Sybase数据库性能调优
Sybase数据库性能调优:http://www.soft6.com/know/detail.asp?id=AJIDDA
广铁集团电算信息中心 王奇成 张南飞
编者按:在现有软硬件条件下,充分发挥数据库系统的潜能(数据库性能调优)是DBA(数据库管理员)追求的最高境界。然而,数据库性能调优是一个非常复杂的问题,不仅需要潜心研究数据库的理论知识,更需要参考同行的实践经验。本期我们特别为DBA选登了一篇有关这方面内容的文章,希望对您的工作有所启迪。文中提到的方法,主要针对Sybase数据库,但对DB2、Oracle等大型数据库系统同样也有借鉴意义。
全国铁路客票系统是一个典型的基于数据库的大型应用系统,经过多次的技术改进,现已能够比较全面充分地满足和适应客票发售和预订的需求,是铁路运输管理信息系统中的重点应用。系统采用Client/Server结构,后台使用Sybase数据库和Unix操作系统,中间由自行开发的中间件负责连接交易处理和数据库通信。
这样一个遍及全国大小车站、统管全国的铁路客票发售系统,其重要性不言而喻。特别是节假日铁路售票高峰期,客票主机一旦出现故障,造成停机,便会直接影响售票,极大地影响铁路正常运营。因此,如何深入调整Sybase数据库的性能,保证数据库的高可用性,以满足日益增长的客票网络的需求,是每一个地区中心和每一个车站的数据库管理员的重要课题。本文将结合铁路客票系统,对如何调整优化Sybase数据库的性能进行较深入的论述。
何谓数据库性能调优
数据库性能一般用两个方面的指标来衡量:响应时间和吞吐量。响应越快,吞吐量越大,数据库性能越好。不过,响应时间和吞吐量并不是都能一起得到改善的。Sybase数据库性能调优可以从四个方面进行:
● 操作系统级:对网络性能、操作系统参数、硬件性能等做改进。
● SQL Server级:调整存取方法,改善内存管理和锁管理等。
● 数据库设计级:采用降范式设计,合理设计索引,分布存放数据等。
● 应用程序级:采用高效SQL语句,合理安排事务,应用游标,处理锁。
本文将对除操作系统级以外的三个方面的内容进行讨论,其中SQL Server部分提到的概念只适用于Sybase数据库,但第三、第四方面讨论的内容同样适用于Sybase外的其他数据库。而且,以上各个方面的措施是相互关连的,具体到解决某一个性能问题,要综合应用。
在分析Sybase数据库的性能时,常要用到一些数据库系统本身提供的性能调优工具,以下是最常用的几个系统存储过程:
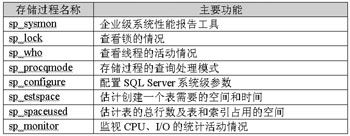
这里要特别提一下sp_sysmon存储过程,通过它可以得到数据库系统的性能基准报告,但只有在比较稳定的状态下产生时,方可作为参考和对照的依据。另外,为了对数据库性能进行调整,需要十分清楚数据库存储数据的底层细节,如数据页、索引页的物理结构、每一行的大小计算、不同类型列占用的宽度等问题,只有具备了这些知识,才能深入领会各种调优措施。
SQL Server级的调优
数据库性能优化的首要问题是内存管理。数据库占用的共享内存分成数据缓冲区(Data Cache)、存储过程缓冲区(Procedure Cache)等几部分。在ISQL下使用 “sp_configure ‘cache’”可以看到存储过程缓冲区所占百分比(Procedure Cache Percent)和整个数据缓冲区大小(Total Data Cache Size) 等参数。
存储过程缓冲区保存有以下对象的查询计划:存储过程、触发器、视图、规则、缺省、游标等。存储过程不可重入,即每个并发用户调用都会在内存中产生一个拷贝。
当存储过程、触发器、视图被装载到存储过程缓冲区时,被查询优化器优化,建立查询计划。如果存储过程在缓冲区中,被调用就不需要重新编译。如果存储过程缓冲区太小,存储过程就会经常被其他调入内存的存储过程覆盖掉,当再次被调用时,存储过程又被调入内存,再重新编译,用户请求因此不得不等待。最严重的情况,如果存储过程缓冲区不够,存储过程甚至都不能运行。所以在内存足够的情况下,存储过程缓冲参数应尽可能大一些。
数据缓冲区用来缓存数据页和索引页,给服务器增加物理内存以扩大数据缓冲区,是提高数据库性能最有效的方法。当然,如果不能增加内存,就只能通过减少存储过程缓冲区的比例等方法来扩大数据缓冲区了。
要把数据提前读入内存,有两种方式,即预取策略或大I/O策略(Prefetch Strategy)和取后马上丢弃策略(Fetch-and-Discard)、提示策略(Hints)等几种。可以在以下三个级别上分别设置表数据的预取策略(Prefetch Strategy,即大I/O策略):对象级、会话级、查询级。如果三个级别上都有设置,它们发生作用的优先顺序是:对象级 > 会话级 > 查询级。
在决策支持系统应用中常常需要较大的I/O,这时应该开放large I/O strategy预取策略。如果一个应用倾向于OLTP特征,用户可以在会话级关掉Prefetch来提高性能。同样,对于OLTP应用,还可关闭large I/O strategy预取策略。如果所取页不会有重用的情况,应开放fetch-and-discard策略。
锁的优化是数据库级调优的另一个重要内容。锁优化最重要的工作是设置页级锁升级成表级锁的阀限。要尽量避免页锁很快升级成表级锁,同时减少锁的争夺。
管理临时库和多引擎(Multiple Network Engines)也是数据库级调优的一个重要内容。管理临时库的一个重要原则是要避免临时表跨多个设备,可以把tempdb从master设备中分离出来,放到一个单独的设备上去。这样可以减少存取系统表时对I/O资源的争夺。多引擎是指操作系统使用了多个CPU。如果有多个CPU,可用sp_configure 来配置数据库的参数:在线引擎数(Max Online Engines)。可以扩展系统的网络I/O容量,将网络I/O分布到各个引擎,从而提高性能,以允许更多的用户连接。
为了改善数据库的性能,设备的优化也必不可少。把最常插入的表分区放在多个设备上,这样可以创建多个页链,从而改善多个并发插入时的性能,因为每一个插入都要找到页链,页链有多个,就允许多个插入同时进行。这一点,尤其适用于客票系统的存根表和订票存根表,所带来的性能改善会非常明显。
物理I/O的代价远大于逻辑I/O,所以要尽量减少磁盘进行物理I/O的次数,尽量多进行内存中的逻辑I/O。可以使用“statistics io”工具和sp_sysmon来观察磁盘I/O。可以配置使用大的I/O来减少物理I/O的次数,方法有三个,分别是用更多的磁盘、表和索引分开到不同的磁盘和增加一次I/O系统参数值的大小。
SQL Server总是为I/O请求建立一个磁盘检查的调度环。用sp_configure“I/O polling process count”来提高数值,加长环,可以降低引擎的检查次数,提高吞吐量。但较小的值一般有助于减少响应时间。
Sybase数据库性能调优
广铁集团电算信息中心 王奇成 张南飞
数据库设计级的调优
在数据库的基础理论中,倡导使用规范化的数据库设计方法,简称范式设计。用范式来设计数据库,可以减少数据冗余度,减少插入、更新和删除异常,也可以提高性能。但是有时为了提高某些特定的性能,有意打破范式设计,这样可以达到最好的效果。但这种情况下,一定要注意数据完整性维护的问题。降范式设计这种方式一般可以提高检索速度,但会略微降低数据修改性能。对于应用开发来说,有些情况下,降范式设计还能简化应用程序的编码。具体而言,降范式设计一般能带来如下好处:减少表连接的需要,减少外部键和索引,减少表的数量,聚合列可以预先计算等。有如下方法可以实现降范式设计:
● 增加冗余列。
● 增加导出列,从一个或多个表的几个列中导出另外一个列。
● 收拢表,几个表合成一个表。
● 复制表,即制作表的副本。
● 将表分开, 分为垂直和水平两种。
水平分开可以考虑把表中不太活跃的数据放置在一个表中,而把经常变动的数据放在另外一个表中。垂直分开则是把多个列分成几组,每一组列成一个表。
但是,降范式设计会带来数据相关性问题,必须仔细考虑。有以下几点措施可以帮助解决:
● 尽量在空闲时刷新只读表。
● 多用批处理。
● 用触发器来维护。
是否要采用降范式设计,必须根据具体应用综合考虑。这种设计理念往往紧密结合具体应用,和应用的相关度很高,所以要求数据库分析员兼具业务分析员的角色。
应用程序级的调优
如何进行应用程序级别的调优,是一个十分复杂的问题,也没有统一的方法,这里是我们通常可以采用的几个方法,供读者参考。
1.有效使用索引
查询条件和索引的配合使用,对SQL语句的性能至关重要。下面是两种常见的情况:
(1)如果查询条件中包括索引的第一个列,而且结果列都在索引列中,系统使用匹配索引定位,会定位到索引的页级,这时可从索引页中直接提取结果,不需要使用数据页。
(2)如果查询条件中不包括索引的第一个列,而且结果列都在索引列中,系统使用非匹配索引扫描,不扫描数据页,从索引页中直接提取结果。这种情况也不使用数据页。
2. 创建高效率查询
可以充分利用索引的where 条件书写格式为 “column operator expression”, 这里的operator 一般是:=, >, <, >=, <=, is null 。而如果operator 是!=、!> ,便不能充分利用索引。
如果要充分利用索引,在 column 中就不要包括函数和其他操作。expression 必须是常量或可以转化成常量。查询优化器认为,between 相当于“ >= ”和“ <=”,“like ''Ger%'' ”相当于“ >= ''Ger'' and < ''Ges''”。但是“ like ''%ber'' ”因为没有给出首字母,就不能转化成这种结果。
在书写SQL语句时,对于表连接的情况,注意尽量少写冗余条件。一般要在SARGs(搜索参数)的列上放置一个索引。如果被查询列都包括在索引列中,这种查询叫索引覆盖查询。这种查询效率比较高,应尽量使用这种查询。在做表连接查询时,在外表的连接列上建立索引,可以大大加快速度。而且,查询速度也和表的排列顺序有关,如果行数大的表放在后面,可以提高速度。
3.孤立级0的妙用
当应用需要较好的并发性,并且近似的查询结果也可接受的情况下,SQL语句可以使用孤立级(Isolation Level 0),尤其是对于有多个处理器环境下的OLTP应用。Isolation Level 0扫描不获取锁,所以不需要内部重扫描,因而大大提高效率。
在客票系统的余票查询应用中,因为余票查询的结果是一个动态而近似的参考数值,只对很短的一段时间内有效,供指导售票之用,不需要很精确,所以对于余票查询模块,包括综合查询中的子功能,计划管理中的子功能,尤其是前台售票中的子功能,采用了孤立级技术,很好地改善了售票高峰期售票程序长久没有反应、相互等待的现象。但需注意,Isolation Level 0忽略查询优化器,依赖惟一索引,所以要慎重创建SQL语句,最好由有丰富经验的程序员来完成。
4.存储过程的重编译
存储过程执行的时候带上参数 “with recompile”, 可以让查询优化器更新查询计划。当在表上增加索引,或者执行了“update statistics”指令后运行 “sp_recomplie table_name”, 则所有依赖于此表的存储过程下次运行时被重新编译,即更新它们的查询计划。如果存储过程中会创建临时表,它总是重新生成查询计划。
当表中被查询计划使用的索引或者对象被删除后,存储过程总会自动重新编译。要注意如有必要,应尽可能经常地编译存储过程,使存储过程的查询计划和数据库的数据存放结构保持一致。
对于客票系统,每次备份删除数据,增加或重建索引后,要执行“update statistics”指令,然后运行 “sp_recomplie table_name”来更新相关存储过程的查询计划。
5.使用游标时的性能考虑
因为游标会引起页级和表级锁,且消耗网络资源,又有较多的处理指令,所以除非必要,尽量不用游标,而采用等价的SQL语句,即使SQL语句会涉及到多个表扫描,仍然会更好。对于客票系统中大量的存储过程,尤其是使用最频繁的取票、取车次等几个存储过程,进行了重点优化,减少了游标的使用。
最后要特别指出的是,在数据库性能调优时,一定要建立周密的调整计划和性能基准报告,不能想到哪一项就调整那一项。有时候,SQL Server级选项的设置还需要重新启动数据库,所以要 规划调整时间,尽量在不影响生产的情况下做完可做的工作,然后利用停机时间做影响全局的工作。在调整数据库性能时,还可能带来影响业务正常运行的风险,所以务必要由经验丰富的管理员慎重实施。