SQL Server 2008 的 Transact-SQL 语言增强(2)
作者:张洪举 Microsoft MVP <?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
应用于:SQL Server 2008
日期:2008/9/1
6.MERGE 语句
在 SQL Server 2008 中,可以使用 MERGE 语句在一条语句中根据与源表联接的结果对目标表执行 INSERT、UPDATE 或 DELETE 操作。如:使用一个语句有条件地在单个目标表中插入或更新行,如果目标表中存在相应行,则更新一个或多个列;否则,会将数据插入新行。使用该语句还可以同步两个表,根据与源数据的差别在目标表中插入、更新或删除行。
MERGE 语法包括如下五个主要子句:
MERGE 子句用于指定作为插入、更新或删除操作目标的表或视图。
USING 子句用于指定要与目标联接的数据源。
ON 子句用于指定决定目标与源的匹配位置的联接条件。
WHEN 子句用于根据 ON 子句的结果指定要执行的操作。
OUTPUT 子句针对更新、插入或删除的目标对象中的每一行返回一行。
其完整的语法格式如下:
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] target_table [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source>
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
使用下面的语句创建两个表:
USE AdventureWorks;
GO
IF OBJECT_ID (N'dbo.Purchases', N'U') IS NOT NULL
DROP TABLE dbo.Purchases;
GO
CREATE TABLE dbo.Purchases (
ProductID int, CustomerID int, PurchaseDate datetime,
CONSTRAINT PK_PurchProdID PRIMARY KEY(ProductID,CustomerID));
GO
INSERT INTO dbo.Purchases VALUES(707, 11794, '20060821'),
(707, 15160, '20060825'),(708, 18529, '20060821'),
(712, 19072, '20060821'),(870, 15160, '20060823'),
(870, 11927, '20060824'),(870, 18749, '20060825');
GO
IF OBJECT_ID (N'dbo.FactBuyingHabits', N'U') IS NOT NULL
DROP TABLE dbo.FactBuyingHabits;
GO
CREATE TABLE dbo.FactBuyingHabits (
ProductID int, CustomerID int, LastPurchaseDate datetime,
CONSTRAINT PK_FactProdID PRIMARY KEY(ProductID,CustomerID));
GO
INSERT INTO dbo.FactBuyingHabits VALUES(707, 11794, '20060814'),
(707, 18178, '20060818'),(864, 14114, '20060818'),
(870, 17151, '20060818'),(870, 15160, '20060817'),
(871, 21717, '20060817'),(871, 21163, '20060815'),
(871, 13350, '20060815'),(873, 23381, '20060815');
GO
两个表中的数据如下图所示:
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" /><shapetype id="_x0000_t75" stroked="f" filled="f" path="m@4@5l@4@11@9@11@9@5xe" o:preferrelative="t" o:spt="75" coordsize="21600,21600"><stroke joinstyle="miter"></stroke><formulas><f eqn="if lineDrawn pixelLineWidth 0"></f><f eqn="sum @0 1 0"></f><f eqn="sum 0 0 @1"></f><f eqn="prod @2 1 2"></f><f eqn="prod @3 21600 pixelWidth"></f><f eqn="prod @3 21600 pixelHeight"></f><f eqn="sum @0 0 1"></f><f eqn="prod @6 1 2"></f><f eqn="prod @7 21600 pixelWidth"></f><f eqn="sum @8 21600 0"></f><f eqn="prod @7 21600 pixelHeight"></f><f eqn="sum @10 21600 0"></f></formulas><path o:connecttype="rect" gradientshapeok="t" o:extrusionok="f"></path><lock aspectratio="t" v:ext="edit"></lock></shapetype><shape id="图片_x0020_4" style="VISIBILITY: visible; WIDTH: 318pt; HEIGHT: 108pt; mso-wrap-style: square" alt="7.jpg" type="#_x0000_t75" o:spid="_x0000_i1027"><imagedata o:title="7" src="file:///C:%5CUsers%5Czhj%5CAppData%5CLocal%5CTemp%5Cmsohtmlclip1%5C01%5Cclip_image001.jpg"></imagedata></shape>

请注意,这两个表中有两个共有的产品-客户行:客户 11794 购买了产品 707,客户 15160 购买了产品 870。对于这些行,可以使用 WHEN MATCHED THEN 子句利用 Purchases 中这些购买记录的日期来更新 FactBuyingHabits。我们可以使用 WHEN NOT MATCHED THEN 子句将所有其他行插入 FactBuyingHabits。参考下面的语句:
MERGE dbo.FactBuyingHabits AS Target
USING (SELECT CustomerID, ProductID, PurchaseDate FROM dbo.Purchases) AS Source
ON (Target.ProductID = Source.ProductID AND Target.CustomerID = Source.CustomerID)
WHEN MATCHED THEN
UPDATE SET Target.LastPurchaseDate = Source.PurchaseDate
WHEN NOT MATCHED BY TARGET THEN
INSERT (CustomerID, ProductID, LastPurchaseDate)
VALUES (Source.CustomerID, Source.ProductID, Source.PurchaseDate)
OUTPUT $action, Inserted.*, Deleted.*;
$action用于在 OUTPUT 子句中指定一个 nvarchar(10) 类型的列,列的值是代表所执行操作的INSERT、UPDATE或DELETE。Inserted.*和Deleted.*分别用于指定返回所有插入行的列和删除行的列。如果要指定具体的列,可以使用Inserted.ProductID这样的命名方式。
上面语句的输出结果如下:
<shape id="图片_x0020_5" style="VISIBILITY: visible; WIDTH: 318.75pt; HEIGHT: 78pt; mso-wrap-style: square" alt="8.jpg" type="#_x0000_t75" o:spid="_x0000_i1026"><imagedata o:title="8" src="file:///C:%5CUsers%5Czhj%5CAppData%5CLocal%5CTemp%5Cmsohtmlclip1%5C01%5Cclip_image002.jpg"><font color="#000000" size="3"></font></imagedata></shape>

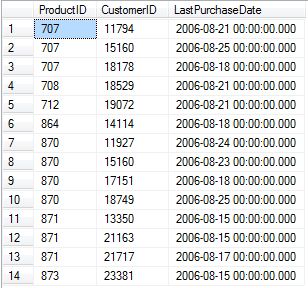
再查询FactBuyingHabits表,可以看到被更新和插入后的结果,如下所示:
<shape id="图片_x0020_6" style="VISIBILITY: visible; WIDTH: 153.75pt; HEIGHT: 2in; mso-wrap-style: square" alt="9.jpg" type="#_x0000_t75" o:spid="_x0000_i1025"><imagedata o:title="9" src="file:///C:%5CUsers%5Czhj%5CAppData%5CLocal%5CTemp%5Cmsohtmlclip1%5C01%5Cclip_image003.jpg"><font color="#000000" size="3"></font></imagedata></shape>
7.SQL 依赖关系报告
SQL Server 2008 引入了新的目录视图和系统函数用以提供一致可靠的 SQL 依赖关系报告。所谓依赖关系,通俗的讲:存储过程1需要使用存储过程2提供的结果,它们之间就是一种依赖关系。可以使用 sys.sql_expression_dependencies、sys.dm_sql_referencing_entities 和 sys.dm_sql_referenced_entities 来报告架构绑定和非架构绑定对象的跨服务器、跨数据库和数据库 SQL 依赖关系。
下例将创建一个表、一个视图和三个存储过程。这些对象将用在后面的查询中以演示如何报告依赖关系信息。可看到 MyView 和 MyProc3 均引用 Mytable。MyProc1 引用 MyView,而 MyProc2 引用 MyProc1。
USE AdventureWorks;
GO
-- Create entities
CREATE TABLE dbo.MyTable (c1 int, c2 varchar(32));
GO
CREATE VIEW dbo.MyView
AS SELECT c1, c2 FROM dbo.MyTable;
GO
CREATE PROC dbo.MyProc1
AS SELECT c1 FROM dbo.MyView;
GO
CREATE PROC dbo.MyProc2
AS EXEC dbo.MyProc1;
GO
CREATE PROC dbo.MyProc3
AS SELECT * FROM AdventureWorks.dbo.MyTable;
EXEC dbo.MyProc2;
GO
下面的示例查询 sys.sql_expression_dependencies 目录视图以返回由 MyProc3 引用的实体。
USE AdventureWorks;
GO
SELECT OBJECT_NAME(referencing_id) AS referencing_entity_name
,referenced_server_name AS server_name
,referenced_database_name AS database_name
,referenced_schema_name AS schema_name
, referenced_entity_name
FROM sys.sql_expression_dependencies
WHERE referencing_id = OBJECT_ID(N'dbo.MyProc3');
GO
下面是结果集:
referencing_entity server_name database_name schema_name referenced_entity
------------------ ----------- ------------- ----------- -- ---------------
MyProc3 NULL NULL dbo MyProc2
MyProc3 NULL AdventureWorks dbo MyTable
上面的查询返回了两个在 MyProc3 定义中按名称引用的实体。服务器名称为 NULL,因为被引用实体没有使用有效的由四部分组成的名称指定。返回的结果中显示了 MyTable 的数据库名称,因为在存储过程中是使用由三部分组成的有效名称定义此实体的。
8.表值参数
数据库引擎引入了可以引用用户定义表类型的新参数类型。表值参数可以将多个数据行发送到 SQL Server 语句或例程(比如存储过程或函数),而不用创建临时表。表值参数具有更高的灵活性,在某些情况下,可比临时表或其他传递参数列表的方法提供更好的性能。表值参数具有以下优势:
首次从客户端填充数据时,不获取锁。
提供简单的编程模型。
允许在单个例程中包括复杂的业务逻辑。
减少到服务器的往返。
可以具有不同基数的表结构。
是强类型。
使客户端可以指定排序顺序和唯一键。
与其他参数一样,表值参数的作用域也是存储过程、函数或动态 Transact-SQL 文本。同样,表类型变量也与使用 DECLARE 语句创建的其他任何局部变量一样具有作用域。
与BULK INSERT操作相比,频繁使用表值参数将比大型数据集要快。大容量操作的启动开销比表值参数大,与之相比,表值参数在插入数目少于 1000 的行时具有很好的执行性能。
下面是SQL Server帮助中的示例,演示了如何执行以下操作:创建表值参数类型,声明变量来引用它,填充参数列表,然后将值传递到存储过程。
USE AdventureWorks;
GO
/* 创建一个table类型 */
CREATE TYPE LocationTableType AS TABLE
( LocationName VARCHAR(50)
, CostRate INT );
GO
/* 创建一个存储过程,用于从表值参数接收数据 */
CREATE PROCEDURE usp_InsertProductionLocation
@TVP LocationTableType READONLY
AS
SET NOCOUNT ON
INSERT INTO [AdventureWorks].[Production].[Location]
([Name]
,[CostRate]
,[Availability]
,[ModifiedDate])
SELECT *, 0, GETDATE()
FROM @TVP;
GO
/* 定义一个引用表值类型的变量 */
DECLARE @LocationTVP
AS LocationTableType;
/* 添加数据到表值变量 */
INSERT INTO @LocationTVP (LocationName, CostRate)
SELECT [Name], 0.00
FROM
[AdventureWorks].[Person].[StateProvince];
/* 传递表值变量数据给存储过程 */
EXEC usp_InsertProductionLocation @LocationTVP;
GO
9.Transact-SQL 行构造函数
增强后的 Transact-SQL 可以允许将多个值插入单个 INSERT 语句中,语法比较简单。参考下面的代码:
/* 创建一个表 */
CREATE TABLE dbo.T1(
CustName char(20) ,
ProductID int ,
MadeFrom char(20) ,
Sales numeric(20, 2)
)
/* 插入2行数据 */
INSERT INTO dbo.T1
VALUES ('Jane',1,'China',20.00),
('Jack',2,'USA',10.00)