in 和 exists的区别 用数据说话
1、环境
操作系统:winxp系统 cpu:p8700 双核2.53 内存:2GB 数据库:oracle9i
2、表结构
drop table base_customer; create table base_customer ( uuid number(10) not null, customerId varchar(20), showName varchar(30), trueName varchar(30), image varchar(100), pwd varchar(50), registerTime timestamp, securityKey varchar(10), primary key (uuid), unique(customerId) ); create index idx_customer_registerTime on base_customer(registerTime); drop table base_customer_sign; create table base_customer_sign ( uuid number(10) not null, signCustomerUuid number(10) not null, signTime timestamp not null, signCount number(10) not null, signSequenceCount number(10) not null, primary key (uuid) ); create index idx_sign on base_customer_sign(signCustomerUuid);
3、索引及数据量
base_customer 100w条 uuid主键 customerId 唯一索引 base_customer_sign 100条 uuid主键 signCustomerUuid 非唯一索引
4、初始化数据用例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Timestamp;
import java.util.Date;
import oracle.jdbc.OracleDriver;
public class Test {
public static void main(String[] args) throws Exception {
initData();
}
public static void initData() throws Exception {
DriverManager.registerDriver(new OracleDriver());
Connection conn = null;
try {
String url = "jdbc:oracle:thin:@localhost:1521:orcl2";
String username = "test";
String password = "test";
conn = DriverManager.getConnection(url, username, password);
conn.setAutoCommit(false);
conn.createStatement().execute("truncate table base_customer");
PreparedStatement psst = conn.prepareStatement("insert into base_customer values(?,?,?,?,?,?,?,?)");
for(int i=1; i<=1000000;i++) {//100w
int count = 1;
psst.setInt(count++, i);
psst.setString(count++, "user" + i);
psst.setString(count++, "user" + i);
psst.setString(count++, "user" + i);
psst.setString(count++, "user" + i);
psst.setString(count++, "user" + i);
psst.setTimestamp(count++, new Timestamp(System.currentTimeMillis()));
psst.setString(count++, "key" + i);
psst.addBatch();
psst.executeBatch();
conn.commit();
}
PreparedStatement psst2 = conn.prepareStatement("insert into base_customer_sign values(?,?,?,?,?)");
for(int i=1; i<=0;i++) {//100
int count = 1;
psst2.setInt(count++, i);
psst2.setInt(count++, i);
psst2.setTimestamp(count++, new Timestamp(System.currentTimeMillis()));
psst2.setInt(count++, 1);
psst2.setInt(count++, 1);
psst2.addBatch();
psst2.executeBatch();
conn.commit();
}
psst.close();
conn.commit();
} catch (Exception e) {
e.printStackTrace();
conn.rollback();
} finally {
conn.close();
}
}
}
5、场景
5.1、第一组 内表大 外表小
用例1、
select count(*) from base_customer_sign where signCustomerUuid in (select uuid from base_customer where trueName like 'user%')
执行计划:
如图1-1
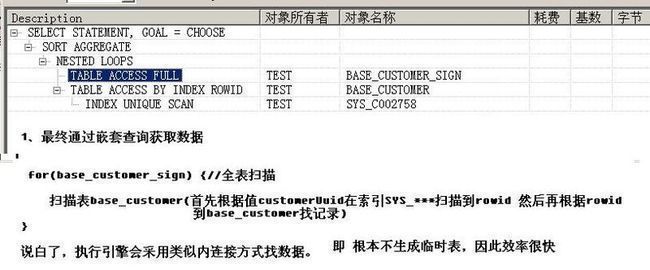
执行时间:
0.015秒
结论:数据库执行了优化,根本不是我们需要的用例。
用例2
select count(*) from base_customer_sign where signCustomerUuid in (select uuid from base_customer where trueName like 'user%' group by uuid)
执行计划:
如图1-2

执行时间:
28.672秒
结论:内表如果查询回来很多数据并要排序的话,效率很极低,因此内表适合返回数据量小的表,例外是用例1场景。
用例3
select count(*) from base_customer_sign where exists (select 1 from base_customer where trueName like 'user%' and base_customer.uuid = base_customer_sign.signCustomerUuid)
执行计划:
如图1-3
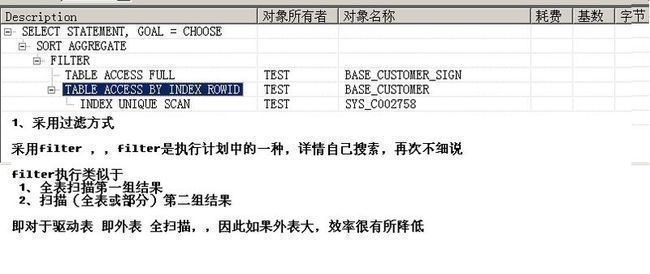
执行时间:
0.016秒
结论:外表执行全扫描,如果外表大很降低效率。
用例4
select count(*) from base_customer_sign where signCustomerUuid in (select uuid from base_customer where customerId like 'user%')
执行计划:
如图1-4
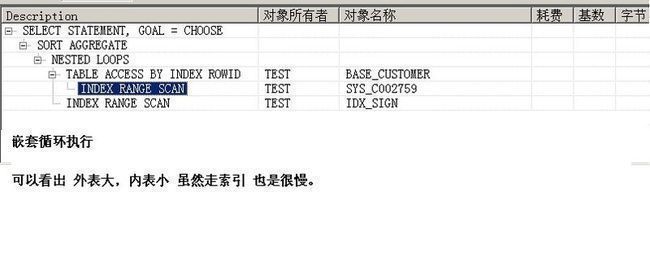
执行时间:
13.61秒
结论:即使内表很小,但外表数据量很大 同样是低效。
用例5
select count(*) from base_customer_sign where exists (select 1 from base_customer where base_customer.customerId like 'user%' and base_customer.uuid = base_customer_sign.signCustomerUuid)
执行计划:
如图1-5
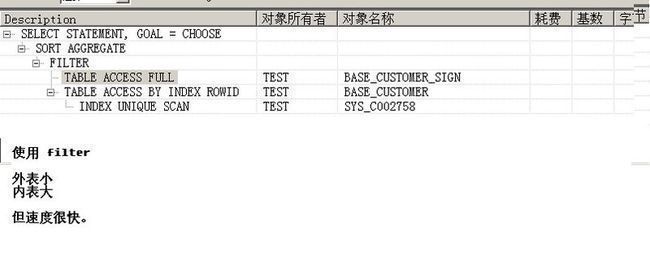
执行时间:
0.032秒
结论:内表大,外表小,速度快。
第二组 内表小 外表大
用例6
select * from base_customer where uuid in (select signCustomerUuid from base_customer_sign where trueName like 'user%')
执行计划:
如图1-6

执行时间:
3.844秒
结论:外表全扫描,慢。
用例7
select count(*) from base_customer where exists (select 1 from base_customer_sign where trueName like 'user%' and base_customer.uuid = base_customer_sign.signCustomerUuid)
执行计划:
如图1-7

执行时间:
3.828秒
结论:和用例6一样。
用例8
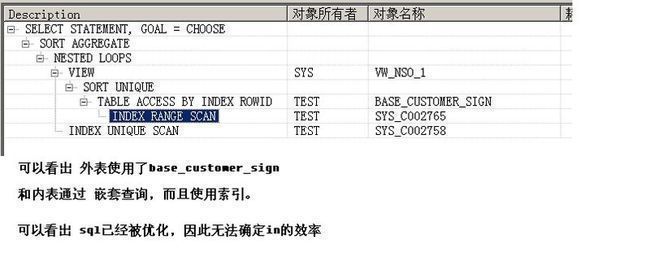
select count(*) from base_customer where uuid in (select signCustomerUuid from base_customer_sign where uuid>1 and signSequenceCount < 1)
执行计划:
如图1-8
执行时间:
0.031秒
结论:sql被优化,使用base_customer_sign作为外表,而且和内表是通过连接搞定,效率快。
用例9
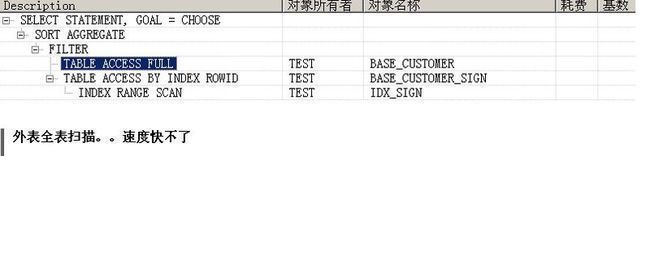
select count(*) from base_customer where exists (select 1 from base_customer_sign where base_customer_sign.uuid>1 and base_customer.uuid = base_customer_sign.signCustomerUuid)
执行计划:
如图1-9
执行时间:
3.531秒
结论:外表全表扫描快不了。
总结:
1、 in可能被优化为 连接
2、 in 在未被优化时,外表小,内表大时(要建临时表并排序 耗时) 效率低
3、 exists 外表数据量大,速度肯定慢,,即使是in同样一样,而对于内表数据量多少跟索引有关。
4、 in 和 exists 在外表返回的数据量很大时也是低效的。
因此,,外表(驱动表) 应该都尽可能的小。
5、 not in 不走索引的,因此不能用
6、 not exists走索引的。
自己总结,难免有纰漏 本人只测试以上9个简单的用例,复杂场景可能未考虑到,因此在调优时 应该会看执行计划,根据执行计划决定哪个是高效的。