255 (,255)
2 255 24 (255,24) N 255 258
3 24 54 (24,54) N 24 259
4 54 255 (54,255) N 54 260
5 255 24 (255,24) Y
6 258 255 (258,255) N 258 261
7 255 255 (255,255) N 255 262
.....
上面这个示例有些不能完整体现,另外一个例子是
原输入数据为:A B A B A B A B B B A B A B A A C D A C D A D C A B A A A B A B .....
采用LZW算法对其进行压缩,压缩过程用一个表来表述为:
注意原数据中只包含4个character,A,B,C,D
用两bit即可表述,根据lzw算法,首先扩展一位变为3为,Clear=2的2次方+1=4; End=4+1=5;
初始标号集因该为
0 1 2 3 4 5
A B C D Clear End
而压缩过程为:
第几步 前缀 后缀 Entry 认识(Y/N) 输出 标号
1
A (,A)
2 A B (A,B) N A 6
3 B A (B,A) N B 7
4 A B (A,B) Y
5 6 A (6,A) N 6 8
6 A B (A,B) Y
7 6 A (6,A) Y
8 8 B (8,B) N 8 9
9 B B (B,B) N B 10
10 B B (B,B) Y
11 10 A (10,A) N 10 11
12 A B (A,B) Y
.....
当进行到第12步的时候,标号集应该为
0 1 2 3 4 5 6 7 8 9 10 11
A B C D Clear End AB BA 6A 8B BB 10A
8.LZW算法的伪代码实现
1STRING =
get input character
2WHILE there are still input characters DO
3 CHARACTER =
get input character
4 IF STRING+CHARACTER is
in the string table then
5 STRING = STRING+character
6 ELSE
7 output the code for STRING
8 add STRING+CHARACTER to the string table
9 STRING = CHARACTER
10 END of IF
11END of WHILE
12output the code for STRING
13
9.LZW算法的流程图
没有安visio,画了一个,比较难看,
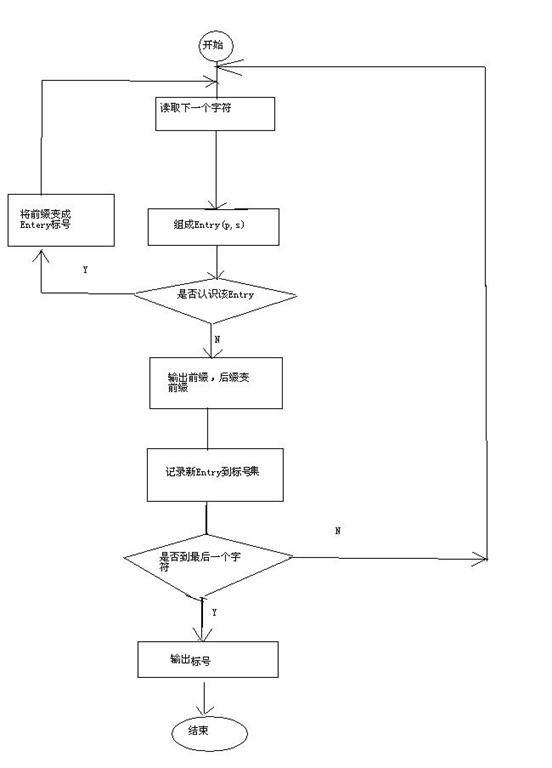
原文地址:http://www.cnblogs.com/jillzhang/archive/2006/11/06/551298.html
[url=]Lempel-Ziv-Welch (LZW)[/url].
2. LZW的简介和压缩原理是什么?
LZW压缩算法是一种新颖的压缩方法,由Lemple-Ziv-Welch 三人共同创造,用他们的名字命名。它采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表中,用一个数字来表示串,压缩文件只存贮数字,则不存贮串,从而使图象文件的压缩效率得到较大的提高。奇妙的是,不管是在压缩还是在解压缩的过程中都能正确的建立这个串表,压缩或解压缩完成后,这个串表又被丢弃。
LZW算法中,首先建立一个字符串表,把每一个第一次出现的字符串放入串表中,并用一个数字来表示,这个数字与此字符串在串表中的位置有关,并将这个数字存入压缩文件中,如果这个字符串再次出现时,即可用表示它的数字来代替,并将这个数字存入文件中。压缩完成后将串表丢弃。如"print" 字符串,如果在压缩时用266表示,只要再次出现,均用266表示,并将"print"字符串存入串表中,在图象解码时遇到数字266,即可从串表中查出266所代表的字符串"print",在解压缩时,串表可以根据压缩数据重新生成。
3.在详细介绍算法之前,先列出一些与该算法相关的概念和词汇
1)'Character': 字符,一种基础数据元素,在普通文本文件中,它占用1个单独的byte,而在图像中,它却是 一种代表给定像素颜色的索引值。
2)'CharStream':数据文件中的字符流。
3)'Prefix':前缀。如这个单词的含义一样,代表着在一个字符最直接的前一个字符。一个前缀字符长度可以为0,一个prefix和一个character可以组成一个字符串(string),
4)'Suffix': 后缀,是一个字符,一个字符串可以由(A,B)来组成,A是前缀,B是后缀,当A长度为0的时候,代表Root,根
5)'Code:码,用于代表一个字符串的位置编码
6)'Entry',一个Code和它所代表的字符串(string)
4.压缩算法的简单示例,不是完全实现LZW算法,只是从最直观的角度看lzw算法的思想
对原始数据ABCCAABCDDAACCDB进行LZW压缩
原始数据中,只包括4个字符(Character),A,B,C,D,四个字符可以用一个2bit的数表示,0-A,1-B,2-C,3-D,从最直观的角度看,原始字符串存在重复字符:ABCCAABCDDAACCDB,用4代表AB,5代表CC,上面的字符串可以替代表示为:45A4CDDAA5DB,这样是不是就比原数据短了一些呢!
5.LZW算法的适用范围
为了区别代表串的值(Code)和原来的单个的数据值(String),需要使它们的数值域不重合,上面用0-3来代表A-D,那么AB就必须用大于3的数值来代替,再举另外一个例子,原来的数值范围可以用8bit来表示,那么就认为原始的数的范围是0~255,压缩程序生成的标号的范围就不能为0~255(如果是0-255,就重复了)。只能从256开始,但是这样一来就超过了8位的表示范围了,所以必须要扩展数据的位数,至少扩展一位,但是这样不是增加了1个字符占用的空间了么?但是却可以用一个字符代表几个字符,比如原来255是8bit,但是现在用256来表示254,255两个数,还是划得来的。从这个原理可以看出LZW算法的适用范围是原始数据串最好是有大量的子串多次重复出现,重复的越多,压缩效果越好。反之则越差,可能真的不减反增了。
6.LZW算法中特殊标记
随着新的串(string)不断被发现,标号也会不断地增长,如果原数据过大,生成的标号集(string table)会越来越大,这时候操作这个集合就会产生效率问题。如何避免这个问题呢?Gif在采用lzw算法的做法是当标号集足够大的时候,就不能增大了,干脆从头开始再来,在这个位置要插入一个标号,就是清除标志CLEAR,表示从这里我重新开始构造字典,以前的所有标记作废,开始使用新的标记。
这时候又有一个问题出现,足够大是多大?这个标号集的大小为比较合适呢?理论上是标号集大小越大,则压缩比率就越高,但开销也越高。 一般根据处理速度和内存空间连个因素来选定。GIF规范规定的是12位,超过12位的表达范围就推倒重来,并且GIF为了提高压缩率,采用的是变长的字长。比如说原始数据是8位,那么一开始,先加上一位再说,开始的字长就成了9位,然后开始加标号,当标号加到512时,也就是超过9为所能表达的最大数据时,也就意味着后面的标号要用10位字长才能表示了,那么从这里开始,后面的字长就是10位了。依此类推,到了2^12也就是4096时,在这里插一个清除标志,从后面开始,从9位再来。
GIF规定的清除标志CLEAR的数值是原始数据字长表示的最大值加1,如果原始数据字长是8,那么清除标志就是256,如果原始数据字长为4那么就是16。另外GIF还规定了一个结束标志END,它的值是清除标志CLEAR再加1。由于GIF规定的位数有1位(单色图),4位(16色)和8位(256色),而1位的情况下如果只扩展1位,只能表示4种状态,那么加上一个清除标志和结束标志就用完了,所以1位的情况下就必须扩充到3位。其它两种情况初始的字长就为5位和9位。此处参照了http://blog.csdn.net/whycadi/
7.用lzw算法压缩原始数据的示例分析
输入流,也就是原始的数据为:255,24,54,255,24,255,255,24,5,123,45,255,24,5,24,54..................
这个正好可以看到是gif文件中像素数组的一部分,如何对它进行压缩
因为原始数据可以用8bit来表示,故清除标志Clear=255+1 =256,结束标志为End=256+1=257,目前标号集为
0 1 2 3 .................................................................................255 CLEAR END
第一步,读取第一个字符为255,在标记表里面查找,255已经存在,我们已经认识255了,不做处理
第二步,取第二个字符,此时前缀为A,形成当前的Entry为(255,24),在标记集合不存在,我们并不认识255,24好,这次你小子来了,我就记住你,把它在标记集合中标记为258,然后输出前缀A,保留后缀24,并作为下一次的前缀(后缀变前缀)
第三步,取第三个字符为54,当前Entry(24,54),不认识,记录(24,54)为标号259,并输出24,后缀变前缀
第四部:取第四个字符255,Entry=(54,255),不认识,记录(54,255)为标号260,输出54,后缀变前缀
第五步 取第5个字符24,entry=(255,24),啊,认识你,这不是老258么,于是把字符串规约为258,并作为前缀
第六步 取第六个字符255,entry=(258,255),不认识,记录(258,255)为261,输出258,后缀变前缀
.......
一直处理到最后一个字符,
用一个表记录处理过程
CLEAR=256,END=257
第几步 前缀 后缀 Entry 认识(Y/N) 输出 标号
1
255 (,255)
2 255 24 (255,24) N 255 258
3 24 54 (24,54) N 24 259
4 54 255 (54,255) N 54 260
5 255 24 (255,24) Y
6 258 255 (258,255) N 258 261
7 255 255 (255,255) N 255 262
.....
上面这个示例有些不能完整体现,另外一个例子是
原输入数据为:A B A B A B A B B B A B A B A A C D A C D A D C A B A A A B A B .....
采用LZW算法对其进行压缩,压缩过程用一个表来表述为:
注意原数据中只包含4个character,A,B,C,D
用两bit即可表述,根据lzw算法,首先扩展一位变为3为,Clear=2的2次方+1=4; End=4+1=5;
初始标号集因该为
0 1 2 3 4 5
A B C D Clear End
而压缩过程为:
第几步 前缀 后缀 Entry 认识(Y/N) 输出 标号
1
A (,A)
2 A B (A,B) N A 6
3 B A (B,A) N B 7
4 A B (A,B) Y
5 6 A (6,A) N 6 8
6 A B (A,B) Y
7 6 A (6,A) Y
8 8 B (8,B) N 8 9
9 B B (B,B) N B 10
10 B B (B,B) Y
11 10 A (10,A) N 10 11
12 A B (A,B) Y
.....
当进行到第12步的时候,标号集应该为
0 1 2 3 4 5 6 7 8 9 10 11
A B C D Clear End AB BA 6A 8B BB 10A
8.LZW算法的伪代码实现
1STRING =
get input character
2WHILE there are still input characters DO
3 CHARACTER =
get input character
4 IF STRING+CHARACTER is
in the string table then
5 STRING = STRING+character
6 ELSE
7 output the code for STRING
8 add STRING+CHARACTER to the string table
9 STRING = CHARACTER
10 END of IF
11END of WHILE
12output the code for STRING
13
9.LZW算法的流程图
没有安visio,画了一个,比较难看,
原文地址:http://www.cnblogs.com/jillzhang/archive/2006/11/06/551298.html