Java编程十大典型问题详解(1)转
http://java.chinaitlab.com/base/735512_1.html
第1条 忘记对变量进行初始化
说明:忘记对成员变量进行初始化,或者是没有充分考虑初始化的顺序,是在实现过程当中经常发生的一类Bug.在Java中,如果忘记对局部变量进行初始化,会发生编译错误。因此很多人认为不可能发生初始化的遗漏。但是,如果忘记对成员变量进行初始化是不会导致编译错误的。将会被默认值初始化。其结果是,如果变量是引用型(类或者数组型)的而忘记初始化,就会在运行时发生NullPointerException错误。
//举例
对成员变量来说,要特别注意应该在声明变量时初始化,或者利用构造器来进行初始化。初始化的时机主要依照以下原则。
● 在所有的对象中用相同的值进行初始化。 → 声明变量时初始化
● 在每一个对象中进行初始化。 → 用构造器进行初始化
为了防止下面例子里的情况,一定要有这样的意识,即变量引用是有可能为NULL的。详细请参考本书第2条。
参考:Java的引用型变量类似于C语言的指针。变量本身就包含了对象的引用信息。
//举例
补充:对象初始化的顺序
在生成对象的时候,按照如下顺序实现初始化。如果脑子经常能想着这个初始化的顺序,
那么就很有可能让与初始化有关的问题防患于未然。所以一定要认真地理解掌握。
生成对象时的初始化顺序如下
①超类的成员变量(注1,注2)
②超类的构造器本身(注1)
③当前类的成员变量(注2)
④当前类的构造器本身
注1: ① ②仅适用于有超类的情况
注2:当没有明确的初始值时用缺省值初始化
要点:
1 超类一定要在当前类之前初始化
2 成员变量的初始化优先于构造器初始化
举例说明

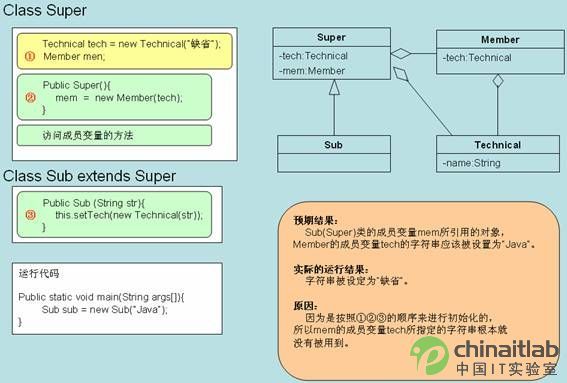
下面介绍一个实际发生过的问题 《因为初始化顺序造成问题的案例》
在下面这段程序中,超类的成员变量已经在声明时初始化,在其子类的构造器中又做了一次初始化。因为成员变量间是有依赖关系的,所以发生了预想之外的问题。
第2条 方法调用时没有对I/F制约进行检查
说明:所谓I/F制约是指,方法为了提供特定的功能,对输入所期望的条件。
在调用方法时传入的参数值是否妥当?
在方法内部调用其他方法时,其返回值是否妥当?
如果不对这些值进行检查,就会导致Bug的产生。
如果是调用方法时的参数,那就一定要检查,参数的值是否在想定的范围之内,或者引用的对象会不会是null.
为了构筑健壮的系统,不能只考虑正常的输入情况,还必须实现对异常输入的响应。
那么,当输入没有满足I/F制约时,我们该怎么办呢?当输入没有满足I/F制约,发生了异常,那么这个异常是交给调用方去处理呢,还是在当前的方法里处理,这是一个设计的问题。有兴趣的读者可以去参阅参考文献。
另外,关于异常的详细情况,也希望参照该文章第5条。
例子:给HashMap赋值的add方法中的检查逻辑
最后,面向某方法的输入不仅仅指这个方法的参数和这个方法调用其他方法时的返回值。方法中引用的实例变量,还有类变量都有可能成为方法的输入,也是需要检查的。
补充说明:
在考虑I/F制约的时候,必须了解以下的两种区别。
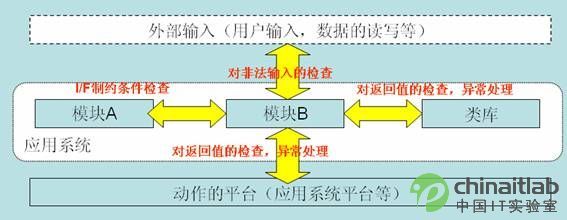
1. 产品交付后仍然可能需要检查的条件
本页下面的图中所显示的,来自于功能模块以外的输入情况。对运行时的异常输入必须加以检查。另外,从模块的复用来看,即使现在的模块构成中不可能发生的输入情况,将来也是有可能发生的。头脑中最好建立起这样的意识,从而主动地进行检查。
2. 为了使调试更加方便而希望检查的条件
可以使用从J2SE1.4开始提供的assert命令。Assert是从1.4版开始提供支持的,assert异常时产生 AssertionError,强制停止程序运行,因此为调试提供了便利。但是,这里要注意,这种情况下不能对上面1所说的,也就是产品交付后也有可能需要检查的那些制约条件进行检查。Assert是用于调试的,产品交付时,Assert检查会被省略。
基于相同的理由,assert命令里一定不能包含可能产生副作用(#)的逻辑或公式。
#指可能使运行环境状态发生变化的作用。有代表的例子是变量的值发生变化,或是文件读写等。
第3条 忘记对资源进行分配和释放
【IT专家网独家】说明:所谓资源是指CPU,内存,文件等系统资源。系统资源是有限的,并且会被多个过程所调用。因此,在调用资源之前,第一件事情是必须分配资源。而对已经分配的资源,如果使用之后不加以释放,势必造成资源泄漏,直接导致深度Bug,性能问题,所以必须加以充分的注意。
经常发生的一件事是,在进行文件操作时,打开的文件必须及时关闭。无论是二进制流还是字符流,一旦在生成流时被打开,直到Close方法被调用之前,流所使用的资源都处于被占用的状态。所以,当资源已经不需要时,一定不要忘记调用Close方法。对于打开的文件,在finally中调用 close方法,可以确保在发生异常时被关闭。
另外,不仅仅是针对文件,应该保持这样的警惕,即对有效资源(可能被共用)不可以长期占用。比如说下页中举的例子,数据库资源 (java.sql.Connection,java.sql.Statement等)是典型的必须避免占用的资源。因此而引起的问题是经常发生的。
例子 ① 可能发生DB资源泄露的典型代码
例子 ② 用finally确实关闭DB资源
同①背景相同的代码
补充说明:通过垃圾回收机制释放对象
Java语言中有垃圾回收机制,在Java的Heap上分配的对象,一般来说是不需要显式
地释放的。但是,被释放的资源仅是垃圾回收处理中被判断为“程序已经不使用”的部分。
详细内容可以参考该文章的补充5。
第4条 在分支处理时遗漏条件
说明:在if或者switch等控制命令中,把应该考虑到的条件遗漏掉,是比较典型的Bug。特别是,某些类型的条件遗漏,在以正常系为核心的测试中往往很难发现,却非常可能在产品交付后发现是致命的Bug,所以需要特别加以留意。
为了不遗漏条件,必须注意以下2点:
1. 编写正确的条件式
为了“写出正确的条件式”,需要通过条件式的变换来验证写出的条件式是否表达了我们本来的意图(参考补充说明)。
在此基础上,如果构成条件的表达式非常复杂,就需要使用真值表对条件式构成及关系进行整理(参考补充说明表)。
2. 没有遗漏地编写条件
为了“没有遗漏地编写条件”,下面几点非常重要:
① 设计时进行充分的讨论(这点最为重要)。
② 实现时,特别注意与if相应的else有没有,与switch相应的default分支是否存在。如果没有,则需要明确理论,明确没有的理由。
参考:检查编写的理论表达式是否覆盖了所有条件的方法
把条件翻转过来考虑就可以了。比如说,“ A || B || C”这样一个条件,就考虑翻转之后的”(!A)&&(!B)&&(!C)”。
如果能够找到满足这个翻转后条件的输入,则说明还没有覆盖所有的条件。
例:没有能够覆盖所有条件的情况
补充说明:使表达式更容易理解的方法 以及 返回真假值方法的注意点
在编写表达式时同时编写多个表达式,从中选择一个最容易理解的即可。
有些条件是可以用多个表达式来编写的。例如下面这两个表达式是等价的。
① if (x != 1 || x != 2)
② if (! (x == 1 && x == 2))
对于①来说,很难一眼就断定是个Bug。但是, ②呢,一眼就可以看出来“x 等于 1,并且等于2”是个Bug。
下面,设想一下返回真假值的情况。这时,如果做一个方法,当P为真时返回一个假的话,就成了“没有不是P的情况”的二重否定,很容易导致解释时的混乱。因此,即使想要检查的条件是P的否定,也最好先写一个判定P的方法,在调用的时候用“if (! isActive())…”这样的否定形来判断。
利用真值表来整理各种条件及其取值
条件表达式 C: ( x > 0 ) && (( y < z ) || !( z == x))
X > 0Y < ZZ == X评价值
TTTT
TTFT
TFTF
TFFT
FTTF
FTFF
FFTF
FFFF
注:图中的记号
T … 真
F … 假
针对整数x,y,z,有三个命题(x > 0,y < z,z == x),满足条件式C的是本真值表中评价值为真的那些行。通过判断评价值为真的行各命题的真伪,就可以按三个命题被分解的形式确认条件式C是否表达了我们的的意图。 另外,为了编写else if 或者 else语句,从而避免条件遗漏时,只要针对评价值为假的行编写条件表达式即可。
参考:布尔操作符 && ,|| 的右边不允许包含有带有副作用(#)的表达式
&&,||是布尔操作符,右边的操作数并不一定每次都被判断
① x && y 的情况,当x为false时,y将不被判断
② x || y 的情况,当x为true时,y将不被判断
因此,对y(右侧操作数)有副作用的表达式是不允许包含的。
# 使运行环境发生变化的作用。有代表性的例子是变量值的变化,文件读写等。
第5条 对异常处理不当
说明:所谓异常,就是在程序执行中发生的异常状态(参照JISX0007)。作为一种语言的机制,Java提供了异常处理,程序员可以比较容易,并且显式地对异常进行表述。
但是,就算是Java提供了这种优异的机制,如果不能正确地运用就没有任何意义。经常发生的错误有如下几种情况。
• 异常交给上一层类了,但是异常的详细内容却被隐藏了。IOException,SQLException等异常只被上一层的Error,Throwable,Exception接收,但是错误的详细内容却被隐藏了。
• Catch中是空的(未作任何处理)。
为了不要发生这样的对异常的不当处理,需要使catch到的异常都能交给与该异常相应的类去处理。超类是不能处理catch块中的异常种类的。另外,不允许用空的catch块来处理异常。必须编写适当的异常处理,以便了解异常是如何发生的。
例:读入文件时的异常处理
修正例:
作为对异常的处理,有各种各样的方法,比如把发生状况写入Log文并且终止程序,或者对可以预知的异常进行明确的复原处理等等。详细情况请参阅参考文献。
补充说明: 异常类的分类
异常类以Throwable为基类按如下方式分类。在实现代码内如果不加以捕捉就会导致编译错误的异常是Exception类的子类(但是不包括RuntimeException类的子类)。
① Error类的子类
无法处理,或者不应该处理的异常
• Java.laERROR.OutOfMemoryError //内存不足
• Java.laERROR.StackOverflowError //StackOverflow
② Exception类的子类RuntimeException的子类以外的子类
• Java.io.IOException //输入输出错误
• Java.io.FileNotFoundException //找不到文件(IOException的子类)
• Java.sql.SQLException //DB访问异常
③ RuntimeException类的子类
在程序运行中到处都有可能发生,由程序员的错误造成的异常。或者,在设计时没有考虑到的情况下发生的异常。
• Java.laERROR.ArithmeticException //整数运算时用0做除数
• Java.laERROR.ArrayIndexOutOfBoundsException //数组下标错误
• Java.laERROR.IllegalArgumentException //参数值错误
• Java.laERROR.NullPointerException //访问空指针错误
第6条 命名应该统一
说明:指对编码中出现的名字进行命名。难懂的代码,显然也很难分析和改造。因此而造成单纯错误的几率大增,调试也极费时间。代码变得难懂,其中一个重要原因就是变量名和方法名不好懂。比如,堆砌一些没有任何涵义的符号或者其含义和名字不一致自不必说,就算是英语的拼写错了,也会使代码变得难懂,更容易发生误解。
仅仅是把命名进行统一,就可以大大提高代码的可读性。通过使用简明易懂的名字,不仅仅是使别人的代码可读性提高,就是自己的代码,回过头来读的时候,各种变量,方法的作用极其明确,可以很容易地把握处理的内容。从而大大提高代码的可维护性,大大提高生产性。
修正例:
在Java语言中,Sun的命名规约已经浸透到开发的所有领域,各种类库以及支持工具大多是以Sun的命名规约作为前提的。建议尽可能地遵从Sun的命名规约。
补充说明 在命名中应该规定的项目
为了统一命名,建议将下列项目作为命名规约的内容。另外,命名规约一定要好用,容易遵守。
• 对命名的全面的指针
• 文件名(含目录名)的命名规则
• 包,类,方法,变量,常量的命名规则 等。
对命名的全面指针是指
• 大小写的使用,以及标记的统一
• 禁止记号和序号的简单罗列,要求所有名字都有明确含义
• 不使用省略形式
• 作用不同则名字不同
• 成员变量和局部变量不使用相同的名称等等。代表性的命名规约请参阅参考文献。
Sun推荐的命名规约(概要)
• 包名必须都是小写字
com.sun.eERROR; com.apple.quicktime.v2
• 类/接口名必须是名词,各单词的第一个字是大写
class Raster; class ImageSprite;
• 方法名必须是动词,第一个字是小写字,但后面的单词的第一个字是大写
run(); runFast(); getBackground();
• 变量的第一个字是小写字,但后面的单词的第一个字是大写
char c; float myWidth;
• 常量用大写字,各单词之间用下杠“_”分隔
static final int MIN_WIDTH = 4;
static final int MAX_WIDTH = 999:
第1条 忘记对变量进行初始化
说明:忘记对成员变量进行初始化,或者是没有充分考虑初始化的顺序,是在实现过程当中经常发生的一类Bug.在Java中,如果忘记对局部变量进行初始化,会发生编译错误。因此很多人认为不可能发生初始化的遗漏。但是,如果忘记对成员变量进行初始化是不会导致编译错误的。将会被默认值初始化。其结果是,如果变量是引用型(类或者数组型)的而忘记初始化,就会在运行时发生NullPointerException错误。
//举例
Class Employee{
private StriERROR name;
public void someMethod(){
StriERROR sutoVar;
autoVar += “abc”; //局部变量:没有初始化的时会发生编译错误
this.name.toStriERROR(); //成员变量:即使没有初始化也不会发生编译错误。//但是运行时会发生NullPointerException错误
对成员变量来说,要特别注意应该在声明变量时初始化,或者利用构造器来进行初始化。初始化的时机主要依照以下原则。
● 在所有的对象中用相同的值进行初始化。 → 声明变量时初始化
● 在每一个对象中进行初始化。 → 用构造器进行初始化
为了防止下面例子里的情况,一定要有这样的意识,即变量引用是有可能为NULL的。详细请参考本书第2条。
参考:Java的引用型变量类似于C语言的指针。变量本身就包含了对象的引用信息。
//举例
Class Shokika1{
private StriERROR name = “缺省太郎”; //OK:在声明同时初始化
public void setName(StriERROR str){ this.name = str; }
}
Public class Shokika2{
private Shokika1 shokika1; //OK:初始值由构造器设定(即用缺省值//NULL来初始化)
private Shokika2(StriERROR str){ //ERROR:忘记用构造器初始化。初始化的正确
//代码例:shokika1 = new Shokika1(); shokika1.setName(str);
}
public void print(){
System.out.println(shokika1.getName());
//ERROR:↑Shokika1对象的初始化被忘记
//了,所以这里是null,所以访问getName方法就会发生异常
}
public static void main(StriERROR[] args){
Shokika2 shokika2 = new Shokika2(“StriERROR”);
shokika2.print();
}
}
//运行结果 Exception in thread “main” java.laERROR.NullPointerException
补充:对象初始化的顺序
在生成对象的时候,按照如下顺序实现初始化。如果脑子经常能想着这个初始化的顺序,
那么就很有可能让与初始化有关的问题防患于未然。所以一定要认真地理解掌握。
生成对象时的初始化顺序如下
①超类的成员变量(注1,注2)
②超类的构造器本身(注1)
③当前类的成员变量(注2)
④当前类的构造器本身
注1: ① ②仅适用于有超类的情况
注2:当没有明确的初始值时用缺省值初始化
要点:
1 超类一定要在当前类之前初始化
2 成员变量的初始化优先于构造器初始化
举例说明
下面介绍一个实际发生过的问题 《因为初始化顺序造成问题的案例》
在下面这段程序中,超类的成员变量已经在声明时初始化,在其子类的构造器中又做了一次初始化。因为成员变量间是有依赖关系的,所以发生了预想之外的问题。
第2条 方法调用时没有对I/F制约进行检查
说明:所谓I/F制约是指,方法为了提供特定的功能,对输入所期望的条件。
在调用方法时传入的参数值是否妥当?
在方法内部调用其他方法时,其返回值是否妥当?
如果不对这些值进行检查,就会导致Bug的产生。
如果是调用方法时的参数,那就一定要检查,参数的值是否在想定的范围之内,或者引用的对象会不会是null.
为了构筑健壮的系统,不能只考虑正常的输入情况,还必须实现对异常输入的响应。
那么,当输入没有满足I/F制约时,我们该怎么办呢?当输入没有满足I/F制约,发生了异常,那么这个异常是交给调用方去处理呢,还是在当前的方法里处理,这是一个设计的问题。有兴趣的读者可以去参阅参考文献。
另外,关于异常的详细情况,也希望参照该文章第5条。
例子:给HashMap赋值的add方法中的检查逻辑
Public class ScoreBook {
pulic static final int MAX = 100;
private HashMap<StriERROR, Integer> scoreBook;
public ScoreBook(){
scoreBook = new HshMap<StriERROR, Integer>();
}
//add方法:将参数name和score赋值给HashMap;IIIegaIInputException,
//AleadyAddedException是用户定义异常。
public void add(StriERROR name, int score) throws IIIegaIInputException,
AleradyAddedException{
//预期条件1:参数name满足name != null
//预期条件2:参数name不是空字符串 →检查上述条件是否满足,如果不满足,则
//抛出异常交给调用方处理
if (name == null || name.trim().equals(“”)){
throw new IIIegaIInputException(“姓名输入错误”);
}
//预期条件3:参数score满足0 <= score <= MAX →检查条件是否满足,如果不满
//足,则抛出异常交给调用方处理
if (!(0 <= score && score < MAX)){
throw new IIIegaIInputException(“分数输入错误”);
}
//预期条件4:参数name不能2重登录 →检查上述条件是否满足,如果不满足,则
//抛出异常交给调用方处理
if (scoreBook.containsKey(name){
throw new AoreadyAddedException(“输入值已经登录过了”);
}
scoreBook.put(name,score);
}
}
最后,面向某方法的输入不仅仅指这个方法的参数和这个方法调用其他方法时的返回值。方法中引用的实例变量,还有类变量都有可能成为方法的输入,也是需要检查的。
补充说明:
在考虑I/F制约的时候,必须了解以下的两种区别。
1. 产品交付后仍然可能需要检查的条件
本页下面的图中所显示的,来自于功能模块以外的输入情况。对运行时的异常输入必须加以检查。另外,从模块的复用来看,即使现在的模块构成中不可能发生的输入情况,将来也是有可能发生的。头脑中最好建立起这样的意识,从而主动地进行检查。
2. 为了使调试更加方便而希望检查的条件
可以使用从J2SE1.4开始提供的assert命令。Assert是从1.4版开始提供支持的,assert异常时产生 AssertionError,强制停止程序运行,因此为调试提供了便利。但是,这里要注意,这种情况下不能对上面1所说的,也就是产品交付后也有可能需要检查的那些制约条件进行检查。Assert是用于调试的,产品交付时,Assert检查会被省略。
基于相同的理由,assert命令里一定不能包含可能产生副作用(#)的逻辑或公式。
#指可能使运行环境状态发生变化的作用。有代表的例子是变量的值发生变化,或是文件读写等。
第3条 忘记对资源进行分配和释放
【IT专家网独家】说明:所谓资源是指CPU,内存,文件等系统资源。系统资源是有限的,并且会被多个过程所调用。因此,在调用资源之前,第一件事情是必须分配资源。而对已经分配的资源,如果使用之后不加以释放,势必造成资源泄漏,直接导致深度Bug,性能问题,所以必须加以充分的注意。
经常发生的一件事是,在进行文件操作时,打开的文件必须及时关闭。无论是二进制流还是字符流,一旦在生成流时被打开,直到Close方法被调用之前,流所使用的资源都处于被占用的状态。所以,当资源已经不需要时,一定不要忘记调用Close方法。对于打开的文件,在finally中调用 close方法,可以确保在发生异常时被关闭。
另外,不仅仅是针对文件,应该保持这样的警惕,即对有效资源(可能被共用)不可以长期占用。比如说下页中举的例子,数据库资源 (java.sql.Connection,java.sql.Statement等)是典型的必须避免占用的资源。因此而引起的问题是经常发生的。
例子 ① 可能发生DB资源泄露的典型代码
…
Connection con = null;
PreparedStatement ps = null;
Try{
Class.forName(“指定DB驱动”); //Load DB DriverManager
con = Drivermanager.getConnection(“DB URL”);
ps = con.prepareStatement(运行用SQL“);
// 某种处理
ps.close(); //ERROR: 处理到这里之前如果发生异常,将无法关闭
con.close(); // ERROR: 处理到这里之前如果发生异常,将无法关闭
}catch(ClassNotFoundException e1){
e1.printStackTrace();
}catch(SQLException e2){
e2.printStackTrace();
}
例子 ② 用finally确实关闭DB资源
同①背景相同的代码
//某种处理
}catch(ClassNotFoundException e1){
e1.printStackTrace();
}catch(SQLException e2){
e2.printStackTrace();
}finally{
if( ps != null ){
try{
ps.close(); //OK:即使在处理中发生异常也可以保证关闭。
}catch(SQLException e3){
e3.printStackTrace();
}
if( con != null){
try{
con.close(); //OK:即使在处理中发生异常也可以保证关闭。
}catch(SQLException e4){
e4.printStackTrace();
}
}
}
补充说明:通过垃圾回收机制释放对象
Java语言中有垃圾回收机制,在Java的Heap上分配的对象,一般来说是不需要显式
地释放的。但是,被释放的资源仅是垃圾回收处理中被判断为“程序已经不使用”的部分。
详细内容可以参考该文章的补充5。
第4条 在分支处理时遗漏条件
说明:在if或者switch等控制命令中,把应该考虑到的条件遗漏掉,是比较典型的Bug。特别是,某些类型的条件遗漏,在以正常系为核心的测试中往往很难发现,却非常可能在产品交付后发现是致命的Bug,所以需要特别加以留意。
为了不遗漏条件,必须注意以下2点:
1. 编写正确的条件式
为了“写出正确的条件式”,需要通过条件式的变换来验证写出的条件式是否表达了我们本来的意图(参考补充说明)。
在此基础上,如果构成条件的表达式非常复杂,就需要使用真值表对条件式构成及关系进行整理(参考补充说明表)。
2. 没有遗漏地编写条件
为了“没有遗漏地编写条件”,下面几点非常重要:
① 设计时进行充分的讨论(这点最为重要)。
② 实现时,特别注意与if相应的else有没有,与switch相应的default分支是否存在。如果没有,则需要明确理论,明确没有的理由。
参考:检查编写的理论表达式是否覆盖了所有条件的方法
把条件翻转过来考虑就可以了。比如说,“ A || B || C”这样一个条件,就考虑翻转之后的”(!A)&&(!B)&&(!C)”。
如果能够找到满足这个翻转后条件的输入,则说明还没有覆盖所有的条件。
例:没有能够覆盖所有条件的情况
switch (status) {
case STATUS_INIT;
…
break;
…
// ERROR: 没有记述default的情况
} // 究竟是忘了写呢,还是根本不会发生default的情况呢?这里无法判断
…
If ( variable < constantVar2) {
…
} else if (variable < constantVar3) {
…
} // ERROR:没有相应的else
// 究竟是忘了写呢,还是根本不会发生else的情况呢?这里无法判断
补充说明:使表达式更容易理解的方法 以及 返回真假值方法的注意点
在编写表达式时同时编写多个表达式,从中选择一个最容易理解的即可。
有些条件是可以用多个表达式来编写的。例如下面这两个表达式是等价的。
① if (x != 1 || x != 2)
② if (! (x == 1 && x == 2))
对于①来说,很难一眼就断定是个Bug。但是, ②呢,一眼就可以看出来“x 等于 1,并且等于2”是个Bug。
下面,设想一下返回真假值的情况。这时,如果做一个方法,当P为真时返回一个假的话,就成了“没有不是P的情况”的二重否定,很容易导致解释时的混乱。因此,即使想要检查的条件是P的否定,也最好先写一个判定P的方法,在调用的时候用“if (! isActive())…”这样的否定形来判断。
利用真值表来整理各种条件及其取值
条件表达式 C: ( x > 0 ) && (( y < z ) || !( z == x))
X > 0Y < ZZ == X评价值
TTTT
TTFT
TFTF
TFFT
FTTF
FTFF
FFTF
FFFF
注:图中的记号
T … 真
F … 假
针对整数x,y,z,有三个命题(x > 0,y < z,z == x),满足条件式C的是本真值表中评价值为真的那些行。通过判断评价值为真的行各命题的真伪,就可以按三个命题被分解的形式确认条件式C是否表达了我们的的意图。 另外,为了编写else if 或者 else语句,从而避免条件遗漏时,只要针对评价值为假的行编写条件表达式即可。
参考:布尔操作符 && ,|| 的右边不允许包含有带有副作用(#)的表达式
&&,||是布尔操作符,右边的操作数并不一定每次都被判断
① x && y 的情况,当x为false时,y将不被判断
② x || y 的情况,当x为true时,y将不被判断
因此,对y(右侧操作数)有副作用的表达式是不允许包含的。
# 使运行环境发生变化的作用。有代表性的例子是变量值的变化,文件读写等。
第5条 对异常处理不当
说明:所谓异常,就是在程序执行中发生的异常状态(参照JISX0007)。作为一种语言的机制,Java提供了异常处理,程序员可以比较容易,并且显式地对异常进行表述。
但是,就算是Java提供了这种优异的机制,如果不能正确地运用就没有任何意义。经常发生的错误有如下几种情况。
• 异常交给上一层类了,但是异常的详细内容却被隐藏了。IOException,SQLException等异常只被上一层的Error,Throwable,Exception接收,但是错误的详细内容却被隐藏了。
• Catch中是空的(未作任何处理)。
为了不要发生这样的对异常的不当处理,需要使catch到的异常都能交给与该异常相应的类去处理。超类是不能处理catch块中的异常种类的。另外,不允许用空的catch块来处理异常。必须编写适当的异常处理,以便了解异常是如何发生的。
例:读入文件时的异常处理
try {
reader = new BufferedReader( new FileReader(file));
reader.read();
} catch (Throwable t) { // ERROR: 错误的详细信息被隐藏了
// 记述错误处理
} finally{
try{
reader.close();
} catch(IOException ioe) { //ERROR: catch块中什么也没写
}
}
修正例:
try {
reader = new BufferedReader( new FileReader(file));
reader.read();
} catch (FileNotFoundExceptionfnfe) { // OK: catch了想定的异常
// 记述错误处理
} catch (IOException ioe1) { // OK: catch了想定的异常
// 记述错误处理
} finally{
try{
reader.close();
} catch(IOException ioe) {
// 记述错误处理 // OK:写了异常处理
}
}
作为对异常的处理,有各种各样的方法,比如把发生状况写入Log文并且终止程序,或者对可以预知的异常进行明确的复原处理等等。详细情况请参阅参考文献。
补充说明: 异常类的分类
异常类以Throwable为基类按如下方式分类。在实现代码内如果不加以捕捉就会导致编译错误的异常是Exception类的子类(但是不包括RuntimeException类的子类)。
① Error类的子类
无法处理,或者不应该处理的异常
• Java.laERROR.OutOfMemoryError //内存不足
• Java.laERROR.StackOverflowError //StackOverflow
② Exception类的子类RuntimeException的子类以外的子类
• Java.io.IOException //输入输出错误
• Java.io.FileNotFoundException //找不到文件(IOException的子类)
• Java.sql.SQLException //DB访问异常
③ RuntimeException类的子类
在程序运行中到处都有可能发生,由程序员的错误造成的异常。或者,在设计时没有考虑到的情况下发生的异常。
• Java.laERROR.ArithmeticException //整数运算时用0做除数
• Java.laERROR.ArrayIndexOutOfBoundsException //数组下标错误
• Java.laERROR.IllegalArgumentException //参数值错误
• Java.laERROR.NullPointerException //访问空指针错误
第6条 命名应该统一
说明:指对编码中出现的名字进行命名。难懂的代码,显然也很难分析和改造。因此而造成单纯错误的几率大增,调试也极费时间。代码变得难懂,其中一个重要原因就是变量名和方法名不好懂。比如,堆砌一些没有任何涵义的符号或者其含义和名字不一致自不必说,就算是英语的拼写错了,也会使代码变得难懂,更容易发生误解。
仅仅是把命名进行统一,就可以大大提高代码的可读性。通过使用简明易懂的名字,不仅仅是使别人的代码可读性提高,就是自己的代码,回过头来读的时候,各种变量,方法的作用极其明确,可以很容易地把握处理的内容。从而大大提高代码的可维护性,大大提高生产性。
修正例:
Public static final int MAX = 10; //OK;
Public static final int min = 0; //ERROR:常量应该大写
Public void func(void) {
int a0001; //ERROR:符号罗列,含义不明
int priolity; //ERROR:英语拼写错误
int number; //OK;
int Number; //ERROR:大小写混杂,而且头文字为大写
…
}
在Java语言中,Sun的命名规约已经浸透到开发的所有领域,各种类库以及支持工具大多是以Sun的命名规约作为前提的。建议尽可能地遵从Sun的命名规约。
补充说明 在命名中应该规定的项目
为了统一命名,建议将下列项目作为命名规约的内容。另外,命名规约一定要好用,容易遵守。
• 对命名的全面的指针
• 文件名(含目录名)的命名规则
• 包,类,方法,变量,常量的命名规则 等。
对命名的全面指针是指
• 大小写的使用,以及标记的统一
• 禁止记号和序号的简单罗列,要求所有名字都有明确含义
• 不使用省略形式
• 作用不同则名字不同
• 成员变量和局部变量不使用相同的名称等等。代表性的命名规约请参阅参考文献。
Sun推荐的命名规约(概要)
• 包名必须都是小写字
com.sun.eERROR; com.apple.quicktime.v2
• 类/接口名必须是名词,各单词的第一个字是大写
class Raster; class ImageSprite;
• 方法名必须是动词,第一个字是小写字,但后面的单词的第一个字是大写
run(); runFast(); getBackground();
• 变量的第一个字是小写字,但后面的单词的第一个字是大写
char c; float myWidth;
• 常量用大写字,各单词之间用下杠“_”分隔
static final int MIN_WIDTH = 4;
static final int MAX_WIDTH = 999: