Libsvm3.12版本使用以及二次开发
修改两个类:svm_predict,svm_train,前者是预测的,后者是训练的。
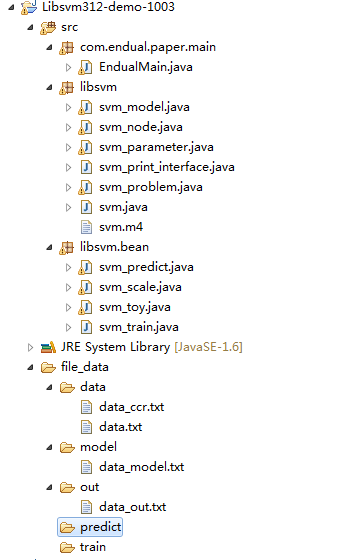
工程图示:
根据自己要做实验的数据,修改了一部分返回值的代码:
svm_predict.java进行修改为
package libsvm.bean;
import libsvm.*;
import java.io.*;
import java.util.*;
public class svm_predict {
private static int correctCount ;
private static int totalCount ;
public int getTotalCount() {
return totalCount;
}
public int getCorrectCount() {
return correctCount;
}
private static double atof(String s)
{
return Double.valueOf(s).doubleValue();
}
private static int atoi(String s)
{
return Integer.parseInt(s);
}
private static void predict(BufferedReader input, DataOutputStream output, svm_model model, int predict_probability) throws IOException
{
int correct = 0;
int total = 0;
double error = 0;
double sumv = 0, sumy = 0, sumvv = 0, sumyy = 0, sumvy = 0;
int svm_type=svm.svm_get_svm_type(model);
int nr_class=svm.svm_get_nr_class(model);
double[] prob_estimates=null;
if(predict_probability == 1)
{
if(svm_type == svm_parameter.EPSILON_SVR ||
svm_type == svm_parameter.NU_SVR)
{
System.out.print("Prob. model for test data: target value = predicted value + z,\nz: Laplace distribution e^(-|z|/sigma)/(2sigma),sigma="+svm.svm_get_svr_probability(model)+"\n");
}
else
{
int[] labels=new int[nr_class];
svm.svm_get_labels(model,labels);
prob_estimates = new double[nr_class];
output.writeBytes("labels");
for(int j=0;j<nr_class;j++)
output.writeBytes(" "+labels[j]);
output.writeBytes("\n");
}
}
while(true)
{
String line = input.readLine();
if(line == null) break;
StringTokenizer st = new StringTokenizer(line," \t\n\r\f:");
double target = atof(st.nextToken());
int m = st.countTokens()/2;
svm_node[] x = new svm_node[m];
for(int j=0;j<m;j++)
{
x[j] = new svm_node();
x[j].index = atoi(st.nextToken());
x[j].value = atof(st.nextToken());
}
double v;
if (predict_probability==1 && (svm_type==svm_parameter.C_SVC || svm_type==svm_parameter.NU_SVC))
{
v = svm.svm_predict_probability(model,x,prob_estimates);
output.writeBytes(v+" ");
for(int j=0;j<nr_class;j++)
output.writeBytes(prob_estimates[j]+" ");
output.writeBytes("\n");
}
else //一般进入到这
{
v = svm.svm_predict(model,x);
output.writeBytes(target+"----"+v+"\n");
/**--如果要取得哪几类分错可以在这里写代码--**/
}
if(v == target)
{
++correct;
}
error += (v-target)*(v-target);
sumv += v;
sumy += target;
sumvv += v*v;
sumyy += target*target;
sumvy += v*target;
++total;
} //end while
if(svm_type == svm_parameter.EPSILON_SVR ||
svm_type == svm_parameter.NU_SVR)
{
System.out.print("Mean squared error = "+error/total+" (regression)\n");
System.out.print("Squared correlation coefficient = "+
((total*sumvy-sumv*sumy)*(total*sumvy-sumv*sumy))/
((total*sumvv-sumv*sumv)*(total*sumyy-sumy*sumy))+
" (regression)\n");
}
else
{ System.out.print("Accuracy = "+(double)correct/total*100+
"% ("+correct+"/"+total+") (classification)\n");
}
correctCount = correct ;
totalCount = total ;
}
private static int predictReturnResult(BufferedReader input, DataOutputStream output, svm_model model, int predict_probability) throws IOException
{
int correct = 0;
int total = 0;
double error = 0;
double sumv = 0, sumy = 0, sumvv = 0, sumyy = 0, sumvy = 0;
int svm_type=svm.svm_get_svm_type(model);
int nr_class=svm.svm_get_nr_class(model);
double[] prob_estimates=null;
if(predict_probability == 1)
{
if(svm_type == svm_parameter.EPSILON_SVR ||
svm_type == svm_parameter.NU_SVR)
{
System.out.print("Prob. model for test data: target value = predicted value + z,\nz: Laplace distribution e^(-|z|/sigma)/(2sigma),sigma="+svm.svm_get_svr_probability(model)+"\n");
}
else
{
int[] labels=new int[nr_class];
svm.svm_get_labels(model,labels);
prob_estimates = new double[nr_class];
output.writeBytes("labels");
for(int j=0;j<nr_class;j++)
output.writeBytes(" "+labels[j]);
output.writeBytes("\n");
}
}
while(true)
{
String line = input.readLine();
if(line == null) break;
StringTokenizer st = new StringTokenizer(line," \t\n\r\f:");
double target = atof(st.nextToken());
int m = st.countTokens()/2;
svm_node[] x = new svm_node[m];
for(int j=0;j<m;j++)
{
x[j] = new svm_node();
x[j].index = atoi(st.nextToken());
x[j].value = atof(st.nextToken());
}
double v;
if (predict_probability==1 && (svm_type==svm_parameter.C_SVC || svm_type==svm_parameter.NU_SVC))
{
v = svm.svm_predict_probability(model,x,prob_estimates);
output.writeBytes(v+" ");
for(int j=0;j<nr_class;j++)
output.writeBytes(prob_estimates[j]+" ");
output.writeBytes("\n");
}
else
{
v = svm.svm_predict(model,x);
output.writeBytes(v+"\n");
}
if(v == target)
++correct;
error += (v-target)*(v-target);
sumv += v;
sumy += target;
sumvv += v*v;
sumyy += target*target;
sumvy += v*target;
++total;
} //end while
if(svm_type == svm_parameter.EPSILON_SVR ||
svm_type == svm_parameter.NU_SVR)
{
System.out.print("Mean squared error = "+error/total+" (regression)\n");
System.out.print("Squared correlation coefficient = "+
((total*sumvy-sumv*sumy)*(total*sumvy-sumv*sumy))/
((total*sumvv-sumv*sumv)*(total*sumyy-sumy*sumy))+
" (regression)\n");
}
else
{ System.out.print("Accuracy = "+(double)correct/total*100+
"% ("+correct+"/"+total+") (classification)\n");
}
return correct ;
}
//打印帮助
private static void exit_with_help()
{
System.err.print("usage: svm_predict [options] test_file model_file output_file\n"
+"options:\n"
+"-b probability_estimates: whether to predict probability estimates, 0 or 1 (default 0); one-class SVM not supported yet\n");
System.exit(1);
}
public void main(String argv[]) throws IOException
{
int i, predict_probability=0;
// parse options
for(i=0;i<argv.length;i++)
{
if(argv[i].charAt(0) != '-') break;
++i;
switch(argv[i-1].charAt(1))
{
case 'b':
predict_probability = atoi(argv[i]);
break;
default:
System.err.print("Unknown option: " + argv[i-1] + "\n");
exit_with_help();
}
}
if(i>=argv.length-2)
exit_with_help();
try
{
BufferedReader input = new BufferedReader(new FileReader(argv[i]));
DataOutputStream output = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(argv[i+2])));
svm_model model = svm.svm_load_model(argv[i+1]);
if(predict_probability == 1)
{
if(svm.svm_check_probability_model(model)==0)
{
System.err.print("Model does not support probabiliy estimates\n");
System.exit(1);
}
}
else
{
if(svm.svm_check_probability_model(model)!=0)
{
System.out.print("Model supports probability estimates, but disabled in prediction.\n");
}
}
predict(input,output,model,predict_probability);
input.close();
output.close();
}
catch(FileNotFoundException e)
{
exit_with_help();
}
catch(ArrayIndexOutOfBoundsException e)
{
exit_with_help();
}
}
}
主要增加了返回测试正确与总的数据,如果你想要获取是哪些类分错了,也是可以添加代码的,这里没有标注。
svm_train.java 修改后:
package libsvm.bean;
import libsvm.*;
import java.io.*;
import java.util.*;
public class svm_train {
private svm_parameter param; // set by parse_command_line
private svm_problem prob; // set by read_problem
private svm_model model;
private String input_file_name; // set by parse_command_line
private String model_file_name; // set by parse_command_line
private String error_msg;
private int cross_validation;
private int nr_fold;
private static svm_print_interface svm_print_null = new svm_print_interface()
{
public void print(String s) {}
};
private static void exit_with_help()
{
System.out.print(
"Usage: svm_train [options] training_set_file [model_file]\n"
+"options:\n"
+"-s svm_type : set type of SVM (default 0)\n"
+" 0 -- C-SVC\n"
+" 1 -- nu-SVC\n"
+" 2 -- one-class SVM\n"
+" 3 -- epsilon-SVR\n"
+" 4 -- nu-SVR\n"
+"-t kernel_type : set type of kernel function (default 2)\n"
+" 0 -- linear: u'*v\n"
+" 1 -- polynomial: (gamma*u'*v + coef0)^degree\n"
+" 2 -- radial basis function: exp(-gamma*|u-v|^2)\n"
+" 3 -- sigmoid: tanh(gamma*u'*v + coef0)\n"
+" 4 -- precomputed kernel (kernel values in training_set_file)\n"
+"-d degree : set degree in kernel function (default 3)\n"
+"-g gamma : set gamma in kernel function (default 1/num_features)\n"
+"-r coef0 : set coef0 in kernel function (default 0)\n"
+"-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)\n"
+"-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)\n"
+"-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)\n"
+"-m cachesize : set cache memory size in MB (default 100)\n"
+"-e epsilon : set tolerance of termination criterion (default 0.001)\n"
+"-h shrinking : whether to use the shrinking heuristics, 0 or 1 (default 1)\n"
+"-b probability_estimates : whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)\n"
+"-wi weight : set the parameter C of class i to weight*C, for C-SVC (default 1)\n"
+"-v n : n-fold cross validation mode\n"
+"-q : quiet mode (no outputs)\n"
);
System.exit(1);
}
/**
* 做交叉验证
*/
private void do_cross_validation()
{
int i;
int total_correct = 0;
double total_error = 0;
double sumv = 0, sumy = 0, sumvv = 0, sumyy = 0, sumvy = 0;
double[] target = new double[prob.l];
svm.svm_cross_validation(prob,param,nr_fold,target);
if(param.svm_type == svm_parameter.EPSILON_SVR ||
param.svm_type == svm_parameter.NU_SVR)
{
for(i=0;i<prob.l;i++)
{
double y = prob.y[i];
double v = target[i];
total_error += (v-y)*(v-y);
sumv += v;
sumy += y;
sumvv += v*v;
sumyy += y*y;
sumvy += v*y;
}
System.out.print("Cross Validation Mean squared error = "+total_error/prob.l+"\n");
System.out.print("Cross Validation Squared correlation coefficient = "+
((prob.l*sumvy-sumv*sumy)*(prob.l*sumvy-sumv*sumy))/
((prob.l*sumvv-sumv*sumv)*(prob.l*sumyy-sumy*sumy))+"\n"
);
}
else
{
for(i=0;i<prob.l;i++)
if(target[i] == prob.y[i])
++total_correct;
System.out.print("Cross Validation Accuracy = "+100.0*total_correct/prob.l+"%\n");
}
}
private void run(String argv[]) throws IOException
{
parse_command_line(argv);
read_problem();
error_msg = svm.svm_check_parameter(prob,param);
if(error_msg != null)
{
System.err.print("ERROR: "+error_msg+"\n");
System.exit(1);
}
if(cross_validation != 0)
{
do_cross_validation();
}
else
{
model = svm.svm_train(prob,param);
svm.svm_save_model(model_file_name,model);
}
}
/**
* 支持向量机训练入口处
* @param argv
* @throws IOException
*/
public void main(String argv[]) throws IOException
{
svm_train t = new svm_train();
t.run(argv);
}
//就是把字符串s转换成double类型
private static double atof(String s)
{
double d = Double.valueOf(s).doubleValue();
if (Double.isNaN(d) || Double.isInfinite(d))
{
System.err.print("NaN or Infinity in input\n");
System.exit(1);
}
return(d);
}
//就是把字符串s转换成Int类型
private static int atoi(String s)
{
return Integer.parseInt(s);
}
//解析命令行
private void parse_command_line(String argv[])
{
int i;
svm_print_interface print_func = null; // default printing to stdout
param = new svm_parameter();
// default values
param.svm_type = svm_parameter.C_SVC;
param.kernel_type = svm_parameter.RBF;
param.degree = 3;
param.gamma = 0; // 1/num_features
param.coef0 = 0;
param.nu = 0.5;
param.cache_size = 100;
param.C = 1;
param.eps = 1e-3;
param.p = 0.1;
param.shrinking = 1;
param.probability = 0;
param.nr_weight = 0;
param.weight_label = new int[0];
param.weight = new double[0];
cross_validation = 0;
// parse options
for(i=0;i<argv.length;i++)
{
if(argv[i].charAt(0) != '-') break;
if(++i>=argv.length)
exit_with_help();
switch(argv[i-1].charAt(1))
{
case 's': //支持向量机的类型
param.svm_type = atoi(argv[i]);
break;
case 't': //支持向量机核函数
param.kernel_type = atoi(argv[i]);
break;
case 'd': //支持向量机
param.degree = atoi(argv[i]);
break;
case 'g': //支持向量机 gamma重要参数,double类型
param.gamma = atof(argv[i]);
break;
case 'r': //支持向量机
param.coef0 = atof(argv[i]);
break;
case 'n':
param.nu = atof(argv[i]);
break;
case 'm':
param.cache_size = atof(argv[i]);
break;
case 'c': //支持向量机C重要参数
param.C = atof(argv[i]);
break;
case 'e':
param.eps = atof(argv[i]);
break;
case 'p':
param.p = atof(argv[i]);
break;
case 'h':
param.shrinking = atoi(argv[i]);
break;
case 'b':
param.probability = atoi(argv[i]);
break;
case 'q':
print_func = svm_print_null;
i--;
break;
case 'v':
cross_validation = 1;
nr_fold = atoi(argv[i]);
if(nr_fold < 2)
{
System.err.print("n-fold cross validation: n must >= 2\n");
exit_with_help();
}
break;
case 'w': //添加权值
++param.nr_weight;
{
int[] old = param.weight_label;
param.weight_label = new int[param.nr_weight];
System.arraycopy(old,0,param.weight_label,0,param.nr_weight-1);
}
{
double[] old = param.weight;
param.weight = new double[param.nr_weight];
System.arraycopy(old,0,param.weight,0,param.nr_weight-1);
}
param.weight_label[param.nr_weight-1] = atoi(argv[i-1].substring(2));
param.weight[param.nr_weight-1] = atof(argv[i]);
break;
default:
System.err.print("Unknown option: " + argv[i-1] + "\n");
exit_with_help();
} //end switch
} // end if
svm.svm_set_print_string_function(print_func);
// determine filenames
if(i>=argv.length)
exit_with_help();
input_file_name = argv[i];
if(i<argv.length-1)
model_file_name = argv[i+1];
else
{
int p = argv[i].lastIndexOf('/');
++p; // whew...
model_file_name = argv[i].substring(p)+".model";
}
}
// read in a problem (in svmlight format)
private void read_problem() throws IOException
{
BufferedReader fp = new BufferedReader(new FileReader(input_file_name));
Vector<Double> vy = new Vector<Double>();
Vector<svm_node[]> vx = new Vector<svm_node[]>();
int max_index = 0;
while(true)
{
String line = fp.readLine();
if(line == null) break;
StringTokenizer st = new StringTokenizer(line," \t\n\r\f:");
vy.addElement(atof(st.nextToken()));
int m = st.countTokens()/2;
svm_node[] x = new svm_node[m];
for(int j=0;j<m;j++)
{
x[j] = new svm_node();
x[j].index = atoi(st.nextToken());
x[j].value = atof(st.nextToken());
}
if(m>0) max_index = Math.max(max_index, x[m-1].index);
vx.addElement(x);
}
prob = new svm_problem();
prob.l = vy.size();
prob.x = new svm_node[prob.l][];
for(int i=0;i<prob.l;i++)
prob.x[i] = vx.elementAt(i);
prob.y = new double[prob.l];
for(int i=0;i<prob.l;i++)
prob.y[i] = vy.elementAt(i);
if(param.gamma == 0 && max_index > 0)
param.gamma = 1.0/max_index;
if(param.kernel_type == svm_parameter.PRECOMPUTED)
for(int i=0;i<prob.l;i++)
{
if (prob.x[i][0].index != 0)
{
System.err.print("Wrong kernel matrix: first column must be 0:sample_serial_number\n");
System.exit(1);
}
if ((int)prob.x[i][0].value <= 0 || (int)prob.x[i][0].value > max_index)
{
System.err.print("Wrong input format: sample_serial_number out of range\n");
System.exit(1);
}
}
fp.close();
}
}
也没有什么修改,就是添加了public ,主要修改的还是svm_predict.java这个类。
调用的方法:主要的修改参数已经写好了,demo用的测试数据和训练数据是一样的
package com.endual.paper.main;
import java.io.IOException;
import libsvm.bean.svm_predict;
import libsvm.bean.svm_train;
/**
* Libsvm版本3.12
* @author endual
* 导入训练文件,然后训练,导入预测文件,然后预测
*
*/
public class EndualMain {
public static void main(String[] args) throws Exception {
/** 建立模型 **/
String[] arg_train = {"-s","0", //默认的支持向量机类型
"-t","2", //默认的核函数类型RBF
"-d","2", //set degree in kernel function (default 3)
"-g","10", //set gamma in kernel function (default 1/num_features)
"-r","0", //set coef0 in kernel function (default 0)
"-c","1", //set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
"-n","0.5", //set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)
"-b","0", //whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)
"file_data\\data\\data.txt",
"file_data\\model\\data_model.txt"} ;
svm_train train = new svm_train();
train.main(arg_train) ;//进行训练
/** 预测数据 **/
String[] arg_predict = {"-b","0", //predict probability estimates, 0 or 1 (default 0)
"file_data\\data\\data.txt",
"file_data\\model\\data_model.txt",
"file_data\\out\\data_out.txt"} ;
svm_predict predict = new svm_predict() ;
predict.main(arg_predict) ;
int correctCount = predict.getCorrectCount() ; //获取到预测准确的个数
int totalCount = predict.getTotalCount() ; //获取到总的预测个数
System.out.println("||----------------------------------------||");
System.out.println("|| 预测准确的个数="+correctCount);
System.out.println("|| 总的预测的个数="+totalCount);
System.out.println("||-------------------------------------- ||");
}
}
运行结果:
..* optimization finished, #iter = 28 nu = 0.46153846153846156 obj = -4.025964170236124, rho = -0.6825924901648381 nSV = 13, nBSV = 3 ..* optimization finished, #iter = 38 nu = 0.8888888888888888 obj = -8.5069246595277, rho = -0.15000782032015664 nSV = 18, nBSV = 8 ..* optimization finished, #iter = 28 nu = 0.3333333333333333 obj = -2.7925423354383563, rho = -0.7960877909831303 nSV = 12, nBSV = 2 .* optimization finished, #iter = 15 nu = 0.5454545454545454 obj = -3.9300105118677906, rho = 0.618192908080933 nSV = 11, nBSV = 3 ..* optimization finished, #iter = 13 nu = 0.8 obj = -2.3219227628258747, rho = -0.3342767053776095 nSV = 5, nBSV = 2 .* optimization finished, #iter = 15 nu = 0.4 obj = -2.7316267112794113, rho = -0.7446069747755875 nSV = 10, nBSV = 2 Total nSV = 23 Accuracy = 100.0% (23/23) (classification) ||----------------------------------------|| || 预测准确的个数=23 || 总的预测的个数=23 ||-------------------------------------- ||