在Spark1.2的时候,Spark将默认基于Hash的Shuffle改为了默认基于Sort的Shuffle。那么二者在Shuffle过程中具体的Behavior究竟如何,Hash based shuffle有什么问题,Sort Based Shuffle有什么问题,
先看源代码分析下Hash Based Shuffle的流程,然后在从大方面去理解,毕竟,看代码是见数目不见森林。等见了树木之后,再看看森林是什么样的。
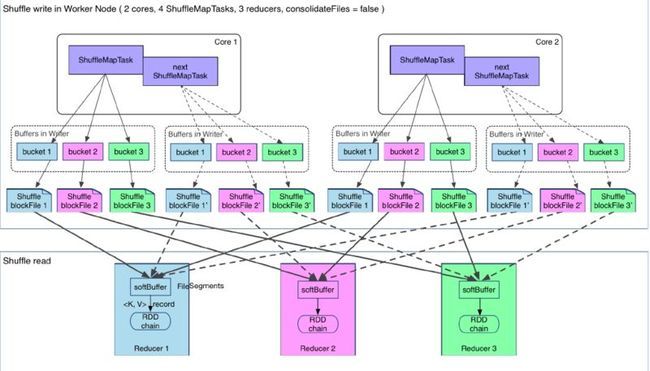
1.Hash Shuffle总体架构图
2. 示例程序
package spark.examples
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object SparkWordCountHashShuffle {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "E:\\devsoftware\\hadoop-2.5.2\\hadoop-2.5.2");
val conf = new SparkConf()
conf.setAppName("SparkWordCount")
conf.setMaster("local[3]")
//Hash based Shuffle;
conf.set("spark.shuffle.manager", "hash");
val sc = new SparkContext(conf)
val rdd = sc.textFile("file:///D:/word.in.3",4); //数据至少产生4个分区
val rdd1 = rdd.flatMap(_.split(" "))
val rdd2 = rdd1.map((_, 1))
val rdd3 = rdd2.reduceByKey(_ + _, 3); ///3个分区对应3个ResultTask
rdd3.saveAsTextFile("file:///D:/wordout" + System.currentTimeMillis());
sc.stop
}
}
调用rdd3.toDebugString得到如下的RDD依赖关系图(其实在ShuffledRDD之后,即在saveAsTextFile内部还会继续对rdd3进行转换,此处不考虑,ShuffledRDD是经过Shuffle过形成的RDD)
(3) ShuffledRDD[4] at reduceByKey at SparkWordCountHashShuffle.scala:18 []
+-(5) MappedRDD[3] at map at SparkWordCountHashShuffle.scala:17 []
| FlatMappedRDD[2] at flatMap at SparkWordCountHashShuffle.scala:16 []
| file:///D:/word.in.3 MappedRDD[1] at textFile at SparkWordCountHashShuffle.scala:15 []
| file:///D:/word.in.3 HadoopRDD[0] at textFile at SparkWordCountHashShuffle.scala:15 []
Shuffle写操作发生在ShuffleMapTask中,Shuffle读操作发生在ResultTask中。ResultTask通过MapOutputTrackerMaster来获取ShuffleMapTask写数据的位置,因此,当ShuffleMapTask执行完后会更新MapOutputTrackerMaster以记录Shuffle写入数据的位置,而ResultTask则读取MapOutputTrackerMaster的相关信息读取ShuffleMapTask的写入数据
3. Hash Shuffle Write
3.1 ShuffleMapTask的runTask方法
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val ser = SparkEnv.get.closureSerializer.newInstance()
///反序列化taskBinary得到rdd和dep,rdd是Shuffle前的最后一个RDD,即wordcount中的MappedRDD[3]
///dep是ShuffleDependency
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
metrics = Some(context.taskMetrics)
var writer: ShuffleWriter[Any, Any] = null
try {
///获取shuffleManager,此处是HashShuffleManager
val manager = SparkEnv.get.shuffleManager
///根据dep.shuffleHandle以及partitionId获取HashShuffleWriter,
///首先,ShuffleWriter是与RDD的一个分区关联的,因此M个ShuffleMapTask(对应m个partition),就会产生m个writer
///dep.shuffleHandle获取的是什么,下面分析
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
////调用HashShuffleWriter的write方法,写入的数据(入参是RDD中,index为partition的分区数据集合(Iteratable)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
///stop做了什么事?调用stop的返回值的get方法以返回MapStatus对象,至于MapStatus对象中有什么数据,后面分析
return writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
3.2 反序列化taskBinary
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
问题在于rdd和dep指的是什么?rdd是ShuffleMapStage的最后一个RDD,dep是ShuffleDependency类型,表示这个Stage对于它依赖的Stage而言是Shuffle依赖的。
rdd和dep是在DAGScheduler的submitMissingTasks中序列化的,代码片段如下
var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] =
if (stage.isShuffleMap) { ///rdd来自于stage.rdd,dep来自于stage.shuffleDep.get,这个stage是ShuffleMapStage
closureSerializer.serialize((stage.rdd, stage.shuffleDep.get) : AnyRef).array()
} else {
closureSerializer.serialize((stage.rdd, stage.resultOfJob.get.func) : AnyRef).array()
}
taskBinary = sc.broadcast(taskBinaryBytes)///通过broadcast,由driver向workers传播
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString)
runningStages -= stage
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${e.getStackTraceString}")
runningStages -= stage
return
}
3.3 dep.shuffleHandle
dep是ShuffleDependency对象;dep.shuffleHandle的类型是ShuffleHandle,实际类型是BasicShuffleHandle。shuffleHandle是ShuffleDependency的一个成员变量,在实例化ShuffleDependency的时候,即给它进行复制。复制是调用HashShuffleManager的registerShuffle方法实现的,registerShuffle有三个参数,shuffleId,ShuffleMapStage的最后一个RDD(这里的MappedRDD[3]的分区数,以及ShuffleDependency对象本身)。
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)
_rdd是ShuffleDependency的一个成员,这个rdd是ShuffledRDD构造时传入的,如下是ShuffledRDD的getDependencies方法,prev就是ShuffledRDD依赖的RDD,就是这里的_rdd。
registerShuffle记录的是ShuffledRDD依赖的rdd的partition数目
override def getDependencies: Seq[Dependency[_]] = {
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}
3.4 HashShuffleManager的registerShuffle方法
/* Register a shuffle with the manager and obtain a handle for it to pass to tasks. */
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int, ////可见这个参数是mapper RDD的partition数目
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
3.4.2 关于BaseShuffleHandle
/**
* A basic ShuffleHandle implementation that just captures registerShuffle's parameters.
*/
private[spark] class BaseShuffleHandle[K, V, C](
shuffleId: Int,
val numMaps: Int,
val dependency: ShuffleDependency[K, V, C])
extends ShuffleHandle(shuffleId)
/**
* An opaque handle to a shuffle, used by a ShuffleManager to pass information about it to tasks.
*
* @param shuffleId ID of the shuffle
*/
private[spark] abstract class ShuffleHandle(val shuffleId: Int) extends Serializable {}
BaseShuffleHandle更像是一个case class,注意它是可序列化的,正如BaseShuffleHandle的方法说明,用于存放shuffle的信息的。
3.5manger.getWriter方法此处的manager是HashShuffleManager,
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext)
: ShuffleWriter[K, V] = {
new HashShuffleWriter(
shuffleBlockManager, handle.asInstanceOf[BaseShuffleHandle[K, V, _]], mapId, context)
} 可见此处的getWriter返回一个HashShuffleWriter,它是针对Mapper partitions中一个partition返回的(mapId的含义就是一个mapper的一个partition的index)。同时携带一个BaseShuffleHandle(启动携带了shuffleId,mapper partitions总数以及ShuffleDependency)。在构造HashShuffleWriter的过程中,出现了shuffleBlockManager对象,注意getWriter是在HashShuffleManager中定义的,因此ShuffleBlockManager是HashShuffleManager的一个实例,代码定义如下,也就是说,对于Hash Shuffle而言,它的ShuffleBlockManager是FileShuffleBlockManager类型的,这个类中定义了Hash Shuffle时,ShuffleMapTask写磁盘时的文件载体就在这里面定义,待会儿介绍
override def shuffleBlockManager: FileShuffleBlockManager = {
fileShuffleBlockManager
}
3.6 HashShuffleWriter实例化完后,调用它的write方法(注意,HahsShuffleWriter的实际存储载体是FileShuffleBlockManager):
调用writer.write方法进行实际的写数据操作
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
write方法的入参是一个partition的数据集合(Iteratable),这个partition是一个整数,是mapper的partitions的一个partition的index
/** Write a bunch of records to this task's output */
override def write(records: Iterator[_ <: Product2[K, V]]): Unit = {
///上面看到ShuffleDependency构造时,包含了如下信息:
/// List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
///根据dep的aggregator和mapSideCombine定义的不同情况,决定对分区数据是否进行按照Key进行Map端的合并
val iter =
if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {///如果定义了dep.aggregator同时定义了dep.mapSideCombine,则对Key进行combine操作,这是一个map端的combine 就是_ + _操作
dep.aggregator.get.combineValuesByKey(records, context) ////内部使用HashMap进行combine
} else { ////如果定义了dep.aggregator但是未定义map端的combiner
records
}
}
else if (dep.aggregator.isEmpty && dep.mapSideCombine) { ///如果定义了dep.mapSideCombine但是没有定义dep.aggregator,则抛出异常
throw new IllegalStateException("Aggregator is empty for map-side combine")
}
else { //直接返回,不进行Map端的按照Key的合并
records
}
////遍历iter,每个partition生成一个文件?不是!是根据不同的Key获取不同的输出文件(一共partitioner.partition个文件)
for (elem <- iter) {
///根据元素Key得到bucketId,此处的关键是dep.partitioner指的是Shuffle前的最后一个RDD的分区方法还是Shuffle后的第一个RDD的分区方法
val bucketId = dep.partitioner.getPartition(elem._1) ///根据Key获取bucketId
////根据bucketId获得一个writer,根据bucketId获得不同的writer,也就是不同的(Key,Value)写到不同的文件中了(依据elem所对应的bucketId)
///writers是shuffle的函数,参数是bucketId
shuffle.writers(bucketId).write(elem)
}
}
3.7 Aggregator.combineValuesByKey
Aggregator.combineValuesByKey(即Mapper端做combine)是比较复杂的一步,它依据是否要spill磁盘分成了使用AppendOnlyMap做combine和ExternalAppendOnlyMap做combine,方法的结果是一样的,就是返回一个可迭代的数据集合(比较长,后面再展开说)
3.8 遍历每个元素,调用dep.partitioner.getPartition(elem._1)获取bucketId
此处的dep.partitioner是Shuffle前的最后一个RDD(MappedRDD[3])定义的partitoner还 是Shuffle后的第一个RDD(ShuffledRDD)定义的partitioner
ShuffleDependency的partitioner是作为构造参数传入到ShuffleDependen中的,它的注释是用于对shuffle输出进行分区。通过调试也确认了,这个partitioner指的是ShuffledRDD的分区数,即它是Shuffle后的第一个RDD(ShuffledRDD)定义的partitioner。
调试发现dep.partitioner是一个分区数为3的HashPartitioner。
这也就是不难理解,dep.partitioner.getPartition(elem._1)获取的是这个elem按照ShuffledRDD的分区算法存放到指定的位置,因此,bucketId是ShuffledRDD的分区的index。
3.8.2. Partitioner的getPartition方法:
def getPartition(key: Any): Int = key match {
case null => 0
////使用Utils.nonNegativeMod的方法计算Key的Hash取模
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
3.8.3 Utils.nonNegativeMod方法
/* Calculates 'x' modulo 'mod', takes to consideration sign of x,
* i.e. if 'x' is negative, than 'x' % 'mod' is negative too
* so function return (x % mod) + mod in that case.
*/
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod
rawMod + (if (rawMod < 0) mod else 0)
}
3.9调用shuffle.writers(bucketId)获取一个目标(ShuffledRDD每个分区对应的ResultTask的拉取数据的源头)的writer,然后调用write将元素写入
3.10 首先看一下shuffle变量在HashShuffleWriter中的定义
///shuffleBlockManager的类型是FileShuffleBlockManager
private val shuffle = shuffleBlockManager.forMapTask(dep.shuffleId, mapId, numOutputSplits, ser,
writeMetrics)
3.11 shuffleBlockManager.forMapTask方法
/**
* Get a ShuffleWriterGroup for the given map task, which will register it as complete
* when the writers are closed successfully
*/
///mapId:是map端的partitionId,numBuckets是ResultTask的个数或者ShuffledRDD的分区数
///forMapTask是针对每个mapId,建立numBuckets个数(Reducer个数)的File?
def forMapTask(shuffleId: Int, mapId: Int, numBuckets: Int, serializer: Serializer,
writeMetrics: ShuffleWriteMetrics) = {
new ShuffleWriterGroup {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets))
private val shuffleState = shuffleStates(shuffleId)
private var fileGroup: ShuffleFileGroup = null
val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) { ///如果是consolidateShuffleFiles,把shuffle聚合在一起
fileGroup = getUnusedFileGroup()
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer, bufferSize,
writeMetrics)
}
} else {
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId => ///创建一个个数为numBuckets的数组,数组元素类型是BlockObjectWriter
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId) //ShuffleBlockId对象,入参:shuffleId,mapId以及每个reducer的partitionId
//blockManager的类型是org.apache.spark.storage.BlockManager
//BlockManager的类注释是Manager running on every node (driver and executors) which provides interfaces for putting and retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap).
//diskBlockManager的类型是DiskBlockManager
//DiskBlockManager:
/*Creates and maintains the logical mapping between logical blocks and physical on-disk
* locations. By default, one block is mapped to one file with a name given by its BlockId.
* However, it is also possible to have a block map to only a segment of a file, by calling
* mapBlockToFileSegment().
val blockFile = blockManager.diskBlockManager.getFile(blockId) ///根据上面的三方面信息,获取一个文件blockFile,一共M*N个文件
// Because of previous failures, the shuffle file may already exist on this machine.
// If so, remove it.
if (blockFile.exists) {
if (blockFile.delete()) {
logInfo(s"Removed existing shuffle file $blockFile")
} else {
logWarning(s"Failed to remove existing shuffle file $blockFile")
}
}
///根据blockId,blockFile获取一个BlockObjectWriter,blockId和blockFile有点重复,因为blockFile中已经包含了blockId的信息
///bufferSize取自SparkConf中配置的spark.shuffle.file.buffer.kb参数,以kb为单位,默认为32,即32kb,用于写文件的缓冲
blockManager.getDiskWriter(blockId, blockFile, serializer, bufferSize, writeMetrics)
}
}
由于forMapTask返回的ShuffleWriterGroup类型的对象,因此shuffle变量是ShuffleWriterGroup类型的,而ShuffleWriterGroup对象有一个writers成员
3.11.1 ShuffleBlockId
这个类像是JavaBean,它有唯一的一个name,用户获取这个ShuffleBlockId的名称,其中的reduceId,就是上面构造时传入的bucketId
name = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId
3.11.2 blockManager.diskBlockManager.getFile(blockId)
根据blockid获取一个File,注意,此时这个File还没有创建,如果这个File已经存在,首先将其删除
它是调用DiskBlockManager的getFile方法
def getFile(blockId: BlockId): File = getFile(blockId.name)
getFile继续调用重载的getFile(fileName)
def getFile(filename: String): File = {
// Figure out which local directory it hashes to, and which subdirectory in that
//对文件名做Hash
//filename,例如shuffle_0_0_0
val hash = Utils.nonNegativeHash(filename)
//此处首先要知道localDirs是什么含义,通过它得到dirId,(dirId是一个目录的索引,即localDir[dirId]将得到具体的的目录)
//localDirs就是制定的存放map结果数据的临时目录,可以指定多个,用逗号分隔
//在wordcount例子中,没有指定spark.local.dir,默认去java.io.tmp的目录,并且localDirs的长度为1
//此时dirId为0
val dirId = hash % localDirs.length
//subDirsPerLocalDir是什么?它取自SparkConf的spark.diskStore.subDirectories配置参数,默认为64
//因为localDirs.length为1,那么subDirId=hash%subDirsPerLocalDir, 0~63的数字
val subDirId = (hash / localDirs.length) % subDirsPerLocalDir
// Create the subdirectory if it doesn't already exist
//subDir是个二维数组:
//private val subDirs = Array.fill(localDirs.length)(new Array[File](subDirsPerLocalDir))
///fill接收两个参数,第一个参数为n,表示对于0到n-1,每个元素都第二个参数填充,因此subDirs是个二维数组,表示对于每个localDir,都有0到subDirsPerLocalDir个数的子目录
///根据dirId和subDirId获取子目录的文件对象,应该还是null,经验证是null
var subDir = subDirs(dirId)(subDirId)
//子目录尚不存在
if (subDir == null) {
subDir = subDirs(dirId).synchronized { ///subDirs(dirId)得到的是一个一维数组
val old = subDirs(dirId)(subDirId) ///线程同步的两阶段检查
if (old != null) {
old
} else {
val newDir = new File(localDirs(dirId), "%02x".format(subDirId)) ///将subDirId转换成16进制,
newDir.mkdir()
subDirs(dirId)(subDirId) = newDir ///给二维数组赋值
newDir ///赋给subDir
}
}
}
///文件所在的目录,以及文件名,但是并未创建File,即没有调用File.createNewFile
///subDir是${java.io.tmp}/spark-local-20150219132253-c917/0c(或者0d,是个单调增的16进制数,)
new File(subDir, filename)
}
localDirs:
/* Create one local directory for each path mentioned in spark.local.dir; then, inside this
* directory, create multiple subdirectories that we will hash files into, in order to avoid
* having really large inodes at the top level. */
//Gets or creates the directories listed in spark.local.dir or SPARK_LOCAL_DIRS,
private[spark] val localDirs: Array[File] = createLocalDirs(conf)
郁闷的是,本地的断点调试进不了这个代码,源代码和class文件已经不匹配了,先把wordcount程序执行ShuffleMapTask生成的map结果,写下来,然后反推代码的含义
C:\Users\hadoop\AppData\Local\Temp\spark-local-20150219132253-c917>tree /f
文件夹 PATH 列表
卷序列号为 4E9D-390C
C:.
├─0c
│ shuffle_0_0_0
│
├─0d
│ shuffle_0_0_1
│
├─0e
│ shuffle_0_0_2
│ shuffle_0_2_0
│
├─0f
│ shuffle_0_2_1
│ shuffle_0_3_0
│
├─10
│ shuffle_0_2_2
│ shuffle_0_3_1
│
├─11
│ shuffle_0_3_2
│
├─12
└─13
经过上面的验证,localDirs是 C:\Users\hadoop\AppData\Local\Temp\spark-local-20150219132253-c917,而它下面的0c,0d...13则是16进制的子dirs。每个目录下最多有64个。
3.11.3 获取到blockFile之后,执行如下语句,获取Writer,返回的类型为BlockObjectWriter
blockManager.getDiskWriter(blockId, blockFile, serializer, bufferSize, writeMetrics)
上面的语句的实现方法如下:
def getDiskWriter(
blockId: BlockId,
file: File,
serializer: Serializer,
bufferSize: Int,
writeMetrics: ShuffleWriteMetrics): BlockObjectWriter = {
val compressStream: OutputStream => OutputStream = wrapForCompression(blockId, _)
val syncWrites = conf.getBoolean("spark.shuffle.sync", false)
new DiskBlockObjectWriter(blockId, file, serializer, bufferSize, compressStream, syncWrites,
writeMetrics)
}
可见它是返回DiskBlockObjectWriter,有压缩算法serializer?
至此,FileShuffleBlockManager的forMapTask已经分析完了
3.12 通过shuffle.writers(bucketId)获取到FileShuffleBlockManager的forMapTask返回的DiskShuffleBlockWriter对象,调用它的write方法
override def write(value: Any) {
if (!initialized) {
open()
}
objOut.writeObject(value) ///写入二进制流
if (writesSinceMetricsUpdate == 32) {
writesSinceMetricsUpdate = 0
updateBytesWritten()
} else {
writesSinceMetricsUpdate += 1
}
}
3.13 当这个RDD的partition中的数据写完后,代码回到ShuffleMapTask的runTask中,执行最后一步,
return writer.stop(success = true).get
此时有两步操作,首先关闭上面的writer,因为在写的时候,打开了R个文件,需要关闭;其次是要讲写入的数据通知MapOutputTrackerMaster
/** Close this writer, passing along whether the map completed */
override def stop(initiallySuccess: Boolean): Option[MapStatus] = {
var success = initiallySuccess
try {
if (stopping) {
return None
}
stopping = true
if (success) {
try {
Some(commitWritesAndBuildStatus()) ///这是干啥?应该是作为返回值的,使用Some包装
} catch {
case e: Exception =>
success = false
revertWrites()
throw e
}
} else {
revertWrites()
None
}
} finally {
// Release the writers back to the shuffle block manager.
if (shuffle != null && shuffle.writers != null) { ///try的commitWritesAndBuildStatus已经关闭了所有打开的shuffle的writers,这里为什么还要release?
try {
shuffle.releaseWriters(success)
} catch {
case e: Exception => logError("Failed to release shuffle writers", e)
}
}
}
}
3.13.1
commitWritesAndBuildStatus
private def commitWritesAndBuildStatus(): MapStatus = {
// Commit the writes. Get the size of each bucket block (total block size).
//每个writer都有写数据
val sizes: Array[Long] = shuffle.writers.map { writer: BlockObjectWriter =>
writer.commitAndClose() ///提交并关闭
writer.fileSegment().length ///fileSegment()的长度如何结算的?这是每个writer写数据的长度
}
///sizes是数组,表示本map所有的针对所有的reduce的数据都已经产生,每个mapper为每个reducer产生一个文件
MapStatus(blockManager.shuffleServerId, sizes)
}
3.13.2 DiskBlockObjectWriter的fileSegment()方法
override def fileSegment(): FileSegment = {
///三个参数:
//initialPosition表示内容在文件的起始位置, finalPosition-initialPosition表示这个Segment的长度,对于没有启用consolidatition的map out,每个Seg就是一个完成的文件
new FileSegment(file, initialPosition, finalPosition - initialPosition)
}
3.14上面在commitWritesAndBuildStatus方法中返回了MapStatus对象,此对象尚没有给MapOutputTrackerMaster登记自己shuffle数据的位置
由于Spark的源代码和二进制包不同步,导致代码无法跟踪,先暂时到这里,先接着分析Hash Based Shuffle读吧。
上面对Hash based Shuffle write进行了源代码的剖析,还有一部分没有涉及,就是map端的combine操作,Aggragator.combineValuesByKey操作,没有进行涉及,再写。
其他【不包含在上面的分钟】
传入的partition数和实际的partition个数的对应关系
conf.set("spark.shuffle.manager", "hash");
1. 指定partition书目的textFile操作
val rdd = sc.textFile("file:///D:/word.in.3",4); //4是最小partition书目
2. 如下的代码来自于HadoopRDD.scala,当前的minPartitions的值是4,得到的inputSplits的值是5,也就是Partition的数目为5
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
// add the credentials here as this can be called before SparkContext initialized
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
if (inputFormat.isInstanceOf[Configurable]) {
inputFormat.asInstanceOf[Configurable].setConf(jobConf)
}
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}
ResultTask个数与Map Partition个数之间的关系,
1.如果ResultTask没有指定个数,那么默认是与Map Partition的个数相同;如果指定了,则按照指定的值创建ResultTask实例
package spark.examples
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object SparkWordCount {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "E:\\devsoftware\\hadoop-2.5.2\\hadoop-2.5.2");
val conf = new SparkConf()
conf.setAppName("SparkWordCount")
conf.setMaster("local")
//Hash based Shuffle;
conf.set("spark.shuffle.manager", "hash");
val sc = new SparkContext(conf)
val rdd = sc.textFile("file:///D:/word.in.3",4); //4表示最小Partition书目
println(rdd.toDebugString)
val rdd1 = rdd.flatMap(_.split(" "))
println("rdd1:" + rdd1.toDebugString)
val rdd2 = rdd1.map((_, 1))
println("rdd2:" + rdd2.toDebugString)
val rdd3 = rdd2.reduceByKey(_ + _, 3); ///3表示ReduceTask的个数,如果不指定则与Map Partition的个数相同
println("rdd3:" + rdd3.toDebugString)
rdd3.saveAsTextFile("file:///D:/wordout" + System.currentTimeMillis());
sc.stop
}
}
HashBased Shuffle Map产生的文件数,与Map Partition个数和ReduceTask个数的关系
1.Map的中间结果默认存放在java.io.tmp目录下,如果指定了则保存到指定目录
2.如果一个RDD有N个Partition,会产生N个ShuffleMapTask。
3.如果有1个ResultTask,那么最后的结果,会产生1个结果文件.Part-00000。如果有R个ReduceTask(即ResultTask),则会产生R个结果文件。
4.M个partition,N个reduceTask,产生多少个Map文件?M*N。 例如:
/tmp/0c/shuffle_0_0_0
/tmp/0d/shuffle_0_0_1
/tmp/0d/shuffle_0_0_2
/tmp/0e/shuffle_0_2_0
/tmp/0f/shuffle_0_2_1
/tmp/0f/shuffle_0_3_0
shuffle后面的三个数字的含义:
- shuffleId
- PartiontionID
- ReduceTaskId,表明该partition将由第几个ReuceTask进行处理。最大值是2,因为一共3个ReduceTask
并行度
是指执行ReduceTask有几个core来执行,同时执行的个数。(除了一个local【4】的方式,还有一个设置并行度的参数)。设置了并行度后,上面的文件个数不变。
/**
* The master URL to connect to, such as "local" to run locally with one thread, "local[4]" to
* run locally with 4 cores, or "spark://master:7077" to run on a Spark standalone cluster.
*/
def setMaster(master: String): SparkConf = {
set("spark.master", master)
}
spark.shuffle.consolidateFiles选项
示例源代码:
package spark.examples.shuffle
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object SparkHashShuffleConsolidationFile {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "E:\\devsoftware\\hadoop-2.5.2\\hadoop-2.5.2");
val conf = new SparkConf()
conf.setAppName("SparkWordCount")
conf.setMaster("local[3]")
//Hash based Shuffle;
conf.set("spark.shuffle.manager", "hash");
//使用文件聚合
conf.set("spark.shuffle.consolidateFiles", "true");
val sc = new SparkContext(conf)
//10个以上的分区,每个分区对应一个Map Task
//读取一个1M的文件
val rdd = sc.textFile("file:///D:/server.log", 10);
val rdd1 = rdd.flatMap(_.split(" "))
val rdd2 = rdd1.map((_, 1))
//6个Reducer
val rdd3 = rdd2.reduceByKey(_ + _, 6);
rdd3.saveAsTextFile("file:///D:/wordcount" + System.currentTimeMillis());
println(rdd3.toDebugString)
sc.stop
}
}
结果Map Task产生了13个目录,文件内容:
C:.
├─00
│ merged_shuffle_0_5_2
│
├─01
│ merged_shuffle_0_4_2
│ merged_shuffle_0_5_1
│
├─02
│ merged_shuffle_0_3_2
│ merged_shuffle_0_4_1
│ merged_shuffle_0_5_0
│
├─03
│ merged_shuffle_0_2_2
│ merged_shuffle_0_3_1
│ merged_shuffle_0_4_0
│
├─04
│ merged_shuffle_0_1_2
│ merged_shuffle_0_2_1
│ merged_shuffle_0_3_0
│
├─05
│ merged_shuffle_0_0_2
│ merged_shuffle_0_1_1
│ merged_shuffle_0_2_0
│
├─06
│ merged_shuffle_0_0_1
│ merged_shuffle_0_1_0
│
├─07
│ merged_shuffle_0_0_0
│
├─0c
├─0d
├─0e
├─11
└─13
1. 结果显示一共六个Mapper,3个Reducer,18个文件,分析原因
2. 每个文件有个merged前缀,何意
加大输入文件的规模,看看结果?结果还是一样。为什么只有6个Mapper,而且只有3个Reducer(3是跟并行度有关的吧?)