一.理论知识说明
官方文档的说明:
Introduction to Database Replay
http://docs.oracle.com/cd/E11882_01/server.112/e16540/dbr_intro.htm#RATUG104
--这部分内容摘自11g OCP 教材。
1.1 为什么使用数据库重演
大型业务关键应用程序不但复杂,而且负载模式和使用模式也相当多。与此同时,这些业务系统要在响应时间、吞吐量、运行时间和可用性方面提供特定服务级别的保证。对系统的任何更改(如升级数据库或修改配置)通常都需要进行全面的测试和验证,然后才能在生产系统中实施这些更改。在移到生产系统之前为了保证安全,数据库管理员(DBA) 需要让测试系统承受与生产环境中的工作量很近似的工作量。DBA 使用一种有效的方式分析系统级更改对整体SQL 性能的影响也很有益处,因为这样便可以在生产之前对更改执行任何必要的优化。
为什么使用数据库重放:
(1) 系统更改(如硬件和软件升级)是不可避免的。
(2) 客户需要在实施更改前确定更改的全面影响。
(3) 大量的测试和验证可能会花费很多的时间和资金。
(4) 测试除了成本昂贵之外,成功率还很低:
a) 许多问题未被检测到。
b) 更改可能会对系统的可用性和性能产生负面影响。
(5) 成功率低的原因:
a) 无法使用实际的生产工作量进行正确的测试,有许多问题未被检测到。
(6) 数据库重放功能使您可以执行与实际情况相符合的测试。
1.2 数据库重演
通过数据库重放,在将实际的工作量放到生产系统之前,可以在测试系统上重放实际工作量,从而测试系统更改的影响。记录数据库服务器在一段有代表性的时段(例如高峰期间)内的生产工作量(包括事务处理并发度和相关性)。此记录数据用于在经过适当配置的测试系统上重放工作量。通过在测试系统中使数据库服务器承受与生产工作量几乎相同的工作量,可以在数据库更改获得整体成功方面获得高度的信心。
数据库重放:
(1) 在测试环境中重新创建实际的生产数据库工作量。
(2) 在生产中实施更改之前,确定和分析潜在的不稳定性。
(3) 捕获生产中的工作量:
a) 捕获带有实际负载和并发度的完整生产工作量
b) 将捕获的工作量移到测试系统
(4) 在测试中重放工作量:
a) 在测试系统中进行所需的更改
b) 重放带有生产负载和并发度的工作量
c) 采用提交顺序
(5) 分析和报告:
a) 错误
b) 数据差异
c) 性能差异
1.3 系统体系结构:捕获
一般情况下,可通过重放记录来确定升级到新版本的RDBMS 服务器是否安全。在系统中运行生产工作量时,内置到RDBMS 中的一种特殊记录基础结构可以记录有关所有外部客户机请求的数据。外部请求包括所有SQL 查询、PL/SQL 块、PL/SQL远程过程调用、DML 语句、DDL 语句、对象导航请求或Oracle Call Interface (OCI) 调用。
在记录过程中,后台作业以及通常情况下的所有内部客户机将继续工作,不会被记录。最终结果是一份工作量记录,其中包含重放工作量所必需的全部信息;RDBMS 可通过外部请求来查看这些信息。
记录基础结构只会对记录系统造成最低的性能开销(额外的CPU、内存和输出/输出)。但是,应计划配备额外的磁盘空间用于记录实际工作量。
RAC 说明:
RAC 环境中的实例可以访问公用数据库文件。但是,它们不需要共享公用的通用文件系统。在这样的环境中,工作量记录会在记录过程中写入各个实例的文件系统。为了进行处理和重放,需要将工作量记录的所有部分手动复制到单个目录中。

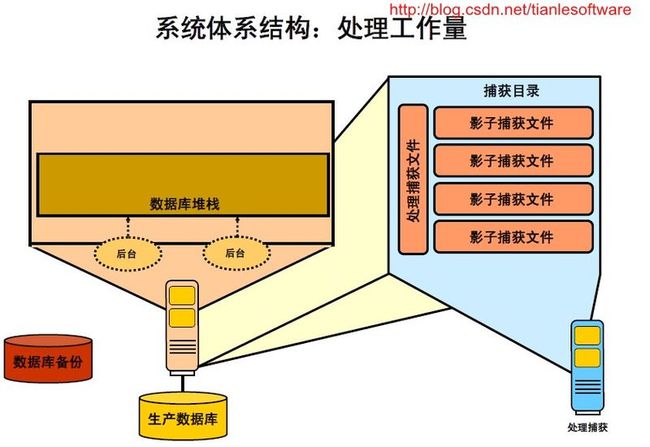
1.4 系统体系结构:处理工作量
处理工作量捕获数据,创建特定于新工作量重放的元数据文件,这是重放指定工作量捕获所必需的。仅创建新文件,而不对工作量捕获过程中创建的任何文件进行修改。因此,可以对相同的捕获目录多次运行预处理(例如,过程遇到意外错误或被取消时)。
在此阶段中,将重新映射外部客户机连接。可以修改会影响重放结果的所有重放参数。
注:
因为处理工作量捕获的成本可能相对较高,所以最好的做法是在生产数据库系统以外的某个系统中执行该操作。
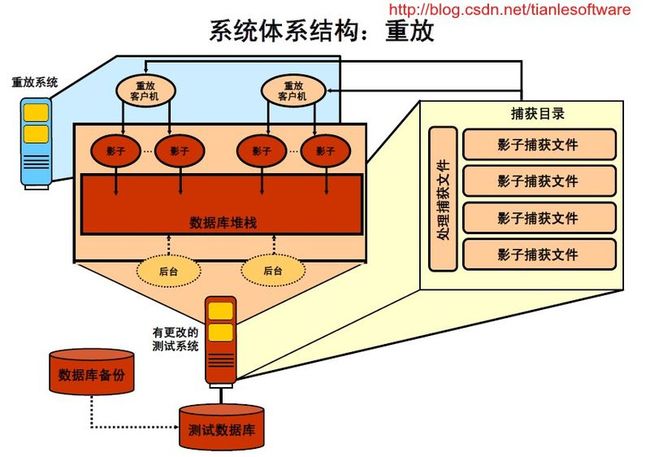
1.5 系统体系结构:重放
在重放系统中重放工作量之前,务必执行以下操作:
1. 在测试系统中还原重放数据库,以便与工作量捕获开始时的捕获数据库匹配。
2. 根据需要更改测试系统(如执行升级等)。
3. 将工作量复制到测试系统。
一个名为“重放驱动程序”的特殊应用程序将使用工作量记录,向在其中重放工作量的RDBMS 发送请求。该RDBMS 通常是一个测试系统。假定重放系统的数据库适合于重放已记录的工作量。不会重放内部RDBMS 客户机。重放驱动程序是一种特殊客户机,它使用工作量记录并向测试系统发送相应的请求,其行为与记录工作量过程中使用的客户机在发送外部请求时的行为相同(参见前面的示例)。使用其行为与RDBMS 的唯一外部客户机相同的特殊驱动程序,可以记录和重放客户机不可知的基础结构。
重放驱动程序包含一个或多个连接到重放系统的客户机,并且可以根据工作量捕获发送请求。重放驱动程序可以根据网络带宽、CPU 和内存容量,在所有重放客户机之间均匀分配工作量捕获流。
1.6 更改前生产系统
数据库重放侧重于记录和重放RDBMS所承受的工作量。因此,记录工作量的操作是在图中所示的位置完成的。在软件堆栈中的RDBMS 上进行记录可实现此级别以下的所有项目交换,并可使用记录和重放功能测试新的设置。
在重放工作量时,RDBMS 将执行记录过程中发现的操作。也就是说,RDBMS 代码在重放阶段的行为方式与记录阶段的行为方式非常相似。这是通过重新创建所有外部客户机对RDBMS 的请求实现的。外部客户机请求包括了RDBMS 的所有可能的外部客户机发出的请求。

1.7 支持的工作量
1.7.1 支持的工作量:
– 包含几乎所有类型的绑定的所有SQL(DML、DDL、PL/SQL)
– 完整的LOB 功能(基于游标和直接OCI)
– 本地事务处理
– 登录和注销
– 会话切换
– 有限的PL/SQL RPC
1.7.2 限制:
– 直接路径加载、导入/导出
– 基于OCI 的对象导航(ADT) 和REF 绑定
– 流、非基于PL/SQL 的AQ
– 分布式事务处理、远程描述/提交操作
– 闪回(数据库和查询)
– 共享服务器
注:
也会捕获基于SQL 的XML 操作。系统仅捕获显式的SQL 语句(客户机发布的SQL 语句)。不会捕获数据库本身生成的隐式调用。例如,审计是隐式的,类似后台进程活动是隐式的。
1.8 捕获注意事项
在工作量记录的计划阶段要执行以下任务:
(1) 检查数据库备份策略,确保在记录开始时数据库可被还原为StartSCN。
(2) 计划捕获期间:根据应用情况和峰值期间选择捕获期间。可以使用现有的可管理性功能,如自动工作量资料档案库(AWR) 和活动会话历史记录(ASH),根据工作量历史记录选择一个恰当的期间。应谨慎计划捕获的开始时间,因为建议的操作是在捕获开始前关闭并重新启动数据库。
(3) 指定工作量捕获数据的位置。必须设置用于存储工作量捕获数据的目录。应提供充足的磁盘空间,因为磁盘空间不足时记录会停止。但是,在停止之前捕获的所有内容仍可用于重放。
(4) 定义捕获过滤器,过滤掉不捕获的用户会话。可以指定记录过滤器以跳过不应捕获的会话。
(5) 数据库重放功能没有引入任何新的权限或用户角色。记录用户和重放用户必须具有SYSDBA 权限或SYSOPER 权限。这是因为仅具备SYSOPER 权限或SYSDBA 权限的用户才可以启动或关闭开始记录的数据库。还应分配正确的操作系统(OS)权限,以便用户能够访问记录、重放目录以及操作这些目录下的文件。
捕获注意事项:
计划:
(1) 为捕获的工作量(二进制文件)留出足够的磁盘空间
(2) 数据库重新启动:
a) 确保重放与实际情况相符的唯一方式
i. 启动限制
ii. 捕获将取消限制
b) 可能不是必需的(取决于工作量)
(3) 还原数据库以进行重放的一种方式:
a) 物理还原(提供顺序/时间)
b) 逻辑还原应用程序数据
c) 闪回/快照备用
(4) 可以指定过滤器来捕获部分工作量
(5) SYSDBA 或SYSOPER 权限和相应的OS 权限
开销:
(1) TPCC 的性能开销为4.5%
(2) 内存开销:每个会话64 KB
(3) 磁盘空间
1.9 重放注意事项
预处理阶段是必需的针对指定数据库版本的一次性操作。创建了必需的元数据以后,可以按需要多次重放工作量。
必须还原重放数据库,以便与工作量捕获开始时的捕获数据库匹配。成功的重放取决于应用程序事务处理,该事务处理要访问与捕获系统上的数据相同的应用程序数据。可以选择使用时间点恢复、闪回和导入/导出来还原应用程序数据。
捕获的工作量可能包含对仅在捕获环境中才有意义的外部系统的引用。如果工作量包含对外部系统的未解析引用,重放该工作量可能会在生产环境中导致意外问题。
应在一个完全孤立的测试环境中执行重放。应确保对外部系统的所有引用都已在重放环境中得到解析,这样重放工作量才不会危害生产环境。
可以进行一对一或多对一重新映射。例如,在捕获的生产环境中的数据库链接可以引用不应在重放过程中引用的外部生产数据库。因此,应修改在重放过程中可能会危害生产环境的所有外部引用。
重放客户机(名为wrc 的可执行程序)将提交捕获的会话的工作量。应安装一个或多个重放客户机,最好安装在生产主机以外的其它系统上。每个重放客户机都必须能访问保存预处理的工作量的目录。
也可以修改重放参数以更改重放的行为。
重放注意事项:
1. 预处理捕获的工作量:
a) 一次性的操作
b) 在与重放时使用版本相同的DB 版本上
c) 如果版本匹配,可在任何位置(生产系统、测试系统或其它系统)执行
2. 还原数据库,然后执行更改:
a) 升级
b) 方案更改
c) OS 更改
d) 硬件更改
e) 添加实例
3. 管理外部交互
a) 重新映射用于工作量的连接字符串:
i. 一对一:用于简单的实例对实例重新映射
ii. 多对一:使用负载平衡器(如单节点对RAC)
b) 修改指向生产系统的DB 链接和目录对象
4. 设置一个或多个重放客户机
a) 都可以驱动多个工作量会话的多线程客户机
1.10 重放选项
在重放工作量的过程中,可以修改以下重放选项:
(1) synchronization 参数将确定在重放工作量时是否使用同步。如果将此参数设置为TRUE,则重放时将保留捕获的工作量中的COMMIT 顺序,并且所有重放操作都仅在相关COMMIT 操作全部完成后才能执行。默认值为TRUE。
(2) think_time_scale 参数将确定同一会话中两个连续的用户调用之间的占用时间范围;该参数以百分比值形式表示。使用此参数可提高或降低重放速度。将此参数设置为0 在重放时将以尽可能快的速度将用户调用发送给数据库。默认值为100。
(3) 如果重放时完成用户调用所需的时间比捕获时所需的时间长,则think_time_auto_correct 参数可以更正调用之间的考虑时间(根据think_time_scale参数)。此参数的值可以为TRUE 或FALSE。
(4) connect_time_scale 参数确定了从开始工作量捕获到会话与指定值连接之间的占用时间范围;该参数值以百分比形式表示。使用此选项可以控制重放过程中的会话连接时间。默认值为100。
注:
在工作量捕获过程中,占用时间通过用户时间和用户考虑时间来度量。用户时间是用户调用数据库的占用时间。用户考虑时间是在发布的调用之间用户用于等待的占用时间。
在重放工作量过程中,占用时间是通过用户时间、用户考虑时间和同步时间来度量的。
重放选项:
1. 同步的重放:
a) 确保数据差异最小
b) 基于提交的同步
2. 不同步的重放:
a) 可用于负载/压力测试
b) 不考虑原始提交顺序
c) 数据差异大
3. 考虑时间选项:
a) 自动(默认值)
b) 调整考虑时间以保持捕获的请求率:
i. 0%:无考虑时间(最高的可能请求率)
ii. <100%:较高的请求率
iii. 100%:精确的考虑时间
iv. >100%:较低的请求率
4. 登录时间选项
a) 百分比(默认值为100%)
1.11 重放分析
与记录的内容比较,重放可能会有一些差异。例如,在较新版本的RDBMS 上重放时,新的算法可能会导致特定请求的速度变快,从而出现执行时速度较快的差异。这种差异是用户所需要的。差异的另一个示例是,重放过程中SQL 语句返回的行数少于记录过程中返回的行数。这种差异显然不是用户所需要的。
对于数据差异,可以将某个操作的结果看成:
(1) SQL 查询的结果集
(2) 对持久数据库状态的更新
(3) 返回代码或错误代码
在确定重放系统中引入的新算法会对整体性能产生怎样的影响时,性能差异很有用。可能导致重放差异的因素有很多。虽然有些差异无法控制,但其它差异是可以缓解的。DBA应负责了解工作量运行时操作,并采取必要的措施来降低记录和播放差异的程度。
联机差异有助于决定停止会造成显著差异的重放。差异出现之前的重放结果可能仍然有用,但继续重放则不会生成可靠的结论。脱机差异报告用于确定重放完成后重放的成功情况。
重放的数据差异包含了查询和错误的结果。也就是说,记录过程中发生的错误将被当成正确的结果,重放过程中的任何更改都会被报告。可以使用现有的工具(如ADDM)来度量记录系统与重放系统之间的性能差异。
此外,重放过程中的错误比较报表可以报告以下内容:
• 记录过程中未出现的错误
• 重放过程中未重现的错误
• 错误类型方面的差异
重放分析:
• 数据差异
– 每个调用(查询、DML)比较的行数
• 错误差异:
– 新错误
– 变异的错误
– 已消失的错误
• 性能:
– 捕获和重放报表
– ADDM 报表
– 用于偏差分析的ASH 报表
– AWR 报表
二.Database Replay 示例
2.1 捕获(Capture) --生产库
DBMS_WORKLOAD_CAPTURE包提供了一些列的过程和函数来控制capture 进程。
2.1.1 创建目录存放capture 日志
在生产库上创建如下目录:
[root@dave ~]# su - oracle
[oracle@dave ~]$ mkdir/u01/app/oracle/db_replay_capture
连接实例,创建directory:
[oracle@dave ~]$ ora si
SQL*Plus: Release 11.2.0.3.0 Production onWed Oct 10 18:57:05 2012
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise EditionRelease 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Miningand Real Application Testing options
SQL> CREATE OR REPLACE DIRECTORYdb_replay_capture_dir AS '/u01/app/oracle/db_replay_capture/';
Directory created.
SQL> SHUTDOWN IMMEDIATE
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> STARTUP
ORACLE instance started.
Total System Global Area 730714112 bytes
Fixed Size 2231952 bytes
Variable Size 285213040 bytes
Database Buffers 419430400 bytes
Redo Buffers 23838720 bytes
Database mounted.
Database opened.
SQL>
注意:
这里的shutdown 和startup 操作不是必须的操作。 但是Oracle 建议我们执行这个操作。 这样可以确保我们在开始captureprocess 之前,其他的outstanding processes已经执行完毕。
2.1.2 创建Filter
结合ADD_FILTER 过程和START_CAPTURE 过程的DEFAULT_ACTION 参数,通过对如下属性的including或者excluding的设置,来定制我们自己的workload。
(1) INSTANCE_NUMBER
(2) USER
(3) MODULE
(4) ACTION
(5) PROGRAM
(6) SERVICE
Add_filer的使用示例:
SQL> execdbms_workload_capture.ADD_FILTER( fname IN VARCHAR2, fattribute IN VARCHAR2,fvalueIN VARCHAR2);
fname=Name of the filter.
fattribute=Attribute on which the filter will be applied i.e USER, PROGRAM,INSTANCE_NUMBER etc.
--就是我们上面列的6个属性。
fvalue= value for the corresponding attribute.
如:
SQL > exec dbms_workload_capture.ADD_FILTER(fname =>'FILTER_SCOTT',fattribute => 'USER',fvalue => 'SCOTT');
这里为了简单,假设我们capture 所有的信息,就跳过add_filter 的设置。
2.1.3 运行Capture
运行START_CAPTURE 过程时,需要指定capture 名称,directory 和capture 进程运行的时间。 如果duration设置为NULL,则captureprocess 必须等我们手工调用FINISH_CAPTURE 过程来结束。
具体操作如下:
SQL> BEGIN
2 DBMS_WORKLOAD_CAPTURE.start_capture (name => 'test_capture_1',
3 dir =>'DB_REPLAY_CAPTURE_DIR',
4 duration => NULL);
5 END;
6 /
PL/SQL procedure successfully completed.
--运行这个过程,必须要具有SYSDBA和SYSOPER的用户来执行。
2.1.4 做一些变更操作
--创建用户:
SQL> CREATE USER anqing IDENTIFIED BYanqing QUOTA UNLIMITED ON users;
User created.
SQL> GRANT CONNECT, CREATE TABLE TOanqing;
Grant succeeded.
--插入数据:
SQL> conn anqing/anqing;
Connected.
SQL> CREATE TABLE db_replay_test_tab (
2 id NUMBER,
3 description VARCHAR2(50),
4 CONSTRAINTdb_replay_test_tab_pk PRIMARY KEY (id)
5 );
Table created.
SQL> BEGIN
2 FOR i IN 1 .. 500000 LOOP
3 INSERT INTOdb_replay_test_tab (id, description)
4 VALUES (i, 'Description for' || i);
5 END LOOP;
6 COMMIT;
7 END;
8 /
PL/SQL procedure successfully completed.
2.1.5 停止 capture
SQL> conn / as sysdba
Connected.
SQL> BEGIN
2 DBMS_WORKLOAD_CAPTURE.finish_capture;
3 END;
4 /
PL/SQL procedure successfully completed.
2.1.6 检查capture 目录
[oracle@dave ~]$ cd/u01/app/oracle/db_replay_capture
[oracle@dave db_replay_capture]$ ls
cap capfiles
[oracle@dave db_replay_capture]$ cd cap
[oracle@dave cap]$ ls
wcr_cr.html wcr_cr.text wcr_fcapture.wmd wcr_scapture.wmd
[oracle@dave cap]$ cd ..
[oracle@dave db_replay_capture]$ tree
.
|-- cap
| |-- wcr_cr.html
| |-- wcr_cr.text
| |-- wcr_fcapture.wmd
| `-- wcr_scapture.wmd
`-- capfiles
`-- inst1
|-- aa
| |-- wcr_7aq7rh000000c.rec
| |-- wcr_7aq8qh000000d.rec
| `-- wcr_7aqfhh000000r.rec
|-- ab
|-- ac
|-- ad
|-- ae
|-- af
|-- ag
|-- ah
|-- ai
`-- aj
13 directories, 7 files
[oracle@dave db_replay_capture]$
当capture process 进程正在运行时会生成2个文件: wcr_scapture.wmd 和 wcr_cap_000xx.start。
当finish capture后,还会得到得到另外2个文件: wcr_cr.html 和 wcr_cr.text,wcr_cr.html 文件和 AWR report 类似。
2.1.7 获取capture ID
有两种方法:
(1)使用GET_CAPTURE_INFO 函数
SQL> SELECTDBMS_WORKLOAD_CAPTURE.get_capture_info('DB_REPLAY_CAPTURE_DIR') FROM dual;
DBMS_WORKLOAD_CAPTURE.GET_CAPTURE_INFO('DB_REPLAY_CAPTURE_DIR')
---------------------------------------------------------------
1
(2)使用DBA_WORKLOAD_CAPTURES视图
SQL> COLUMN name FORMAT A30
SQL> SELECT id, name FROMdba_workload_captures;
ID NAME
---------- ------------------------------
1 test_capture_1
SQL> desc dba_workload_captures
Name Null? Type
------------------------------------------------- ----------------------------
ID NOTNULL NUMBER
NAME NOT NULLVARCHAR2(100)
DBID NOT NULLNUMBER
DBNAME NOT NULLVARCHAR2(10)
DBVERSION NOT NULL VARCHAR2(30)
PARALLEL VARCHAR2(3)
DIRECTORY NOT NULLVARCHAR2(30)
STATUS NOT NULLVARCHAR2(40)
START_TIME NOT NULL DATE
END_TIME DATE
DURATION_SECS NUMBER
START_SCN NOT NULLNUMBER
END_SCN NUMBER
DEFAULT_ACTION NOT NULLVARCHAR2(30)
FILTERS_USED NUMBER
CAPTURE_SIZE NUMBER
DBTIME NUMBER
DBTIME_TOTAL NUMBER
USER_CALLS NUMBER
USER_CALLS_TOTAL NUMBER
USER_CALLS_UNREPLAYABLE NUMBER
TRANSACTIONS NUMBER
TRANSACTIONS_TOTAL NUMBER
CONNECTS NUMBER
CONNECTS_TOTAL NUMBER
ERRORS NUMBER
AWR_DBID NUMBER
AWR_BEGIN_SNAP NUMBER
AWR_END_SNAP NUMBER
AWR_EXPORTED VARCHAR2(12)
ERROR_CODE NUMBER
ERROR_MESSAGE VARCHAR2(300)
DIR_PATH NOT NULLVARCHAR2(4000)
DIR_PATH_SHARED NOT NULLVARCHAR2(10)
LAST_PROCESSED_VERSION VARCHAR2(30)
SQLSET_OWNER VARCHAR2(30)
SQLSET_NAME VARCHAR2(30)
DBA_WORKLOAD_CAPTURES 视图包含了capture 进程的一些信息,我们可以通过查询该视图来获取capture 的信息。或者,我们也可以使用report 函数生成一个text 或者html 格式的报告来查看。
如下:
DECLARE
l_report CLOB;
BEGIN
l_report := DBMS_WORKLOAD_CAPTURE.report(capture_id => 1,
format =>DBMS_WORKLOAD_CAPTURE.TYPE_HTML);
END;
/
并且使用这个capture ID,也可以导出该Capture ID 对应的AWR 快照。如:
BEGIN
DBMS_WORKLOAD_CAPTURE.export_awr (capture_id => 1);
END;
/
该过程执行时,会生成2个文件:wcr_ca.dmp 和 wcr_ca.log。
查看capture 目录,会显示多一个dump和相关的log 文件:
[oracle@dave db_replay_capture]$ tree
.
|-- cap
| |-- wcr_ca.dmp
| |-- wcr_ca.log
| |--wcr_cr.html
| |-- wcr_cr.text
| |-- wcr_fcapture.wmd
| `-- wcr_scapture.wmd
`-- capfiles
`-- inst1
|-- aa
| |-- wcr_7aq7rh000000c.rec
| |-- wcr_7aq8qh000000d.rec
| `-- wcr_7aqfhh000000r.rec
|-- ab
|-- ac
|-- ad
|-- ae
|-- af
|-- ag
|-- ah
|-- ai
`-- aj
13 directories, 9 files
2.2 处理工作量(WorkloadPreprocessing)--测试库
2.2.1 创建目录并copy capture 文件
在测试库上创建目录,并将生产库上产生的capture 文件copy 过来。
[oracle@dave ~]$ mkdir/u01/app/oracle/db_replay_capture
[oracle@dave ~]$ scp -r 192.168.1.10:/u01/app/oracle/db_replay_capture/*/u01/app/oracle/db_replay_capture
[email protected]'s password:
wcr_scapture.wmd 100% 98 0.1KB/s 00:00
wcr_cap_uc_graph.extb 100% 12KB 12.0KB/s 00:00
wcr_fcapture.wmd 100% 188 0.2KB/s 00:00
wcr_cr.html 100% 30KB 29.6KB/s 00:00
wcr_ca.dmp 100% 7288KB 7.1MB/s 00:01
wcr_ca.log 100% 15KB 15.2KB/s 00:00
wcr_cr.text 100% 11KB 10.6KB/s 00:00
wcr_7aq8qh000000d.rec 100% 4020 3.9KB/s 00:00
wcr_7aq7rh000000c.rec 100%1984 1.9KB/s 00:00
wcr_7aqfhh000000r.rec 100% 1614 1.6KB/s 00:00
[oracle@dave ~]$ cd/u01/app/oracle/db_replay_capture/
[oracle@dave db_replay_capture]$ tree
.
|-- cap
| |-- wcr_ca.dmp
| |-- wcr_ca.log
| |-- wcr_cr.html
| |-- wcr_cr.text
| |-- wcr_fcapture.wmd
| `-- wcr_scapture.wmd
`-- capfiles
`-- inst1
|-- aa
| |-- wcr_7aq7rh000000c.rec
| |-- wcr_7aq8qh000000d.rec
| `-- wcr_7aqfhh000000r.rec
|-- ab
|-- ac
|-- ad
|-- ae
|-- af
|-- ag
|-- ah
|-- ai
`-- aj
13 directories, 9 files
2.2.2 实例中创建directory
[oracle@dave ~]$ ora si
SQL*Plus: Release 11.2.0.3.0 Production onWed Oct 10 19:54:27 2012
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise EditionRelease 11.2.0.3.0 - 64bit Production
With the Partitioning, OLAP, Data Miningand Real Application Testing options
SQL> CREATE OR REPLACE DIRECTORYdb_replay_capture_dir AS '/u01/app/oracle/db_replay_capture/';
Directory created.
2.2.3 处理工作量
使用PROCESS_CAPTURE过程来准备capture logs。
BEGIN
DBMS_WORKLOAD_REPLAY.process_capture('DB_REPLAY_CAPTURE_DIR');
END;
/
执行完毕后,会生成wcr_process.wmd,wcr_login.pp, wcr_seq_data.extb, wcr_scn_order.extb , wcr_conn_data.extb等文件。
[oracle@dave db_replay_capture]$ tree
.
|-- cap
| |-- wcr_ca.dmp
| |-- wcr_ca.log
| |-- wcr_cr.html
| |-- wcr_cr.text
| |-- wcr_fcapture.wmd
| `-- wcr_scapture.wmd
|-- capfiles
| `-- inst1
| |-- aa
| | |-- wcr_7aq7rh000000c.rec
| | |-- wcr_7aq8qh000000d.rec
| | `-- wcr_7aqfhh000000r.rec
| |-- ab
| |-- ac
| |-- ad
| |-- ae
| |-- af
| |-- ag
| |-- ah
| |-- ai
| `-- aj
|-- pp11.2.0.3.0
| |-- wcr_calibrate.xml
| |-- wcr_commits.extb
| |-- wcr_conn_data.extb
| |-- wcr_data.extb
| |-- wcr_dep_graph.extb
| |-- wcr_login.pp
| |-- wcr_process.wmd
| |-- wcr_references.extb
| |-- wcr_scn_order.extb
| `-- wcr_seq_data.extb
`-- rep35546834
15 directories, 19 files
2.3 重演(Replay)--测试库
2.3.1 使用wrc 工具效验
效验结果会显示完成replay需要replayclents和hosts的数量。
[oracle@dave /]$ wrc mode=calibratereplaydir=/u01/app/oracle/db_replay_capture
Workload Replay Client: Release 11.2.0.3.0- Production on Wed Oct 10 20:12:32 2012
Copyright (c) 1982, 2011, Oracle and/or itsaffiliates. All rights reserved.
Report for Workload in:/u01/app/oracle/db_replay_capture
-----------------------
Recommendation:
Consider using at least 1clients divided among 1 CPU(s)
You will need at least 3 MB of memory perclient process.
If your machine(s) cannot match thatnumber, consider using more clients.
Workload Characteristics:
- max concurrency: 1 sessions
- total number of sessions: 3
Assumptions:
- 1 client process per 50 concurrentsessions
- 4 client process per CPU
- 256 KB of memory cache per concurrentsession
- think time scale = 100
- connect time scale = 100
- synchronization = TRUE
2.3.2 开始replay
在上面的效验结果,显示一个CPU 上建议一个clint,所以我们这里开始一个replay clint。
--使用Initializing replay 装载metadata到tables里:
EXEC DBMS_WORKLOAD_REPLAY.initialize_replay (replay_name => 'test_capture_1', replay_dir => 'DB_REPLAY_CAPTURE_DIR');
--将数据改成PREPARE REPLAY 模式:
execDBMS_WORKLOAD_REPLAY.prepare_replay (synchronization => TRUE);
--检查replay的状态:
SQL> set lin 160
SQL> col name for a20
SQL> col status for a20
SQL> select name,status from dba_workload_replays;
NAME STATUS
-------------------- --------------------
test_capture_1 PREPARE
[oracle@dave /]$ wrc system/oraclemode=replay replaydir=/u01/app/oracle/db_replay_capture
Workload Replay Client: Release 11.2.0.3.0- Production on Wed Oct 10 20:31:39 2012
Copyright (c) 1982, 2011, Oracle and/or itsaffiliates. All rights reserved.
Wait for the replay to start (20:38:31)
--执行之后,replay client 被暂停,并等待start replay 。 另开一个sqlplus 窗口执行如下命令:
SQL> execDBMS_WORKLOAD_REPLAY.START_REPLAY ();
SQL> select name,status from dba_workload_replays;
NAME STATUS
-------------------- --------------------
test_capture_1 IN PROGRESS
--如果希望在完成replay 前stopreplay过程,调用CANCEL_REPLAY 过程即可。
SQL> execDBMS_WORKLOAD_REPLAY.CANCEL_REPLAY ();
--取消后在replay client 窗口会显示:
Errors in file :
ORA-15509: workload replay has beencancelled
--返回replay clint窗口,等dba_workload_replays中的状态变成compelte就完成replay。此时replayclient会显示操作开始和结束的时间:
[oracle@dave /]$ wrc system/oracle mode=replayreplaydir=/u01/app/oracle/db_replay_capture
Workload Replay Client: Release 11.2.0.3.0- Production on Wed Oct 10 20:38:31 2012
Copyright (c) 1982, 2011, Oracle and/or itsaffiliates. All rights reserved.
Wait for the replay to start (20:38:31)
Replay started (20:38:46)
Replay finished(20:45:12)
--插曲:
我这里在第一次进行replay的时候,失败,replay client 显示:
Errors in file :
ORA-15568: login of user ANQING duringworkload replay failed with ORA-1435
[oracle@dave db_replay_capture]$ oerr ora1435
01435, 00000, "user does notexist"
// *Cause:
// *Action:
这里提示anqing的用户不存在,根据签名的说明,database replay 是支持DDL操作的。 后来我手工在测试库上创建了用户,然后重新进行了一次replay,才成功。
2.3.3 验证replay
SQL> conn anqing/anqing;
Connected.
SQL> select count(1) fromdb_replay_test_tab;
COUNT(1)
----------
500000
这里数据是ok的。
2.3.4 查看replay 信息
可以使用DBA_WORKLOAD_REPLAYS视图来查看replay 进程的相关信息,并根据capture ID 生成报告。
SQL> conn /as sysdba
Connected.
SQL> COLUMNname FORMAT A30
SQL> SELECTid, name FROM dba_workload_replays;
ID NAME
----------------------------------------
1 test_capture_1
12 test_capture_1
21 test_capture_1
33 test_capture_1
--生成报告:
DECLARE
l_report CLOB;
BEGIN
l_report := DBMS_WORKLOAD_REPLAY.report(replay_id => 33,
format =>DBMS_WORKLOAD_REPLAY.TYPE_HTML);
END;
/
--capture 目录:
[oracle@dave db_replay_capture]$ tree
.
|-- cap
| |-- wcr_ca.dmp
| |-- wcr_ca.log
| |-- wcr_cr.html
| |-- wcr_cr.text
| |-- wcr_fcapture.wmd
| `-- wcr_scapture.wmd
|-- capfiles
| `-- inst1
| |-- aa
| | |-- wcr_7aq7rh000000c.rec
| | |-- wcr_7aq8qh000000d.rec
| | `-- wcr_7aqfhh000000r.rec
| |-- ab
| |-- ac
| |-- ad
| |-- ae
| |-- af
| |-- ag
| |-- ah
| |-- ai
| `-- aj
|-- pp11.2.0.3.0
| |-- wcr_calibrate.xml
| |-- wcr_commits.extb
| |-- wcr_conn_data.extb
| |-- wcr_data.extb
| |-- wcr_dep_graph.extb
| |-- wcr_login.pp
| |-- wcr_process.wmd
| |-- wcr_references.extb
| |-- wcr_scn_order.extb
| `-- wcr_seq_data.extb
|-- rep35546834
| |-- wcr_ra_35546834.dmp
| |-- wcr_ra_35546834.log
| |-- wcr_replay.wmd
| |-- wcr_rep_uc_graph_35546834.extb
| `-- wcr_rr_35546834.xml
|-- rep650437870
| |-- wcr_ra_650437870.dmp
| |-- wcr_ra_650437870.log
| |-- wcr_replay.wmd
| |-- wcr_rep_uc_graph_650437870.extb
| `-- wcr_rr_650437870.xml
`-- rep968319046
|-- wcr_ra_968319046.dmp
|-- wcr_ra_968319046.log
|-- wcr_replay.wmd
|-- wcr_rep_uc_graph_968319046.extb
`-- wcr_rr_968319046.xml
17 directories, 34 files