MapReduce Features
Counters
Built-in Counters
这些counters你在Web UI中,或是job结束后在控制台生成的统计报告中都看得到,根据名字你也能猜到这些counter是什么意思。分为3个Group:
- Map-Reduce Frameword
Map input records,Map skipped records,Map input bytes,Map output records,Map output bytes,Combine input records,Combine output records,Reduce input records,Reduce input groups,Reduce output records,Reduce skipped groups,Reduce skipped records,Spilled records - File Systems
FileSystem bytes read,FileSystem bytes written - Job Counters
Launched map tasks,Launched reduce tasks,Failed map tasks,Failed reduce tasks,Data-local map tasks,Rack-local map tasks,Other local map tasks
counters是由task产生并不断更新的,它们被传递给task tracker,最后传递给job trakcer,并在job tracker那里得到聚合汇总。
使用Java Enum自定义Counter
一个Counter可以是任意的Enum类型。比如有个文件每行记录了一个温度,我们想分别统计高温(>30度)和低温(<0度)的记录各有多少,可以使用下面的代码。最后的计数结果会显示在终端上。
enum Temperature{ HIGH, LOW } public static class MyMapper extends Mapper<LongWritable, Text, NullWritable, Text> { private Counter counter1,counter2; @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{ double temperature=Double.parseDouble(value.toString()); if(temperature<0){ counter2=context.getCounter(Temperature.HIGH); //get时如果不存在就会自动添加 counter2.increment(1); }else if(temperature>30){ counter1=context.getCounter(Temperature.LOW); counter1.increment(1); } context.write(NullWritable.get(), value); } }
Counter和CounterGroup都是Counters的内部类,Temperature.HIGH和Temperature.LOW就属于一个Group。
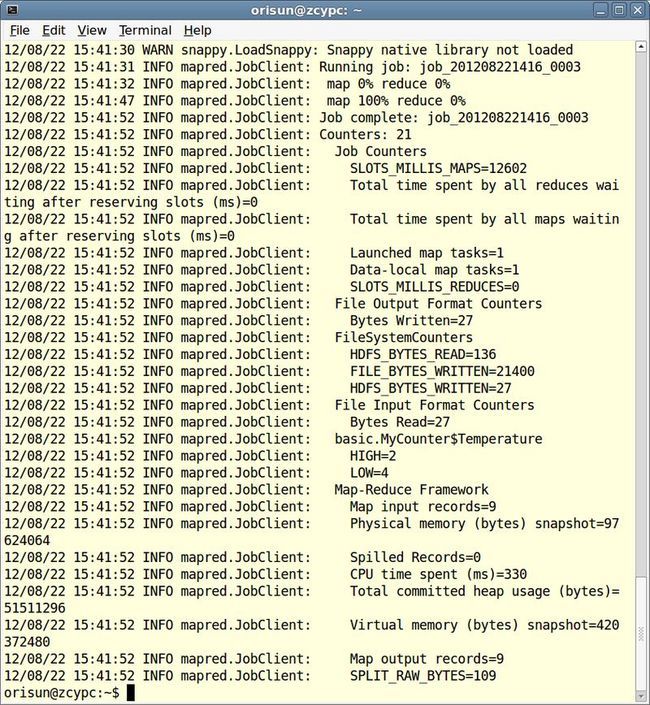
注意有这么几行:
12/08/22 15:41:52 INFO mapred.JobClient: basic.MyCounter$Temperature
12/08/22 15:41:52 INFO mapred.JobClient: HIGH=2
12/08/22 15:41:52 INFO mapred.JobClient: LOW=4
通过Context来getCounter有两种形式:
Counter getCounter(Enum<?> counterName) //上面代码用的就是这种形式 Counter getCounter(String groupName,String counterName) //比如: counter2=context.getCounter("basic.MyCounter$Temperature","HIGH"); //获取Counter的值 long count=counter2.getValue();
Sort
考虑一个排序问题,原始数列为{1,11,2,12,3,13,14,15}。
方法一:采用1个Reducer,其输出就是按key排序好的。但这样你放弃了Hadoop的并行性。
方法二:自定义Partitioner,把1-10分一个Reducer,把11-20分给另一个Reducer,最后把两个reducer的输出连接起来就得到全局的排序。这样做有2个弊端:你需要知道全体数列分布在什么区间上;把整个区间等距的切分为N份,每份上的数据量可能并不均匀,导致Reducer上负载不均衡。
方法三:
1 public class Sampling extends Configured implements Tool { 2 3 @Override 4 public int run(String[] arg0) throws Exception { 5 Job job = new Job(); 6 job.setJarByClass(getClass()); 7 Configuration conf = getConf(); 8 FileSystem fs = FileSystem.get(conf); 9 10 FileInputFormat.addInputPaths(job, "input/rdata.seq"); 11 Path outDir = new Path("output"); 12 fs.delete(outDir, true); 13 FileOutputFormat.setOutputPath(job, outDir); 14 15 job.setPartitionerClass(TotalOrderPartitioner.class); 16 17 InputSampler.Sampler<LongWritable, Text> sampler = new InputSampler.RandomSampler<LongWritable, Text>(0.5, 1); 18 InputSampler.writePartitionFile(job, sampler); 19 20 job.setNumReduceTasks(2); 21 job.setInputFormatClass(SequenceFileInputFormat.class); 22 job.setOutputKeyClass(LongWritable.class); 23 job.setOutputValueClass(Text.class); 24 25 return job.waitForCompletion(true) ? 0 : 1; 26 } 27 28 public static void main(String[] args) throws Exception { 29 int res = ToolRunner.run(new Configuration(), new Sampling(), args); 30 System.exit(res); 31 } 32 33 }
15行:首先我们设置使用的Partitioner为TotalOrderPartitioner(默认的Partitioner为HashPartitioner,TotalOrderPartitioner也是Hadoop内部定义好的一个Partitioner)。TotalOrderPartitioner工作时需要有一个指导文件,姑且称之为partition文件(默认情况下为根目录下的“_partition.lst"文件,可以通过TotalOrderPartitioner的静态方法setPartitionFile(Configuration conf, Path p) 来改变默认配置),这是一个二进制文件。通常partition文件要放到DistributedCacheFile中(并且软链接到“_partition.lst"),提高读取效率。DistributedCacheFile下文会详细介绍。
17行:InputSampler工作在客户端向JobTracker提交作业请求之前,计算出InputSplit之后,其作用就是抽取原始输入数据的一个小样本。抽取样本的方式有3种:IntervalSampler,RandomSampler,SplitSampler。如果采用RandomSampler则样本的分布与总体的分布是接近的。代码中我们设置每个数据被抽到的概率为0.5,理想情况下可以认为小样本集合为{1,12,3,14}。
18行:把小样本写入partition文件。由于之前已经指定了是TotalOrderPartitioner(顾名思义),所以在写入partition文件之前小样本要先经过排序,即此时_partition.lst文件内容为{1,3,12,14}。
20行:设置Reducer数目为2。根据指导文件,TotalOrderPartitioner会把小于12的分给一个Reducer,把>=12的分给第2个Reducer。
注意:一定要在调用InputSampler.writePartitionFile()之前setPartitioner。
当然_partition.lst文件中存放的肯定不是{1,3,12,14}这么简单的几个数,而是存放了一棵B索引树。
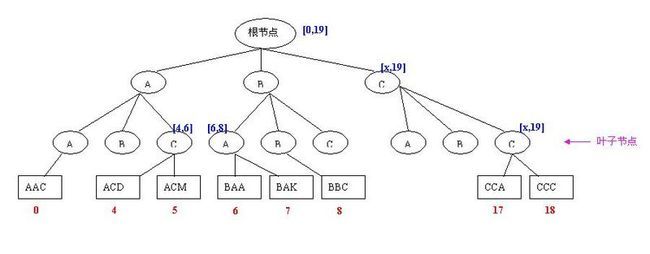
SplitSampler、RandomSampler和IntervalSampler都是InputSampler的静态内部类,它们都实现了InputSampler的内部接口Sampler接口。
public interface Sampler<K,V>{ K[] getSample(InputFormat<K,V> inf,JobConf job) throws IOException; }
RandomSampler有两种构造函数:
InputSampler.RandomSampler(double freq, int numSamples) InputSampler.RandomSampler(double freq, int numSamples, int maxSplitsSampled)
freq:一个Key被选中的概率
numSamples:从所有被选中的split(不设置maxSplitsSampled参数时,所有split都被选中)中获得的总共的样本数目,最终获得的样本数目可能会比numSamples小,因为在达到numSamples之前split已经扫描完毕。
maxSplitsSampled:需要检查扫描的最大split数目,当总共的inputsplit数目还没有maxSplitsSampled这么多时,以实际的split数目为准。
IntervalSampler根据一定的间隔采样数据,非常适合对排好序的数据采样。
SplitSampler简单地从总体中采集前n个样本。
SplitSampler是最简单的取样器,运行最快;RandomSampler是最复杂的,最耗时。
Join
在实际工作中根据外键连接两张关系表的时候,你可能会使用Pig、Hive或Cascading,因为这样会更简捷省事,事实上Join也是他们的核心操作。当然使用最基本的MapReduce也可以实现Join。
1,Stewen,555-555-555 2,Edward,123-456-789 3,Jose,45-675-1432 4,David,5432-654-34
A,3,12.97,02-June-2008 B,1,88.25,20-May-2009 C,2,32.00,30-Nov-2007 D,3,25.02,22-Jan-2009
CompositeInputFormat
既然是一种InputFormat,说明它是在map之前进行的。
static String compose(Class<? extends InputFormat> inf, String path) static String compose(String op, Class<? extends InputFormat> inf, Path... path)
参数op表示进行连接的类型:外连接还是内连接。paths是数据源文件,这是一个String数组或Path数组。另外还是指定用哪种InputFormat来读取这些数据源文件--这要求所有的数据源文件可以用同一种方式来解析key和value,甩以我们需要把上面的order文件变一变:把顾客ID提到第1列。
首先定义自己的InputFormat来解析数据源文件中的key-value(新版本的Hadoop中已经没有了KeyValueInputFormat这个类)。在driver中使用如下代码:
String customerFie ="input/customer"; String orderFile ="input/order"; conf.set("mapred.join.expr", CompositeInputFormat.compose("outer",MyKeyValueInputFormat.class, new String[]{customerFie, orderFile}));
则Mapper接收到的就是经过外连接之后的record。
不过遗憾的是在Hadoop1.03中CompositeInputFormat已经被弃用了(Hadoop1.03弃用了很多方便的特性,真不知道他们是怎么搞的)。
Reducer侧联结
有两个文件,customer文件记录着:客户ID、姓名、电话,order文件记录着:交易ID、客户ID、交易金额、交易日期。现用客户ID作为外键连接两个表。
思路:扫描2个数据源文件(需要使用MultipleInputs),对于每条记录需要Emit三个值:客户ID、表名称、剩余信息。具有相同客户ID的被送往一个Reducer,根据表名称不同又分为两组,这两组作笛卡尔积就可以了。
KeyTagPair.java
1 package join; 2 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.io.WritableComparable; 10 11 public class KeyTagPair implements WritableComparable<KeyTagPair> { 12 private IntWritable key; //联结用的外键 13 private Text tag; //用tag标记数据来源 14 15 public KeyTagPair() { 16 set(new IntWritable(), new Text()); 17 } 18 19 public KeyTagPair(int key, String tag) { 20 set(new IntWritable(key), new Text(tag)); 21 } 22 23 public KeyTagPair(IntWritable key, Text tag) { 24 set(key, tag); 25 } 26 27 public void set(IntWritable key, Text tag) { 28 this.key = key; 29 this.tag = tag; 30 } 31 32 public IntWritable getKey() { 33 return key; 34 } 35 36 public Text getTag() { 37 return tag; 38 } 39 40 @Override 41 public void write(DataOutput out) throws IOException { 42 key.write(out); 43 tag.write(out); 44 } 45 46 @Override 47 public void readFields(DataInput in) throws IOException { 48 key.readFields(in); 49 tag.readFields(in); 50 } 51 52 @Override 53 public int hashCode() { 54 return key.hashCode() * 163; //仅对key散列,key相同的到一个reducer里面去 55 } 56 57 @Override 58 public boolean equals(Object o) { 59 if (o instanceof KeyTagPair) { 60 KeyTagPair tp = (KeyTagPair) o; 61 return key.equals(tp.key) && tag.equals(tp.tag); 62 } 63 return false; 64 } 65 66 @Override 67 public String toString() { 68 return key + "\t" + tag; 69 } 70 71 @Override 72 public int compareTo(KeyTagPair tp) { 73 int cmp = key.compareTo(tp.key); //先按key排序 74 if (cmp != 0) { 75 return cmp; 76 } 77 return tag.compareTo(tp.tag); 78 } 79 }
注意61行,在Java中对于非基本数据类型,在比较是否相等时用equal而非==。用equal是调用对象的equal方法进行比较,而用==表示在比较两个对象是否为同一个对象。
ReducerSideJoin.java
1 package join; 2 3 import java.io.IOException; 4 import java.util.LinkedList; 5 import java.util.List; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.conf.Configured; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.LongWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.Mapper; 16 import org.apache.hadoop.mapreduce.Reducer; 17 import org.apache.hadoop.mapreduce.lib.input.MultipleInputs; 18 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 19 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 20 import org.apache.hadoop.util.Tool; 21 import org.apache.hadoop.util.ToolRunner; 22 23 public class ReducerSideJoin extends Configured implements Tool{ 24 25 public static class CustomerMap extends Mapper<LongWritable,Text,KeyTagPair,Text>{ 26 @Override 27 public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ 28 String[] arr=value.toString().split(",",2); 29 int id=Integer.parseInt(arr[0]); 30 KeyTagPair pair=new KeyTagPair(id,"customer"); 31 context.write(pair, new Text(arr[1])); 32 } 33 } 34 35 public static class OrderMap extends Mapper<LongWritable,Text,KeyTagPair,Text>{ 36 @Override 37 public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ 38 String[] arr=value.toString().split(",",3); 39 int id=Integer.parseInt(arr[1]); 40 KeyTagPair pair=new KeyTagPair(id,"order"); 41 context.write(pair, new Text(arr[0]+","+arr[2])); 42 } 43 } 44 45 public static class JoinReduce extends Reducer<KeyTagPair,Text,IntWritable,Text>{ 46 IntWritable prevKey=new IntWritable(-1); 47 List<Text> prevList=new LinkedList<Text>(); 48 49 @Override 50 public void reduce(KeyTagPair key,Iterable<Text> values,Context context)throws IOException,InterruptedException{ 51 IntWritable currKey=key.getKey(); 52 if(currKey.get()!=prevKey.get()){ 53 prevKey.set(currKey.get()); 54 prevList.clear(); 55 for(Text value:values){ 56 prevList.add(new Text(value)); 57 } 58 } 59 else{ 60 for(Text value:values){ 61 for(Text item:prevList){ 62 context.write(currKey, new Text(item+","+value)); 63 } 64 } 65 } 66 } 67 } 68 69 @Override 70 public int run(String[] arg0) throws Exception { 71 Job job = new Job(); 72 job.setJarByClass(getClass()); 73 Configuration conf=getConf(); 74 FileSystem fs=FileSystem.get(conf); 75 76 Path customerPath=new Path("input/customer"); 77 Path orderPath=new Path("input/order"); 78 MultipleInputs.addInputPath(job, customerPath, TextInputFormat.class,CustomerMap.class); 79 MultipleInputs.addInputPath(job, orderPath, TextInputFormat.class,OrderMap.class); 80 Path outDir=new Path("output"); 81 fs.delete(outDir, true); 82 FileOutputFormat.setOutputPath(job, outDir); 83 84 job.setReducerClass(JoinReduce.class); 85 job.setMapOutputKeyClass(KeyTagPair.class); 86 job.setOutputValueClass(Text.class); 87 job.setOutputKeyClass(IntWritable.class); 88 job.setOutputValueClass(Text.class); 89 90 return job.waitForCompletion(true)?0:1; 91 } 92 93 public static void main(String[] args) throws Exception { 94 Configuration conf=new Configuration(); 95 int res = ToolRunner.run(conf, new ReducerSideJoin(), args); 96 System.exit(res); 97 } 98 }
注意第53行没有直接把currKey赋给prevKey,第56行也没有把value直接添加到prevList中去,因为Java中对于非基本数据类型使用的都是引用传值,currKey和value都只在本次reduce函数中有效,而prevKey和prevList是全局的,拿局部的引用变量给全局的引用变量赋值时要做一次深拷贝。
Mapper侧联结
Reducer侧联结非常灵活,但效率可能很低。直到Reduce阶段才做连接。之前所有数据要在网络上重排,然后请多情况下连接过程中大部分数据又被丢弃。如果在map阶段就去除不必要的数据,则联结更有效率。
当有一个数据源很小,可以装入内存时,我们就在mapper阶段用一个HashTable来存储它。进行外连接。
DistributedCache
Hadoop的分布式缓存机制使得一个job中的所有mapper和reducer可以访问同一个文件。任务提交后,hadoop将由-file和-archive选项指定的文件复制到共享文件系统中。DistributedCacheFile是只读的,任务运行前,TaskTracker从共享文件系统中把DistributedCahcheFile复制到本地磁盘作为缓存,这是单向的复制,是不能写回的。试想在分布式环境下,如果不同的mapper和reducer可以把缓存文件写回的话,那岂不又需要一套复杂的文件共享机制,严重地影响hadoop执行效率。
DistributedCache还有一个特点,它更适合于“大文件”(各节点内存容不下)缓存在本地。
在使用ToolRunner运行作业之前,把文件提到DistributedCache中去:
Path dataFile1=new Path("/user/orisun/input/data1"); Path dataFile2=new Path("/user/orisun/input/data2"); DistributedCache.addCacheFile(dataFile1.toUri(), conf); DistributedCache.addCacheFile(dataFile2.toUri(), conf);
然后在Mapper或Reducer中就可以使用标准的Java文件I/O技术读取本地副本。
Path []caches=DistributedCache.getLocalCacheFiles(context.getConfiguration()); if(caches!=null || caches.length>0){ BufferedReader br=new BufferedReader(new FileReader(caches[0].toString())); String line; while((line=br.readLine())!=null){ //…… } br.close(); }
还可以给缓存文件创建本地的符号链接。
Path dataFile=new Path("/user/orisun/input/data"); URI partitionUri = new URI(dataFile.toString() + "#alias"); //alias就是链接文件的名称 DistributedCache.addCacheFile(partitionUri, conf); DistributedCache.createSymlink(conf);
然后在Mapper或Reducer中就可以使用标准的Java文件I/O技术读取”alias"文件了。
File file=new File("alias"); FileInputStream fis=new FileInputStream(file); InputStreamReader isr=new InputStreamReader(fis); BufferedReader br=new BufferedReader(isr); while(br.readLine())