FP-Tree算法的实现
在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库。于是人们提出了各种裁剪(prune)数据集的方法以减少I/O开支,韩嘉炜老师的FP-Tree算法就是其中非常高效的一种。
支持度和置信度
严格地说Apriori和FP-Tree都是寻找频繁项集的算法,频繁项集就是所谓的“支持度”比较高的项集,下面解释一下支持度和置信度的概念。
设事务数据库为:
A E F G
A F G
A B E F G
E F G
则{A,F,G}的支持度数为3,支持度为3/4。
{F,G}的支持度数为4,支持度为4/4。
{A}的支持度数为3,支持度为3/4。
{F,G}=>{A}的置信度为:{A,F,G}的支持度数 除以{F,G}的支持度数,即3/4
{A}=>{F,G}的置信度为:{A,F,G}的支持度数 除以{A}的支持度数,即3/3
强关联规则挖掘是在满足一定支持度的情况下寻找置信度达到阈值的所有模式。
FP-Tree算法
我们举个例子来详细讲解FP-Tree算法的完整实现。
事务数据库如下,一行表示一条购物记录:
牛奶,鸡蛋,面包,薯片
鸡蛋,爆米花,薯片,啤酒
鸡蛋,面包,薯片
牛奶,鸡蛋,面包,爆米花,薯片,啤酒
牛奶,面包,啤酒
鸡蛋,面包,啤酒
牛奶,面包,薯片
牛奶,鸡蛋,面包,黄油,薯片
牛奶,鸡蛋,黄油,薯片
我们的目的是要找出哪些商品总是相伴出现的,比如人们买薯片的时候通常也会买鸡蛋,则[薯片,鸡蛋]就是一条频繁模式(frequent pattern)。
FP-Tree算法第一步:扫描事务数据库,每项商品按频数递减排序,并删除频数小于最小支持度MinSup的商品。(第一次扫描数据库)
薯片:7鸡蛋:7面包:7牛奶:6啤酒:4 (这里我们令MinSup=3)
以上结果就是频繁1项集,记为F1。
第二步:对于每一条购买记录,按照F1中的顺序重新排序。(第二次也是最后一次扫描数据库)
薯片,鸡蛋,面包,牛奶
薯片,鸡蛋,啤酒
薯片,鸡蛋,面包
薯片,鸡蛋,面包,牛奶,啤酒
面包,牛奶,啤酒
鸡蛋,面包,啤酒
薯片,面包,牛奶
薯片,鸡蛋,面包,牛奶
薯片,鸡蛋,牛奶
第三步:把第二步得到的各条记录插入到FP-Tree中。刚开始时后缀模式为空。
插入每一条(薯片,鸡蛋,面包,牛奶)之后
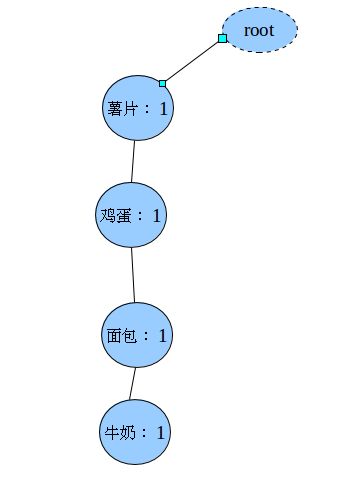
插入第二条记录(薯片,鸡蛋,啤酒)
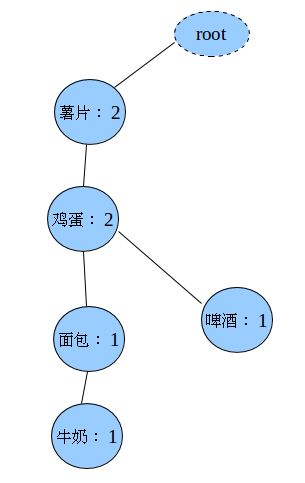
插入第三条记录(面包,牛奶,啤酒)
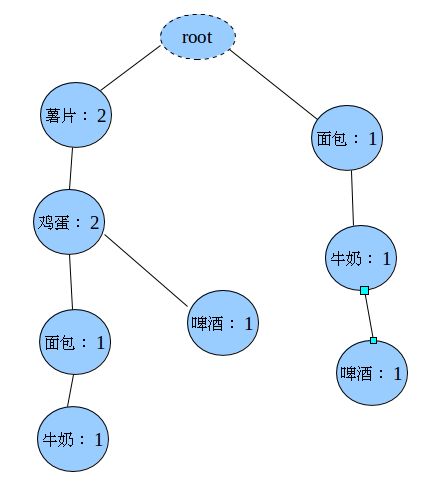
估计你也知道怎么插了,最终生成的FP-Tree是:
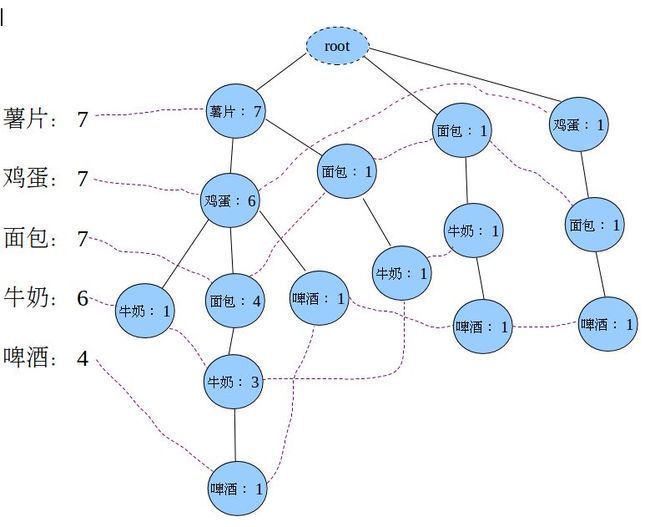
上图中左边的那一叫做表头项,树中相同名称的节点要链接起来,链表的第一个元素就是表头项里的元素。
如果FP-Tree为空(只含一个虚的root节点),则FP-Growth函数返回。
此时输出表头项的每一项+postModel,支持度为表头项中对应项的计数。
第四步:从FP-Tree中找出频繁项。
遍历表头项中的每一项(我们拿“牛奶:6”为例),对于各项都执行以下(1)到(5)的操作:
(1)从FP-Tree中找到所有的“牛奶”节点,向上遍历它的祖先节点,得到4条路径:
薯片:7,鸡蛋:6,牛奶:1 薯片:7,鸡蛋:6,面包:4,牛奶:3 薯片:7,面包:1,牛奶:1 面包:1,牛奶:1
对于每一条路径上的节点,其count都设置为牛奶的count
薯片:1,鸡蛋:1,牛奶:1 薯片:3,鸡蛋:3,面包:3,牛奶:3 薯片:1,面包:1,牛奶:1 面包:1,牛奶:1
因为每一项末尾都是牛奶,可以把牛奶去掉,得到条件模式基(Conditional Pattern Base,CPB),此时的后缀模式是:(牛奶)。
薯片:1,鸡蛋:1 薯片:3,鸡蛋:3,面包:3 薯片:1,面包:1 面包:1
(2)我们把上面的结果当作原始的事务数据库,返回到第3步,递归迭代运行。
没讲清楚,你可以参考这篇博客,直接看核心代码吧:
public void FPGrowth(List<List<String>> transRecords, List<String> postPattern,Context context) throws IOException, InterruptedException { // 构建项头表,同时也是频繁1项集 ArrayList<TreeNode> HeaderTable = buildHeaderTable(transRecords); // 构建FP-Tree TreeNode treeRoot = buildFPTree(transRecords, HeaderTable); // 如果FP-Tree为空则返回 if (treeRoot.getChildren()==null || treeRoot.getChildren().size() == 0) return; //输出项头表的每一项+postPattern if(postPattern!=null){ for (TreeNode header : HeaderTable) { String outStr=header.getName(); int count=header.getCount(); for (String ele : postPattern) outStr+="\t" + ele; context.write(new IntWritable(count), new Text(outStr)); } } // 找到项头表的每一项的条件模式基,进入递归迭代 for (TreeNode header : HeaderTable) { // 后缀模式增加一项 List<String> newPostPattern = new LinkedList<String>(); newPostPattern.add(header.getName()); if (postPattern != null) newPostPattern.addAll(postPattern); // 寻找header的条件模式基CPB,放入newTransRecords中 List<List<String>> newTransRecords = new LinkedList<List<String>>(); TreeNode backnode = header.getNextHomonym(); while (backnode != null) { int counter = backnode.getCount(); List<String> prenodes = new ArrayList<String>(); TreeNode parent = backnode; // 遍历backnode的祖先节点,放到prenodes中 while ((parent = parent.getParent()).getName() != null) { prenodes.add(parent.getName()); } while (counter-- > 0) { newTransRecords.add(prenodes); } backnode = backnode.getNextHomonym(); } // 递归迭代 FPGrowth(newTransRecords, newPostPattern,context); } }
对于FP-Tree已经是单枝的情况,就没有必要再递归调用FPGrowth了,直接输出整条路径上所有节点的各种组合+postModel就可了。例如当FP-Tree为:
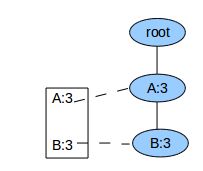
我们直接输出:
3 A+postModel
3 B+postModel
3 A+B+postModel
就可以了。
如何按照上面代码里的做法,是先输出:
3 A+postModel
3 B+postModel
然后把B插入到postModel的头部,重新建立一个FP-Tree,这时Tree中只含A,于是输出
3 A+(B+postModel)
两种方法结果是一样的,但毕竟重新建立FP-Tree计算量大些。
Java实现
FP树节点定义
挖掘频繁模式
输入文件
牛奶,鸡蛋,面包,薯片
鸡蛋,爆米花,薯片,啤酒
鸡蛋,面包,薯片
牛奶,鸡蛋,面包,爆米花,薯片,啤酒
牛奶,面包,啤酒
鸡蛋,面包,啤酒
牛奶,面包,薯片
牛奶,鸡蛋,面包,黄油,薯片
牛奶,鸡蛋,黄油,薯片
输出
6 薯片 鸡蛋 5 薯片 面包 5 鸡蛋 面包 4 薯片 鸡蛋 面包 5 薯片 牛奶 5 面包 牛奶 4 鸡蛋 牛奶 4 薯片 面包 牛奶 4 薯片 鸡蛋 牛奶 3 面包 鸡蛋 牛奶 3 薯片 面包 鸡蛋 牛奶 3 鸡蛋 啤酒 3 面包 啤酒
用Hadoop来实现
在上面的代码我们把整个事务数据库放在一个List<List<String>>里面传给FPGrowth,在实际中这是不可取的,因为内存不可能容下整个事务数据库,我们可能需要从关系关系数据库中一条一条地读入来建立FP-Tree。但无论如何FP-Tree是肯定需要放在内存中的,但内存如果容不下怎么办?另外FPGrowth仍然是非常耗时的,你想提高速度怎么办?解决办法:分而治之,并行计算。
我们把原始事务数据库分成N部分,在N个节点上并行地进行FPGrowth挖掘,最后把关联规则汇总到一起就可以了。关键问题是怎么“划分”才会不遗露任何一条关联规则呢?参见这篇博客。这里为了达到并行计算的目的,采用了一种“冗余”的划分方法,即各部分的并集大于原来的集合。这种方法最终求出来的关联规则也是有冗余的,比如在节点1上得到一条规则(6:啤酒,尿布),在节点2上得到一条规则(3:尿布,啤酒),显然节点2上的这条规则是冗余的,需要采用后续步骤把冗余的规则去掉。
代码:
Record.java
DC_FPTree.java
结束语
在实践中,关联规则挖掘可能并不像人们期望的那么有用。一方面是因为支持度置信度框架会产生过多的规则,并不是每一个规则都是有用的。另一方面大部分的关联规则并不像“啤酒与尿布”这种经典故事这么普遍。关联规则分析是需要技巧的,有时需要用更严格的统计学知识来控制规则的增殖。