理解Sybase ASE数据库中的索引
一、基本概念
Sybase ASE中主要采用的B树索引。但是出于实际应用和性能方面的考虑,它的索引又进行了细分。B树也只是一个统称。
从大的方向分,可以分为聚簇索引(cluster index)和非聚簇索引(non-cluster index)。
聚簇索引:主要要求各个数据页中数据的存放顺序与键值的存放顺序严格一致,而各数据页呢,以键值顺序链接而成即可。各级的索引页实际上也是按照键值顺序链接而成。基于这样的要求,一张表最多能只能搞一个聚簇索引。
非聚簇索引:数据的存放顺序与键值顺序没什么关系。索引页与数据页之间关联是行级别的。即索引的页子节点中的每一项的键值都对应着行的键值,同时存储着对应于该键值的行地址。从这方向看,它比聚簇索引要多一级索引访问。回想一下,它与B-树索引是不是有相似。
从锁定方案来分,ASE中的表可以分为APL锁表和DOL锁表。
APL锁表:要求锁定索引页的同时,对应的数据页也一同锁定。数据页上的地址链以双向链表的形式出现。
APL锁表的聚簇索引如下图:
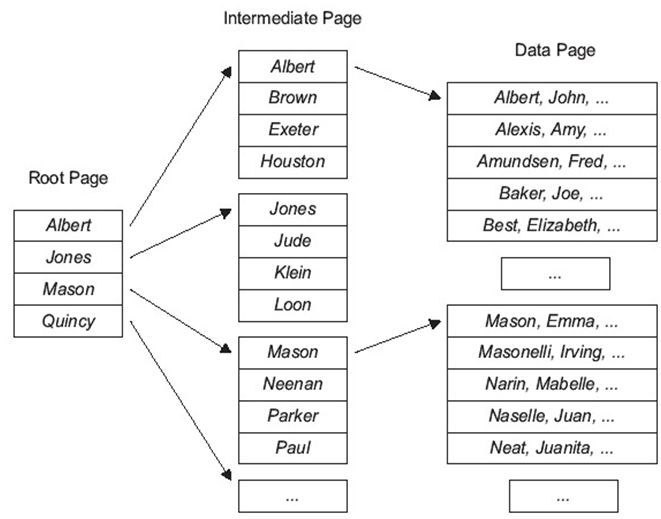
(图1: APL锁表的聚簇索引)
APL锁表的非聚簇索引如图2所示:

图2: APL锁表的非聚簇索引
DOL锁表:只要求锁定数据页或者数据行。它只是在索引页上有双向链表。数据页上则没有这东东。它使用行ID来存储实际的行地址[注:由(页号,行号)组合行成]。
从我个人理解来看,所谓聚簇索引,本质上就是一种B+树(详见数据结构)。B+树的叶节点就要求是数据本身,并且叶节点之间相互有序链接。只不过,对于DOL锁表的聚簇索引来讲,有了一点变化,它的叶节点只是数据的键值,它多了一个指向实际数据行的行地址(数据页号,行号)。加上DOL锁表的物理存储方式很怪异,没有双向链表。
DOL锁表的聚簇索引示例,如图3所示:

图3: DOL锁表的聚簇索引
DOL锁表的非聚簇索引如图4所示:
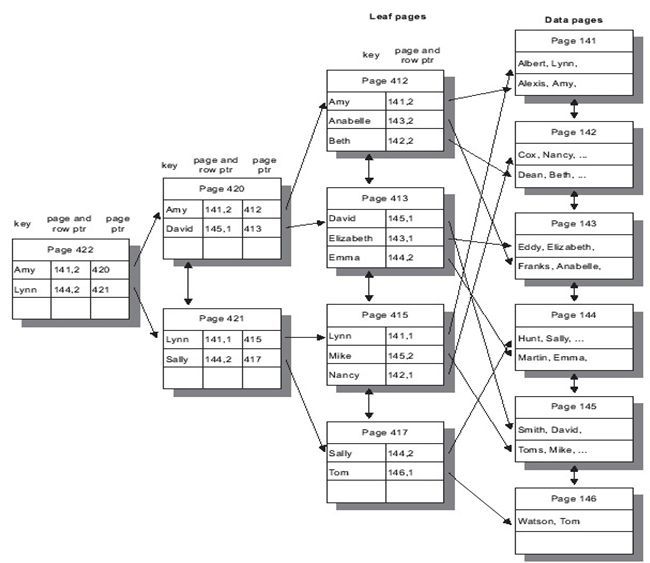
图4: DOL锁表的非聚簇索引
还有一个概念,堆表:它指的就是没有聚簇索引的表,插入数据时,就直接插入到最后一页,直至页满,分配新页,变为最后一页这种方式。
二、数据更新对索引的影响
1. 插入数据
对于APL表:
如果是聚簇索引,它将按照索引的顺序去数据页或索引页调整各行。中间可能涉及到多次页分裂;如果只是普通堆表,那就会在最后一页的最后一个位置放置新行(注意,这个插入操作会锁定该页,多个并发操作都锁定该页什么效果,很容易产生冲突,降低效率,同时只能有一个事务进行插入啊)
对于DOL表:
因没有位置索引,它可以把新行增加到指定的插入页中。即先找到插入页的页号,然后放进去。只要数据不是位于相同的数据页,插入效率应该还是很高的。
2. 删除数据:
APL表:
数据页或叶子页的最后一行被删时,该页也会从页链中删除,并在分配页上标为“可用”。同时,当位于页中的行(索引行、记录行)被删时,位于其后的数据行就会依次上调,以确保剩余空间总是位于该页的最后面。总之,一次删除操作的调整动作可能非常多。
DOL表:
只是逻辑上的将行标识为已删除,但实际上并没有物理删除(有点类似于回收站空间的味道,随着时间往前推移,这种空间会很多,最终需要使用reorg命令来进行重整)如果空间足够,带有位置索引的表会将新行增加到合适的页中,如果空间不足,只好将其放到最靠近的可用页中。
三、索引的选择:
数据的并发插入、更新、删除,可能使用DOL锁会好一些,引起的冲突比APL锁要少。
可是对于查询来讲,如果是使用范围查询或者排序之类的查询,聚簇索引明显好于非聚簇索引。而APL聚簇索引比DOL聚簇索引似乎少了一次索引级访问。
<script type="text/javascript"><!-- google_ad_client = "ca-pub-7104628658411459"; /* wide1 */ google_ad_slot = "8564482570"; google_ad_width = 728; google_ad_height = 90; //--></script><script type="text/javascript" src="http://pagead2.googlesyndication.com/pagead/show_ads.js"></script>